Unified Understanding: This AI Method Supplies a Higher 3D Mapping for Robots
Creating robots that might do every day duties for us is a long-lasting dream of humanity. We wish them to stroll round and assist us with every day chores, enhance the manufacturing in factories, enhance the end result of our agriculture, and so forth. Robots are the assistants we’ve at all times needed to have.
The event of clever robots that may navigate and work together with objects in the actual world requires correct 3D mapping of the setting. With out them with the ability to perceive their surrounding setting correctly, it could not be doable to name them true assistants.
There have been many approaches to instructing robots about their environment. Although, most of those approaches are restricted to closed-set settings, that means they will solely purpose a couple of finite set of ideas which might be predefined throughout coaching.
Then again, we’ve got new developments within the AI area that might “perceive” ideas in comparatively open-end datasets. For instance, CLIP can be utilized to caption and clarify pictures that had been by no means seen through the coaching set, and it produces dependable outcomes. Or take DINO, for instance; it may perceive and draw boundaries round objects it hasn’t seen earlier than. We have to discover a technique to convey this means to robots in order that we will say they will truly perceive their setting really.
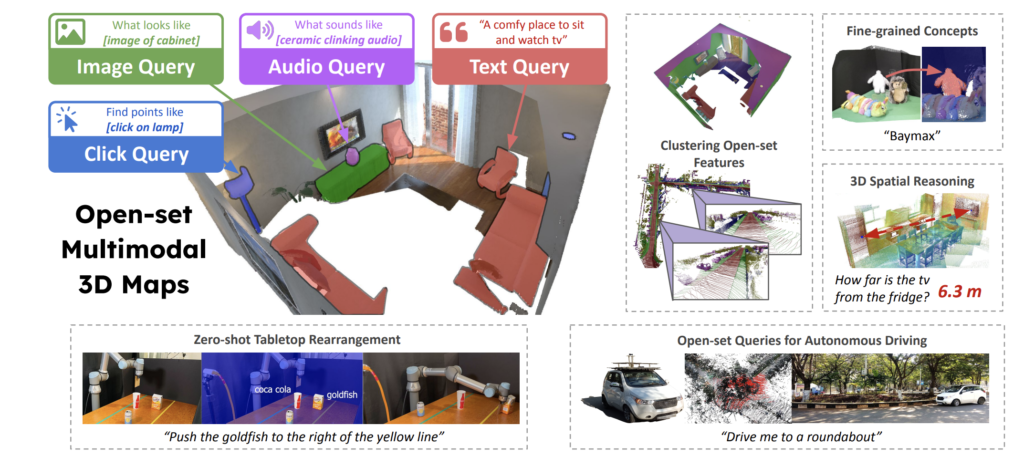
What does it require to know and mannequin the setting? If we wish our robotic to have broad applicability in a variety of duties, it ought to have the ability to use its setting modeling with out the necessity for retraining for every new activity. The modeling they do ought to have two principal properties; being open-set and multimodal.
Open-set modeling means they will seize all kinds of ideas in nice element. For instance, if we ask the robotic to convey us a can of soda, it ought to perceive it as “one thing to drink” and will have the ability to affiliate it with a selected model, taste, and so forth. Then we’ve got the multimodality. This implies the robotic ought to have the ability to use multiple “sense.” It ought to perceive textual content, picture, audio, and so forth., all collectively.
Let’s meet with ConceptFusion, an answer to sort out the aforementioned limitations.
ConceptFusion is a type of scene illustration that’s open-set and inherently multi-modal. It permits for reasoning past a closed set of ideas and permits a various vary of doable queries to the 3D setting. As soon as it really works, the robotic can use language, pictures, audio, and even 3D geometry based mostly reasoning with the setting.
ConceptFusion makes use of the development in large-scale fashions in language, picture, and audio domains. It really works on a easy remark; pixel-aligned open-set options may be fused into 3D maps by way of conventional Simultaneous Localization and Mapping (SLAM) and multiview fusion approaches. This allows efficient zero-shot reasoning and doesn’t require any further fine-tuning or coaching.
Enter pictures are processed to generate generic object masks that don’t belong to any specific class. Native options are then extracted for every object, and a world characteristic is computed for the whole enter picture. Our zero-shot pixel alignment approach is used to mix the region-specific options with the worldwide characteristic, leading to pixel-aligned options.
ConceptFusion is evaluated on a combination of real-world and simulated eventualities. It might probably retain long-tailed ideas higher than supervised approaches and outperform current SoTA strategies by greater than 40%.
General, ConceptFusion is an progressive resolution to the constraints of current 3D mapping approaches. By introducing an open-set and multi-modal scene illustration, ConceptFusion permits extra versatile and efficient reasoning concerning the setting with out the necessity for added coaching or fine-tuning.
Take a look at the Paper and Project. All Credit score For This Analysis Goes To the Researchers on This Mission. Additionally, don’t neglect to affix our 16k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra.
Ekrem Çetinkaya obtained his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin College, Istanbul, Türkiye. He wrote his M.Sc. thesis about picture denoising utilizing deep convolutional networks. He’s at the moment pursuing a Ph.D. diploma on the College of Klagenfurt, Austria, and dealing as a researcher on the ATHENA venture. His analysis pursuits embody deep studying, laptop imaginative and prescient, and multimedia networking.





