Improve picture search experiences with Amazon Personalize, Amazon OpenSearch Service, and Amazon Titan Multimodal Embeddings in Amazon Bedrock
Quite a lot of completely different methods have been used for returning photos related to look queries. Traditionally, the thought of making a joint embedding area to facilitate picture captioning or text-to-image search has been of curiosity to machine studying (ML) practitioners and companies for fairly some time. Contrastive Language–Image Pre-training (CLIP) and Bootstrapping Language-Image Pre-training (BLIP) have been the primary two open supply fashions that achieved near-human outcomes on the duty. Extra lately, nevertheless, there was a development to make use of the identical methods used to coach highly effective generative fashions to create multimodal fashions that map textual content and pictures to the identical embedding area to attain state-of-the-art outcomes.
On this put up, we present find out how to use Amazon Personalize together with Amazon OpenSearch Service and Amazon Titan Multimodal Embeddings from Amazon Bedrock to reinforce a consumer’s picture search expertise through the use of realized consumer preferences to additional personalize picture searches in accordance with a consumer’s particular person type.
Answer overview
Multimodal fashions are being utilized in text-to-image searches throughout quite a lot of industries. Nevertheless, one space the place these fashions fall quick is in incorporating particular person consumer preferences into their responses. A consumer trying to find photos of a chook, for instance, might have many various desired outcomes.
In an excellent world, we will be taught a consumer’s preferences from their earlier interactions with photos they both seen, favorited, or downloaded, and use that to return contextually related photos according to their latest interactions and elegance preferences.
Implementing the proposed answer contains the next high-level steps:
- Create embeddings on your photos.
- Retailer embeddings in an information retailer.
- Create a cluster for the embeddings.
- Replace the picture interactions dataset with the picture cluster.
- Create an Amazon Personalize personalised rating answer.
- Serve consumer search requests.
Conditions
To implement the proposed answer, it is best to have the next:
- An AWS account and familiarity with Amazon Personalize, Amazon SageMaker, OpenSearch Service, and Amazon Bedrock.
- The Amazon Titan Multimodal Embeddings mannequin enabled in Amazon Bedrock. You possibly can verify it’s enabled on the Mannequin entry web page of the Amazon Bedrock console. If Amazon Titan Multimodal Embeddings is enabled, the entry standing will present as Entry granted, as proven within the following screenshot. You possibly can allow entry to the mannequin by selecting Handle mannequin entry, deciding on Amazon Titan Multimodal Embeddings G1, after which selecting Save Adjustments.

Create embeddings on your photos
Embeddings are a mathematical illustration of a bit of knowledge similar to a textual content or a picture. Particularly, they’re a vector or ordered listing of numbers. This illustration helps seize the that means of the picture or textual content in such a manner that you should use it to find out how related photos or textual content are to one another by taking their distance from one another within the embedding area.
 |
→ [-0.020802604, -0.009943095, 0.0012887075, -0…. |
As a first step, you can use the Amazon Titan Multimodal Embeddings model to generate embeddings for your images. With the Amazon Titan Multimodal Embeddings model, we can use an actual bird image or text like “bird” as an input to generate an embedding. Furthermore, these embeddings will be close to each other when the distance is measured by an appropriate distance metric in a vector database.
The following code snippet shows how to generate embeddings for an image or a piece of text using Amazon Titan Multimodal Embeddings:
It’s anticipated that the picture is base64 encoded as a way to create an embedding. For extra info, see Amazon Titan Multimodal Embeddings G1. You possibly can create this encoded model of your picture for a lot of picture file varieties as follows:
On this case, input_image might be straight fed to the embedding operate you generated.
Create a cluster for the embeddings
On account of the earlier step, a vector illustration for every picture has been created by the Amazon Titan Multimodal Embeddings mannequin. As a result of the aim is to create extra personalize picture search influenced by the consumer’s earlier interactions, you create a cluster out of the picture embeddings to group related photos collectively. That is helpful as a result of will pressure the downstream re-ranker, on this case an Amazon Personalize personalised rating mannequin, to be taught consumer presences for particular picture types versus their desire for particular person photos.
On this put up, to create our picture clusters, we use an algorithm made accessible by means of the absolutely managed ML service SageMaker, particularly the K-Means clustering algorithm. You should use any clustering algorithm that you’re conversant in. Ok-Means clustering is a extensively used technique for clustering the place the purpose is to partition a set of objects into Ok clusters in such a manner that the sum of the squared distances between the objects and their assigned cluster imply is minimized. The suitable worth of Ok will depend on the info construction and the issue being solved. Make sure that to decide on the fitting worth of Ok, as a result of a small worth may end up in under-clustered information, and a big worth may cause over-clustering.
The next code snippet is an instance of find out how to create and practice a Ok-Means cluster for picture embeddings. On this instance, the selection of 100 clusters is bigoted—it is best to experiment to discover a quantity that’s greatest on your use case. The occasion kind represents the Amazon Elastic Compute Cloud (Amazon EC2) compute occasion that runs the SageMaker Ok-Means coaching job. For detailed info on which occasion varieties suit your use case, and their efficiency capabilities, see Amazon Elastic Compute Cloud instance types. For details about pricing for these occasion varieties, see Amazon EC2 Pricing. For details about accessible SageMaker pocket book occasion varieties, see CreateNotebookInstance.
For many experimentation, it is best to use an ml.t3.medium occasion. That is the default occasion kind for CPU-based SageMaker photos, and is accessible as a part of the AWS Free Tier.
Retailer embeddings and their clusters in an information retailer
On account of the earlier step, a vector illustration for every picture has been created and assigned to a picture cluster by our clustering mannequin. Now, you want to retailer this vector such that the opposite vectors which might be nearest to it may be returned in a well timed method. This lets you enter a textual content similar to “chook” and retrieve photos that prominently function birds.
Vector databases present the flexibility to retailer and retrieve vectors as high-dimensional factors. They add further capabilities for environment friendly and quick lookup of nearest neighbors within the N-dimensional area. They’re sometimes powered by nearest neighbor indexes and constructed with algorithms just like the Hierarchical Navigable Small World (HNSW) and Inverted File Index (IVF) algorithms. Vector databases present further capabilities like information administration, fault tolerance, authentication and entry management, and a question engine.
AWS gives many companies on your vector database necessities. OpenSearch Service is one instance; it makes it easy so that you can carry out interactive log analytics, real-time utility monitoring, web site search, and extra. For details about utilizing OpenSearch Service as a vector database, see k-Nearest Neighbor (k-NN) search in OpenSearch Service.
For this put up, we use OpenSearch Service as a vector database to retailer the embeddings. To do that, you want to create an OpenSearch Service cluster or use OpenSearch Serverless. Regardless which method you used for the cluster, you want to create a vector index. Indexing is the strategy by which engines like google set up information for quick retrieval. To make use of a k-NN vector index for OpenSearch Service, you want to add the index.knn setting and add a number of fields of the knn_vector information kind. This allows you to seek for factors in a vector area and discover the closest neighbors for these factors by Euclidean distance or cosine similarity, both of which is appropriate for Amazon Titan Multimodal Embeddings.
The next code snippet exhibits find out how to create an OpenSearch Service index with k-NN enabled to function a vector datastore on your embeddings:
The next code snippet exhibits find out how to retailer a picture embedding into the open search service index you simply created:
Replace the picture interactions dataset with the picture cluster
When creating an Amazon Personalize re-ranker, the item interactions dataset represents the consumer interplay historical past together with your gadgets. Right here, the photographs characterize the gadgets and the interactions might encompass quite a lot of occasions, similar to a consumer downloading a picture, favoriting it, and even viewing the next decision model of it. For our use case, we practice our recommender on the picture clusters as a substitute of the person photos. This offers the mannequin the chance to advocate based mostly on the cluster-level interactions and perceive the consumer’s total stylistic preferences versus preferences for a person picture within the second.
To take action, replace the interplay dataset together with the picture cluster as a substitute of the picture ID within the dataset, and retailer the file in an Amazon Simple Storage Service (Amazon S3) bucket, at which level it may be introduced into Amazon Personalize.
Create an Amazon Personalize personalised rating marketing campaign
The Personalized-Ranking recipe generates personalised rankings of things. A personalised rating is an inventory of beneficial gadgets which might be re-ranked for a particular consumer. That is helpful when you have a group of ordered gadgets, similar to search outcomes, promotions, or curated lists, and also you need to present a personalised re-ranking for every of your customers. Consult with the next example accessible on GitHub for full step-by-step directions on find out how to create an Amazon Personalize recipe. The high-level steps are as follows:
- Create a dataset group.
- Prepare and import data.
- Create recommenders or custom resources.
- Get recommendations.
We create and deploy a personalised rating marketing campaign. First, you want to create a personalised rating answer. A answer is a mixture of a dataset group and a recipe, which is mainly a set of directions for Amazon Personalize to organize a mannequin to unravel a particular kind of enterprise use case. Then you definitely practice an answer model and deploy it as a marketing campaign.
The next code snippet exhibits find out how to create a Personalized-Ranking solution resource:
The next code snippet exhibits find out how to create a Personalized-Ranking solution version resource:
The next code snippet exhibits find out how to create a Personalized-Ranking campaign resource:
Serve consumer search requests
Now our answer circulate is able to serve a consumer search request and supply personalised ranked outcomes based mostly on the consumer’s earlier interactions. The search question will likely be processed as proven within the following diagram.

To setup personalised multimodal search, one would execute the next steps:
- Multimodal embeddings are created for the picture dataset.
- A clustering mannequin is created in SageMaker, and every picture is assigned to a cluster.
- The distinctive picture IDs are changed with cluster IDs within the picture interactions dataset.
- An Amazon Personalize personalised rating mannequin is educated on the cluster interplay dataset.
- Individually, the picture embeddings are added to an OpenSearch Service vector index.
The next workflow could be executed to course of a consumer’s question:
- Amazon API Gateway calls an AWS Lambda operate when the consumer enters a question.
- The Lambda operate calls the identical multimodal embedding operate to generate an embedding of the question.
- A k-NN search is carried out for the question embedding on the vector index.
- A personalised rating for the cluster ID for every retrieved picture is obtained from the Amazon Personalize personalised rating mannequin.
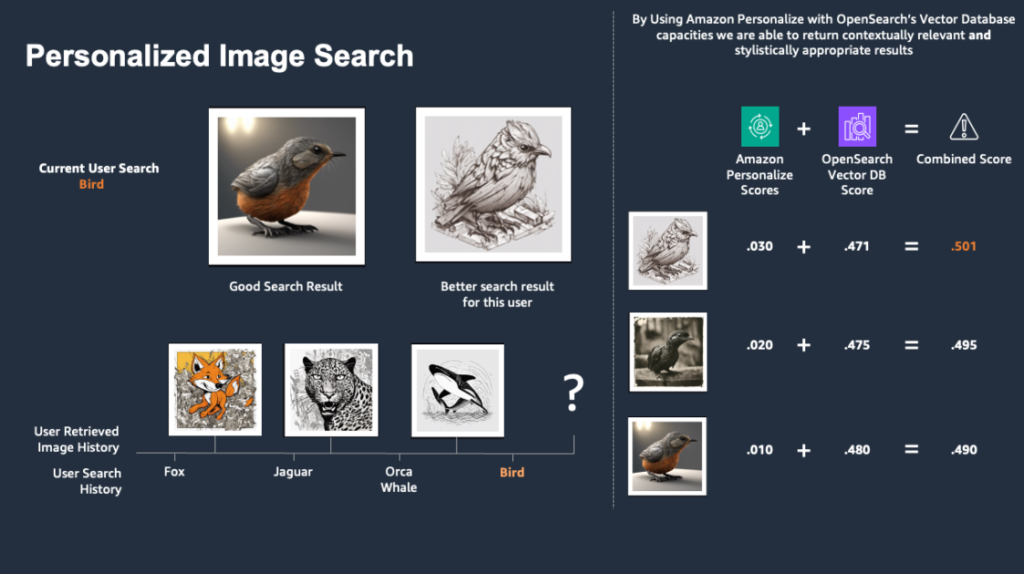
- The scores from OpenSearch Service and Amazon Personalize are mixed by means of a weighted imply. The photographs are re-ranked and returned to the consumer.
The weights on every rating may very well be tuned based mostly on the accessible information and desired outcomes and desired levels of personalization vs. contextual relevance.

To see what this appears to be like like in follow, let’s discover just a few examples. In our instance dataset, all customers would, in absence of any personalization, obtain the next photos in the event that they seek for “cat”.
Nevertheless, a consumer who has a historical past of viewing the next photos (let’s name them comic-art-user) clearly has a sure type desire that isn’t addressed by nearly all of the earlier photos.
By combining Amazon Personalize with the vector database capabilities of OpenSearch Service, we’re in a position to return the next outcomes for cats to our consumer:
Within the following instance, a consumer has been viewing or downloading the next photos (let’s name them neon-punk-user).
They might obtain the next personalised outcomes as a substitute of the largely photorealistic cats that every one customers would obtain absent any personalization.
Lastly, a consumer seen or downloaded the next photos (let’s name them origami-clay-user).
They might obtain the next photos as their personalised search outcomes.
These examples illustrate how the search outcomes have been influenced by the customers’ earlier interactions with different photos. By combining the facility of Amazon Titan Multimodal Embeddings, OpenSearch Service vector indexing, and Amazon Personalize personalization, we’re in a position to ship every consumer related search ends in alignment with their type preferences versus displaying all of them the identical generic search outcome.
Moreover, as a result of Amazon Personalize is able to updating based mostly on modifications within the consumer type desire in actual time, these search outcomes would replace because the consumer’s type preferences change, for instance in the event that they have been a designer working for an advert company who switched mid-browsing session to engaged on a distinct challenge for a distinct model.
Clear up
To keep away from incurring future fees, delete the assets created whereas constructing this answer:
- Delete the OpenSearch Service domain or OpenSearch Serverless collection.
- Delete the SageMaker resources.
- Delete the Amazon Personalize resources.
Conclusion
By combining the facility of Amazon Titan Multimodal Embeddings, OpenSearch Service vector indexing and search capabilities, and Amazon Personalize ML suggestions, you may increase the consumer expertise with extra related gadgets of their search outcomes by studying from their earlier interactions and preferences.
For extra particulars on Amazon Titan Multimodal Embeddings, check with Amazon Titan Multimodal Embeddings G1 model. For extra particulars on OpenSearch Service, check with Getting started with Amazon OpenSearch Service. For extra particulars on Amazon Personalize, check with the Amazon Personalize Developer Guide.
In regards to the Authors
 Maysara Hamdan is a Associate Options Architect based mostly in Atlanta, Georgia. Maysara has over 15 years of expertise in constructing and architecting Software program Purposes and IoT Linked Merchandise in Telecom and Automotive Industries. In AWS, Maysara helps companions in constructing their cloud practices and rising their companies. Maysara is keen about new applied sciences and is all the time searching for methods to assist companions innovate and develop.
Maysara Hamdan is a Associate Options Architect based mostly in Atlanta, Georgia. Maysara has over 15 years of expertise in constructing and architecting Software program Purposes and IoT Linked Merchandise in Telecom and Automotive Industries. In AWS, Maysara helps companions in constructing their cloud practices and rising their companies. Maysara is keen about new applied sciences and is all the time searching for methods to assist companions innovate and develop.
 Eric Bolme is a Specialist Answer Architect with AWS based mostly on the East Coast of america. He has 8 years of expertise constructing out quite a lot of deep studying and different AI use instances and focuses on Personalization and Advice use instances with AWS.
Eric Bolme is a Specialist Answer Architect with AWS based mostly on the East Coast of america. He has 8 years of expertise constructing out quite a lot of deep studying and different AI use instances and focuses on Personalization and Advice use instances with AWS.






