The Previous, Current, and Way forward for Knowledge High quality Administration: Understanding Testing, Monitoring, and Knowledge Observability in 2024 | by Barr Moses | Might, 2024
The information property is evolving, and information high quality administration must evolve proper together with it. Listed below are three widespread approaches and the place the sector is heading within the AI period.

Are they totally different phrases for a similar factor? Distinctive approaches to the identical downside? One thing else fully?
And extra importantly — do you really want all three?
Like every part in information engineering, information high quality administration is evolving at lightning pace. The meteoric rise of information and AI within the enterprise has made information high quality a zero day danger for contemporary companies — and THE downside to unravel for information groups. With a lot overlapping terminology, it’s not all the time clear the way it all matches collectively — or if it matches collectively.
However opposite to what some would possibly argue, information high quality monitoring, information testing, and information observability aren’t contradictory and even various approaches to information high quality administration — they’re complementary parts of a single answer.
On this piece, I’ll dive into the specifics of those three methodologies, the place they carry out finest, the place they fall quick, and how one can optimize your information high quality observe to drive information belief in 2024.
Earlier than we will perceive the present answer, we have to perceive the issue — and the way it’s modified over time. Let’s contemplate the next analogy.
Think about you’re an engineer answerable for an area water provide. While you took the job, town solely had a inhabitants of 1,000 residents. However after gold is found beneath the city, your little group of 1,000 transforms right into a bona fide metropolis of 1,000,000.
How would possibly that change the way in which you do your job?
For starters, in a small atmosphere, the fail factors are comparatively minimal — if a pipe goes down, the foundation trigger might be narrowed to considered one of a pair anticipated culprits (pipes freezing, somebody digging into the water line, the standard) and resolved simply as shortly with the assets of 1 or two staff.
With the snaking pipelines of 1 million new residents to design and preserve, the frenzied tempo required to satisfy demand, and the restricted capabilities (and visibility) of your group, you now not have the the identical means to find and resolve each downside you anticipate to pop up — a lot much less be looking out for those you don’t.
The trendy information atmosphere is identical. Knowledge groups have struck gold, and the stakeholders need in on the motion. The extra your information atmosphere grows, the more difficult information high quality turns into — and the much less efficient conventional information high quality strategies might be.
They aren’t essentially unsuitable. However they aren’t sufficient both.
To be very clear, every of those strategies makes an attempt to handle information high quality. So, if that’s the issue it is advisable to build or buy for, any considered one of these would theoretically examine that field. Nonetheless, simply because these are all information high quality options doesn’t imply they’ll truly remedy your information high quality downside.
When and the way these options needs to be used is a bit more advanced than that.
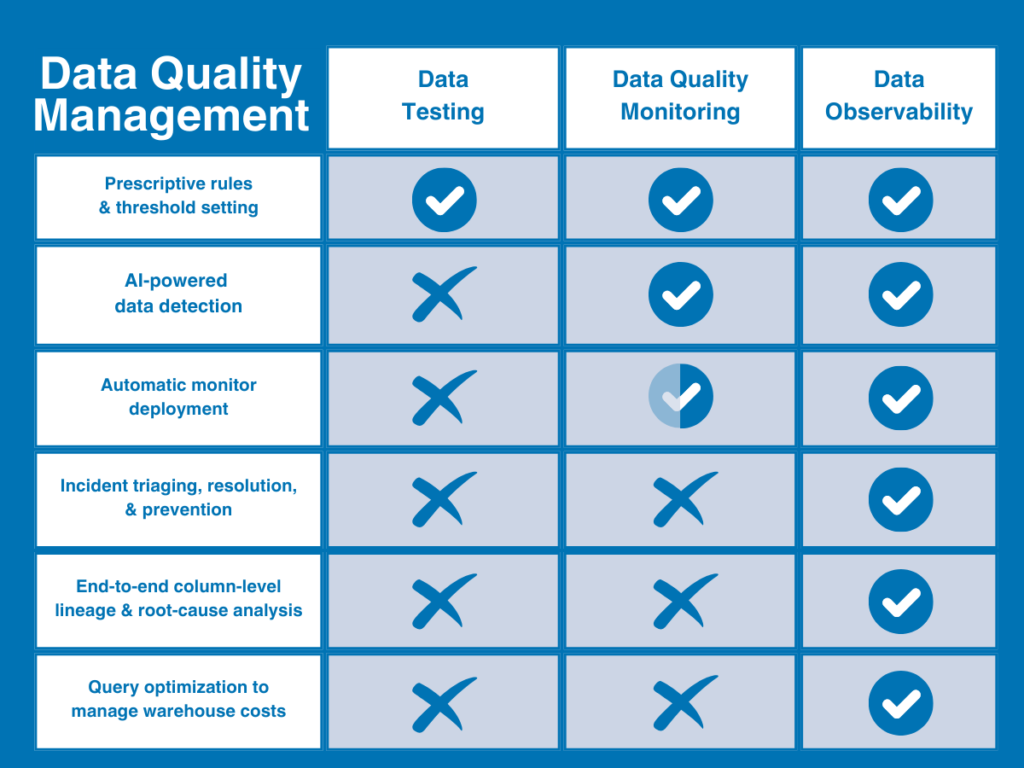
In its easiest phrases, you possibly can consider information high quality as the issue; testing and monitoring as strategies to determine high quality points; and information observability as a distinct and complete strategy that mixes and extends each strategies with deeper visibility and backbone options to unravel information high quality at scale.
Or to place it much more merely, monitoring and testing determine issues — information observability identifies issues and makes them actionable.
Right here’s a fast illustration that may assist visualize the place information observability matches within the data quality maturity curve.

Now, let’s dive into every methodology in a bit extra element.
The primary of two conventional approaches to information high quality is the info check. Data quality testing (or just data testing) is a detection methodology that employs user-defined constraints or guidelines to determine particular identified points inside a dataset as a way to validate data integrity and guarantee particular data quality standards.
To create a knowledge check, the info high quality proprietor would write a sequence of guide scripts (typically in SQL or leveraging a modular answer like dbt) to detect particular points like extreme null charges or incorrect string patterns.
When your information wants — and consequently, your information high quality wants — are very small, many groups will be capable of get what they want out of straightforward information testing. Nevertheless, As your information grows in measurement and complexity, you’ll shortly end up dealing with new information high quality points — and needing new capabilities to unravel them. And that point will come a lot earlier than later.
Whereas information testing will proceed to be a vital part of a knowledge high quality framework, it falls quick in a number of key areas:
- Requires intimate information information — information testing requires information engineers to have 1) sufficient specialised area information to outline high quality, and a couple of) sufficient information of how the info would possibly break to set-up assessments to validate it.
- No protection for unknown points — information testing can solely inform you concerning the points you anticipate finding — not the incidents you don’t. If a check isn’t written to cowl a selected challenge, testing gained’t discover it.
- Not scalable — writing 10 assessments for 30 tables is sort of a bit totally different from writing 100 assessments for 3,000.
- Restricted visibility — Knowledge testing solely assessments the info itself, so it could possibly’t inform you if the problem is known as a downside with the info, the system, or the code that’s powering it.
- No decision — even when information testing detects a difficulty, it gained’t get you any nearer to resolving it; or understanding what and who it impacts.
At any degree of scale, testing turns into the info equal of yelling “hearth!” in a crowded road after which strolling away with out telling anybody the place you noticed it.
One other conventional — if considerably extra subtle — strategy to information high quality, data quality monitoring is an ongoing answer that frequently screens and identifies unknown anomalies lurking in your information via both guide threshold setting or machine studying.
For instance, is your information coming in on-time? Did you get the variety of rows you have been anticipating?
The first profit of information high quality monitoring is that it gives broader protection for unknown unknowns, and frees information engineers from writing or cloning assessments for every dataset to manually determine widespread points.
In a way, you possibly can contemplate information high quality monitoring extra holistic than testing as a result of it compares metrics over time and allows groups to uncover patterns they wouldn’t see from a single unit check of the info for a identified challenge.
Sadly, information high quality monitoring additionally falls quick in a number of key areas.
- Elevated compute price — information high quality monitoring is pricey. Like information testing, information high quality monitoring queries the info straight — however as a result of it’s supposed to determine unknown unknowns, it must be utilized broadly to be efficient. Meaning large compute prices.
- Gradual time-to-value — monitoring thresholds might be automated with machine studying, however you’ll nonetheless must construct every monitor your self first. Meaning you’ll be doing loads of coding for every challenge on the entrance finish after which manually scaling these screens as your information atmosphere grows over time.
- Restricted visibility — information can break for every kind of causes. Similar to testing, monitoring solely seems to be on the information itself, so it could possibly solely inform you that an anomaly occurred — not why it occurred.
- No decision — whereas monitoring can actually detect extra anomalies than testing, it nonetheless can’t inform you what was impacted, who must learn about it, or whether or not any of that issues within the first place.
What’s extra, as a result of information high quality monitoring is simply simpler at delivering alerts — not managing them — your information group is much extra prone to expertise alert fatigue at scale than they’re to really enhance the info’s reliability over time.
That leaves information observability. In contrast to the strategies talked about above, information observability refers to a complete vendor-neutral answer that’s designed to supply full information high quality protection that’s each scalable and actionable.
Impressed by software program engineering finest practices, data observability is an end-to-end AI-enabled strategy to information high quality administration that’s designed to reply the what, who, why, and the way of information high quality points inside a single platform. It compensates for the restrictions of conventional information high quality strategies by leveraging each testing and absolutely automated information high quality monitoring right into a single system after which extends that protection into the info, system, and code ranges of your information atmosphere.
Mixed with crucial incident administration and backbone options (like automated column-level lineage and alerting protocols), information observability helps information groups detect, triage, and resolve information high quality points from ingestion to consumption.
What’s extra, information observability is designed to supply worth cross-functionally by fostering collaboration throughout groups, together with information engineers, analysts, information homeowners, and stakeholders.
Knowledge observability resolves the shortcomings of conventional DQ observe in 4 key methods:
- Sturdy incident triaging and backbone — most significantly, information observability gives the assets to resolve incidents sooner. Along with tagging and alerting, information observability expedites the root-cause course of with automated column-level lineage that lets groups see at a look what’s been impacted, who must know, and the place to go to repair it.
- Full visibility — information observability extends protection past the info sources into the infrastructure, pipelines, and post-ingestion techniques during which your information strikes and transforms to resolve information points for area groups throughout the corporate
- Sooner time-to-value — information observability absolutely automates the set-up course of with ML-based screens that present instantaneous protection right-out-of-the-box with out coding or threshold setting, so you may get protection sooner that auto-scales along with your atmosphere over time (together with customized insights and simplified coding instruments to make user-defined testing simpler too).
- Knowledge product well being monitoring — information observability additionally extends monitoring and well being monitoring past the standard desk format to observe, measure, and visualize the well being of particular information merchandise or crucial belongings.
We’ve all heard the phrase “rubbish in, rubbish out.” Effectively, that maxim is doubly true for AI functions. Nevertheless, AI doesn’t merely want higher information high quality administration to tell its outputs; your information high quality administration also needs to be powered by AI itself as a way to maximize scalability for evolving information estates.
Knowledge observability is the de facto — and arguably solely — information high quality administration answer that allows enterprise information groups to successfully ship dependable information for AI. And a part of the way in which it achieves that feat is by additionally being an AI-enabled answer.
By leveraging AI for monitor creation, anomaly detection, and root-cause evaluation, information observability allows hyper-scalable information high quality administration for real-time information streaming, RAG architectures, and different AI use-cases.
As the info property continues to evolve for the enterprise and past, conventional information high quality strategies can’t monitor all of the methods your information platform can break — or allow you to resolve it once they do.
Significantly within the age of AI, information high quality isn’t merely a enterprise danger however an existential one as properly. Should you can’t belief everything of the info being fed into your fashions, you possibly can’t belief the AI’s output both. On the dizzying scale of AI, conventional information high quality strategies merely aren’t sufficient to guard the worth or the reliability of these information belongings.
To be efficient, each testing and monitoring should be built-in right into a single platform-agnostic answer that may objectively monitor the whole information atmosphere — information, techniques, and code — end-to-end, after which arm information groups with the assets to triage and resolve points sooner.
In different phrases, to make information high quality administration helpful, trendy information groups want information observability.
First step. Detect. Second step. Resolve. Third step. Prosper.



