This Paper Reveals Insights from Reproducing OpenAI’s RLHF (Reinforcement Studying from Human Suggestions) Work: Implementation and Scaling Explored
In recent times, there was an infinite growth in pre-trained giant language fashions (LLMs). These LLMs are educated to foretell the subsequent token given the earlier tokens and supply an acceptable immediate. They’ll clear up varied pure language processing (NLP) duties. Nevertheless, the next-token prediction goal deviates from the elemental goal of “outputting contents that people want.”
To deal with this hole, Reinforcement Studying from Human Suggestions (RLHF) is launched as a pipeline to gather pair-wise human preferences, prepare a reward mannequin (RM) to mannequin these preferences, and use Reinforcement Studying (RL) to create a mannequin that outputs contents that people want. It has confirmed difficult to breed OpenAI’s RLHF pipeline within the open-source group for a number of causes:
- RL and RLHF have many delicate implementation particulars that may considerably affect coaching stability.
- The fashions are difficult to guage for the next duties: e.g., assessing the standard of 800 traces of generated code snippets for a coding process.
- They take a very long time to coach and iterate.
Hugging Face, Mila and Fuxi AI lab researchers have undertaken a novel strategy, presenting a high-precision copy of the Reinforcement Studying from Human Suggestions (RLHF) scaling behaviors reported in OpenAI’s seminal TL;DR summarization work. They meticulously created an RLHF pipeline, specializing in over 20 key implementation particulars. They adopted a unified studying price for SFT, RM, and PPO coaching to boost reproducibility.
They used the transformers library’s implementation of the Pythia fashions at the side of deepspeed’s ZeRO Stage 2 to assist match the fashions into the GPU reminiscence; for six.9B PPO coaching, in addition they transferred the reference coverage and reward mannequin to the CPU. The dropout layers have been turned off throughout coaching. That is necessary for PPO coaching, particularly as a result of with dropout activated, the log possibilities of tokens won’t be reproducible, making calculating the KL penalty unreliable whereas additionally inflicting the ratios of the PPO to be not 1s through the first epoch, inflicting PPO optimization issues. For consistency, in addition they flip off dropout for SFT and RM coaching.

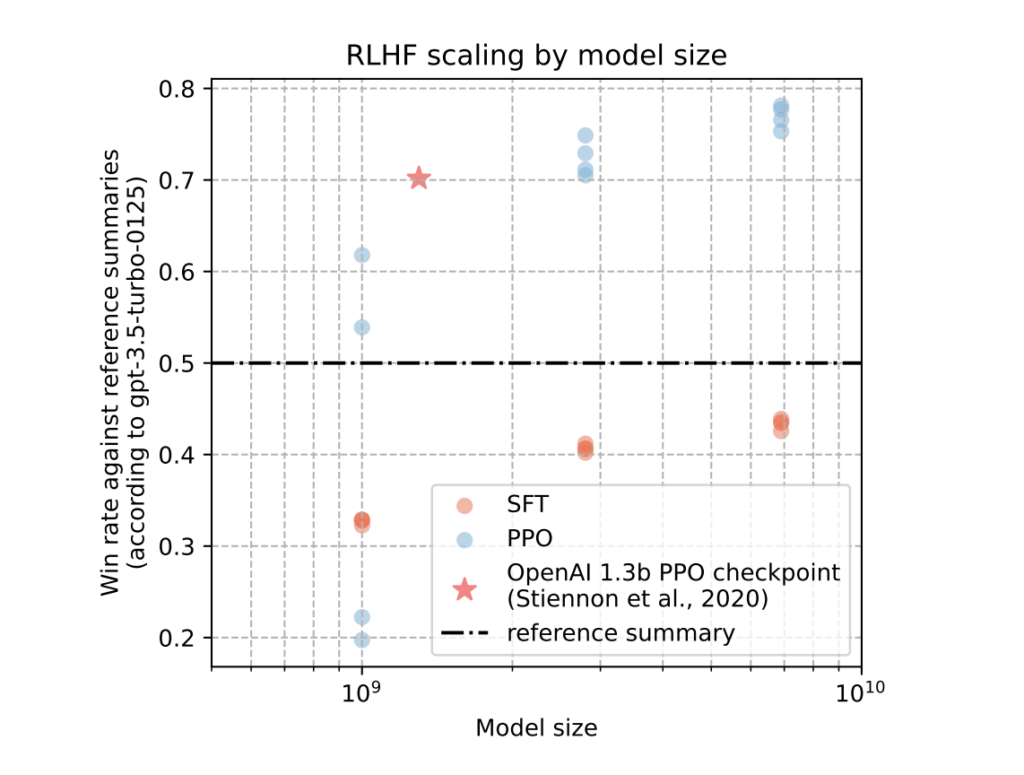
The PPO implementation optimizes the RLHF goal, resulting in a big enhance within the rating complete. Their greatest 6.9B mannequin is most popular by GPT almost 80% of the time, demonstrating its sensible superiority. For his or her 1B-sized mannequin, the common choice consistency in a number of random experiments is near 0.4, indicating that the 1B mannequin has captured a unique set of preferences, a discovering with necessary implications. It’s proven that PPO fashions outperform SFT fashions throughout all abstract lengths, additional reinforcing the sensible relevance of the analysis.
In conclusion, Mila and Fuxi AI lab researchers have efficiently reproduced the RLHF scaling behaviors reported in OpenAI’s seminal TL;DR summarization work with excessive precision. Their RLHF-trained Pythia fashions have demonstrated vital features in response high quality that scale with mannequin measurement. Notably, their 2.8B and 6.9B fashions have outperformed OpenAI’s launched 1.3B checkpoint, underscoring the significance of mannequin measurement in attaining superior outcomes.
Take a look at the Paper and Github. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our newsletter..
Don’t Overlook to affix our 39k+ ML SubReddit
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the purposes of machine studying in healthcare.