Harnessing Persuasion in AI: A Leap In the direction of Reliable Language Fashions
The exploration of aligning giant language fashions (LLMs) with human values and data has taken a big leap ahead with modern approaches that problem conventional alignment strategies. Conventional alignment strategies, closely reliant on labeled knowledge, face a bottleneck as a result of necessity of area experience and the ever-increasing breadth of questions these fashions can deal with. As fashions evolve, surpassing even knowledgeable data, the reliance on labeled knowledge turns into more and more impractical, highlighting the necessity for scalable oversight mechanisms that may adapt alongside these developments.
A novel paradigm emerges from using much less succesful fashions to information the alignment of their extra superior counterparts. This methodology leverages a elementary perception: critiquing or figuring out the proper reply is commonly extra simple than producing it. Debate, as proposed by Irving et al., emerges as a strong software on this context, offering a framework the place a human or a weaker mannequin can consider the accuracy of solutions by way of adversarial critiques generated throughout the debate.

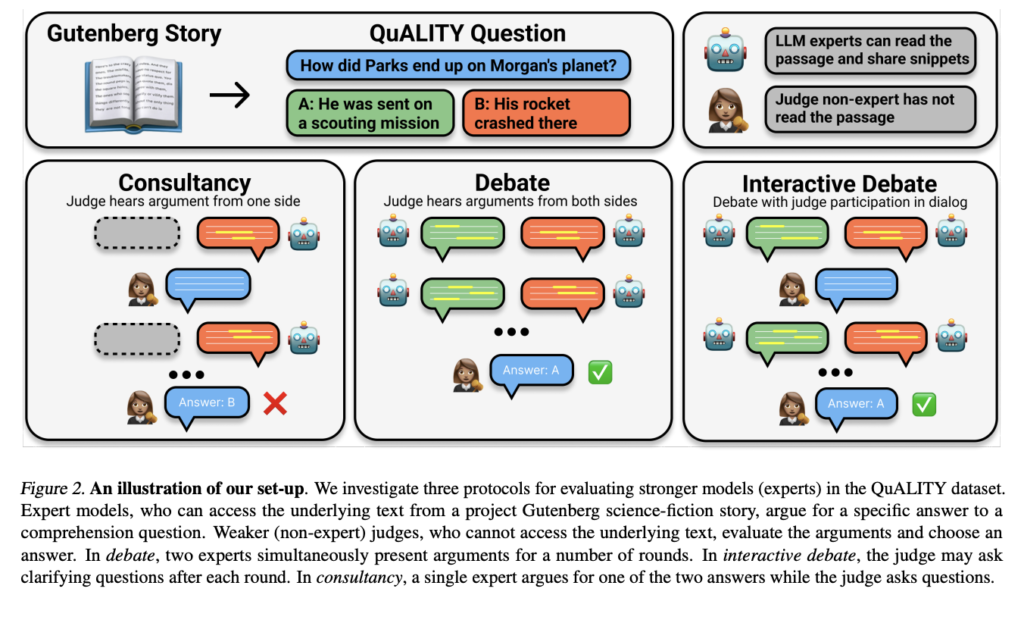
The analysis delves into the efficacy of debates in aiding “weaker” judges, who lack entry to complete background data, to guage “stronger” fashions. By means of information-asymmetric debates in a studying comprehension job, the examine illustrates how debates between consultants, geared up with a quote verification software, allow judges to discern the proper solutions with out direct entry to the supply materials. This setup, as proven in Determine 2, focuses on the dynamics between debaters and judges and highlights a vital side of scalable oversight: non-experts’ capacity to extract the reality from knowledgeable discussions.
Debate protocols, together with customary debates and interactive debates, alongside a consultancy baseline for comparability, kind the core of the experimental setup. These protocols are meticulously designed to check the speculation underneath numerous circumstances, together with totally different numbers of debate rounds and phrase limits, guaranteeing a managed atmosphere for evaluating the fashions’ persuasiveness and accuracy.
The examine employs a variety of enormous language fashions as contributors in these debates, together with variations of GPT and Claude fashions, fine-tuned by way of reinforcement studying and Constitutional AI. The fashions endure optimization for persuasiveness utilizing inference-time strategies, aiming to reinforce their capacity to argue convincingly for the proper solutions. This optimization course of, together with strategies like best-of-N sampling and critique-and-refinement, is vital for assessing the fashions’ effectiveness in influencing judges’ selections.
A good portion of the analysis is devoted to evaluating these protocols by way of the lens of each human and LLM judges, evaluating the outcomes in opposition to the consultancy baseline. The findings reveal a notable enchancment in judges’ capacity to determine the reality in debates, with persuasive fashions resulting in larger accuracy charges. This means that optimizing debaters for persuasiveness can certainly end in extra truthful outcomes.
Furthermore, the examine extends its evaluation to human judges, demonstrating their well-calibrated judgment and decrease error charges when taking part in debates. This human ingredient underscores the potential of debate as a mechanism not just for mannequin alignment but in addition for enhancing human decision-making within the absence of full data.
In conclusion, the analysis presents a compelling case for debate as a scalable oversight mechanism able to eliciting extra truthful solutions from LLMs and supporting human judgment. By enabling non-experts to discern fact by way of knowledgeable debates, the examine showcases a promising avenue for future analysis in mannequin alignment. The restrictions highlighted, together with the reliance on entry to verified proof and the potential challenges with fashions of differing reasoning skills, pave the best way for additional exploration. This work not solely contributes to the continuing discourse on aligning LLMs with human values but in addition opens new pathways for augmenting human judgment and facilitating the event of reliable AI programs.
By means of a complete examination of debate protocols, optimization strategies, and the impression on each LLM and human judges, this examine illuminates the potential of debate to foster a extra truthful, persuasive, and finally reliable technology of language fashions. As we enterprise into an period the place AI’s capabilities proceed to broaden, the rules of debate and persuasion stand as beacons guiding the trail towards alignment, accountability, and enhanced human-AI collaboration.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and Google News. Be part of our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our newsletter..
Don’t Neglect to hitch our Telegram Channel
You may additionally like our FREE AI Courses….
Vineet Kumar is a consulting intern at MarktechPost. He’s at the moment pursuing his BS from the Indian Institute of Know-how(IIT), Kanpur. He’s a Machine Studying fanatic. He’s captivated with analysis and the most recent developments in Deep Studying, Pc Imaginative and prescient, and associated fields.