On Noisy Analysis in Federated Hyperparameter Tuning – Machine Studying Weblog | ML@CMU
Evaluating fashions in federated networks is difficult because of elements akin to shopper subsampling, information heterogeneity, and privateness. These elements introduce noise that may have an effect on hyperparameter tuning algorithms and result in suboptimal mannequin choice.
Hyperparameter tuning is essential to the success of cross-device federated studying purposes. Sadly, federated networks face problems with scale, heterogeneity, and privateness, which introduce noise within the tuning course of and make it tough to faithfully consider the efficiency of assorted hyperparameters. Our work (MLSys’23) explores key sources of noise and surprisingly reveals that even small quantities of noise can have a major influence on tuning strategies—decreasing the efficiency of state-of-the-art approaches to that of naive baselines. To handle noisy analysis in such situations, we suggest a easy and efficient method that leverages public proxy information to spice up the analysis sign. Our work establishes normal challenges, baselines, and greatest practices for future work in federated hyperparameter tuning.
Federated Studying: An Overview

Cross-device federated studying (FL) is a machine studying setting that considers coaching a mannequin over a massive heterogeneous community of units akin to cell phones or wearables. Three key elements differentiate FL from conventional centralized studying and distributed studying:
Scale. Cross-device refers to FL settings with many purchasers with probably restricted native sources e.g. coaching a language mannequin throughout a whole lot to hundreds of thousands of cell phones. These units have varied useful resource constraints, akin to restricted add velocity, variety of native examples, or computational functionality.
Heterogeneity. Conventional distributed ML assumes every employee/shopper has a random (identically distributed) pattern of the coaching information. In distinction, in FL shopper datasets could also be non-identically distributed, with every person’s information being generated by a definite underlying distribution.
Privateness. FL presents a baseline stage of privateness since uncooked person information stays native on every shopper. Nonetheless, FL remains to be weak to post-hoc assaults the place the general public output of the FL algorithm (e.g. a mannequin or its hyperparameters) could be reverse-engineered and leak personal person data. A standard method to mitigate such vulnerabilities is to make use of differential privateness, which goals to masks the contribution of every shopper. Nonetheless, differential privateness introduces noise within the mixture analysis sign, which might make it tough to successfully choose fashions.
Federated Hyperparameter Tuning
Appropriately deciding on hyperparameters (HPs) is essential to coaching high quality fashions in FL. Hyperparameters are user-specified parameters that dictate the method of mannequin coaching akin to the training charge, native batch dimension, and variety of purchasers sampled at every spherical. The issue of tuning HPs is normal to machine studying (not simply FL). Given an HP search area and search funds, HP tuning strategies purpose to discover a configuration within the search area that optimizes some measure of high quality inside a constrained funds.
Let’s first have a look at an end-to-end FL pipeline that considers each the processes of coaching and hyperparameter tuning. In cross-device FL, we break up the purchasers into two swimming pools for coaching and validation. Given a hyperparameter configuration ((lambda_s, lambda_c)), we practice a mannequin utilizing the coaching purchasers (defined in part “FL Coaching”). We then consider this mannequin on the validation purchasers, acquiring an error charge/accuracy metric. We are able to then use the error charge to regulate the hyperparameters and practice a brand new mannequin.
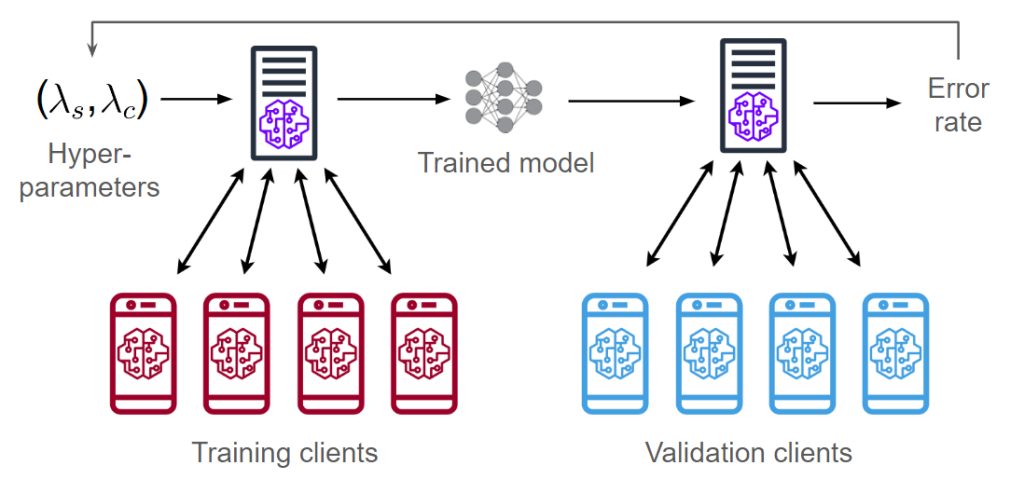
The diagram above reveals two vectors of hyperparameters (lambda_s, lambda_c). These correspond to the hyperparameters of two optimizers: one is server-side and the opposite is client-side. Subsequent, we describe how these hyperparameters are used throughout FL coaching.
FL Coaching
A typical FL algorithm consists of a number of rounds of coaching the place every shopper performs native coaching adopted by aggregation of the shopper updates. In our work, we experiment with a normal framework known as FedOPT which was introduced in Adaptive Federated Optimization (Reddi et al. 2021). We define the per-round process of FedOPT under:
- The server broadcasts the mannequin (theta) to a sampled subset of (Ok) purchasers.
- Every shopper (in parallel) trains (theta) on their native information (X_k) utilizing
ClientOPTand obtains an up to date mannequin (theta_k). - Every shopper sends (theta_k) again to the server.
- The server averages all of the obtained fashions (theta’ = frac{1}{Ok} sum_k p_ktheta_k).
- To replace (theta), the server computes the distinction (theta – theta’) and feeds it as a pseudo-gradient into
ServerOPT(slightly than computing a gradient w.r.t. some loss operate).

Steps 2 and 5 of FedOPT every require a gradient-based optimization algorithm (known as ClientOPT and ServerOPT) which specify the best way to replace (theta) given some replace vector. In our work, we deal with an instantiation of FedOPT known as FedAdam, which makes use of Adam (Kingma and Ba 2014) as ServerOPT and SGD as ClientOPT. We deal with tuning 5 FedAdam hyperparameters: two for shopper coaching (SGD’s studying charge and batch dimension) and three for server aggregation (Adam’s studying charge, 1st-moment decay, and 2nd-moment decay).
FL Analysis
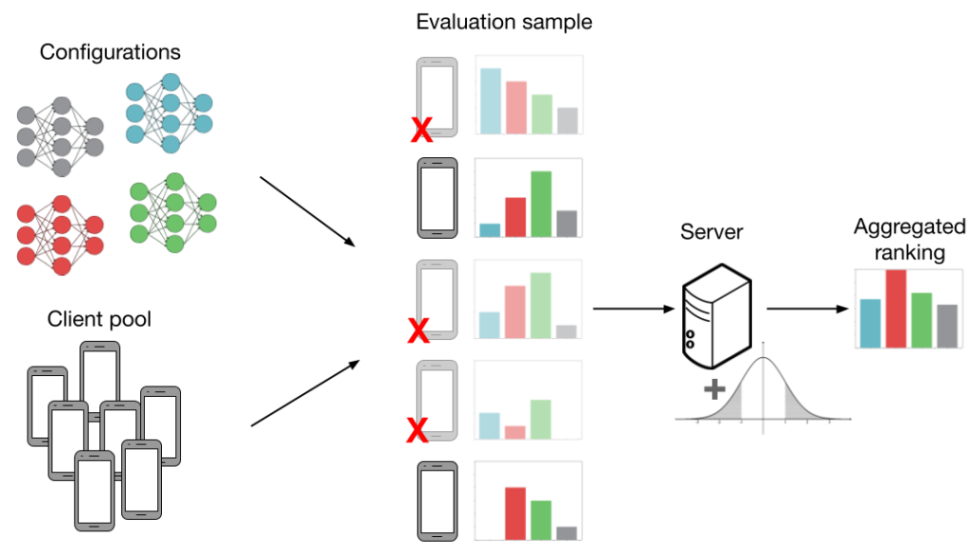
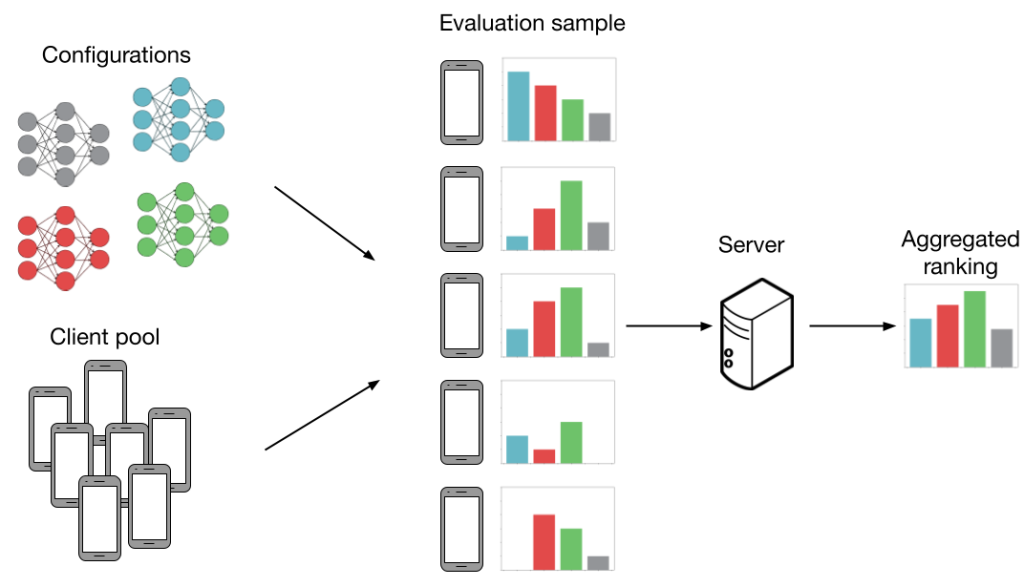
Now, we focus on how FL settings introduce noise to mannequin analysis. Think about the next instance under. We’ve got (Ok=4) configurations (gray, blue, pink, inexperienced) and we need to work out which configuration has the very best common accuracy throughout (N=5) purchasers. Extra particularly, every “configuration” is a set of HP values (studying charge, batch dimension, and many others.) which can be fed into an FL coaching algorithm (extra particulars within the subsequent part). This produces a mannequin we will consider. If we will consider each mannequin on each shopper then our analysis is noiseless. On this case, we might be capable of precisely decide that the inexperienced mannequin performs the very best. Nonetheless, producing all of the evaluations as proven under is just not sensible, as analysis prices scale with each the variety of configurations and purchasers.
Beneath, we present an analysis process that’s extra lifelike in FL. As the first problem in cross-device FL is scale, we consider fashions utilizing solely a random subsample of purchasers. That is proven within the determine by pink ‘X’s and shaded-out telephones. We cowl three extra sources of noise in FL which might negatively work together with subsampling and introduce much more noise into the analysis process:
Information heterogeneity. FL purchasers might have non-identically distributed information, that means that the evaluations on varied fashions can differ between purchasers. That is proven by the totally different histograms subsequent to every shopper. Information heterogeneity is intrinsic to FL and is essential for our observations on noisy analysis; if all purchasers had similar datasets, there could be no have to pattern a couple of shopper.
Methods heterogeneity. Along with information heterogeneity, purchasers might have heterogeneous system capabilities. For instance, some purchasers have higher community reception and computational {hardware}, which permits them to take part in coaching and analysis extra incessantly. This biases efficiency in the direction of these purchasers, resulting in a poor general mannequin.
Differential privateness. Utilizing the analysis output (i.e. the top-performing mannequin), a malicious get together can infer whether or not or not a specific shopper participated within the FL process. At a excessive stage, differential privateness goals to masks person contributions by including noise to the mixture analysis metric. Nonetheless, this extra noise could make it tough to faithfully consider HP configurations.
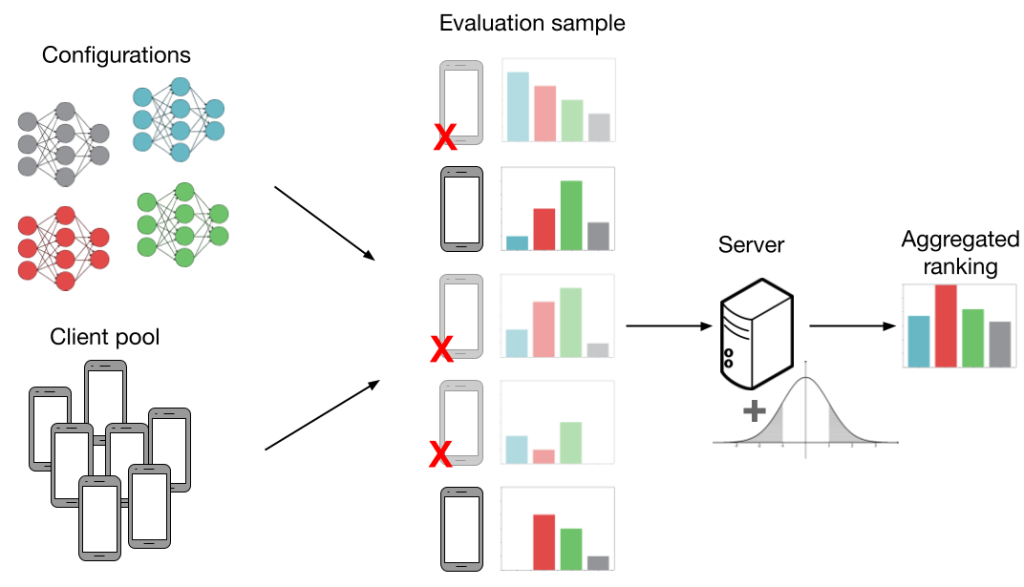
Within the determine above, evaluations can result in suboptimal mannequin choice after we think about shopper subsampling, information heterogeneity, and differential privateness. The mix of all these elements leads us to incorrectly select the pink mannequin over the inexperienced one.
Experimental Outcomes
The primary aim of our work is to analyze the influence of 4 sources of noisy analysis that we outlined within the part “FL Analysis”. In additional element, these are our analysis questions:
- How does subsampling validation purchasers have an effect on HP tuning efficiency?
- How do the next elements work together with/exacerbate problems with subsampling?
- information heterogeneity (shuffling validation purchasers’ datasets)
- programs heterogeneity (biased shopper subsampling)
- privateness (including Laplace noise to the mixture analysis)
- In noisy settings, how do SOTA strategies evaluate to easy baselines?
Surprisingly, we present that state-of-the-art HP tuning strategies can carry out catastrophically poorly, even worse than easy baselines (e.g., random search). Whereas we solely present outcomes for CIFAR10, outcomes on three different datasets (FEMNIST, StackOverflow, and Reddit) could be present in our paper. CIFAR10 is partitioned such that every shopper has at most two out of the ten whole labels.
Noise hurts random search
This part investigates questions 1 and a pair of utilizing random search (RS) because the hyperparameter tuning technique. RS is an easy baseline that randomly samples a number of HP configurations, trains a mannequin for every one, and returns the highest-performing mannequin (i.e. the instance in “FL Analysis”, if the configurations had been sampled independently from the identical distribution). Typically, every hyperparameter worth is sampled from a (log) uniform or regular distribution.
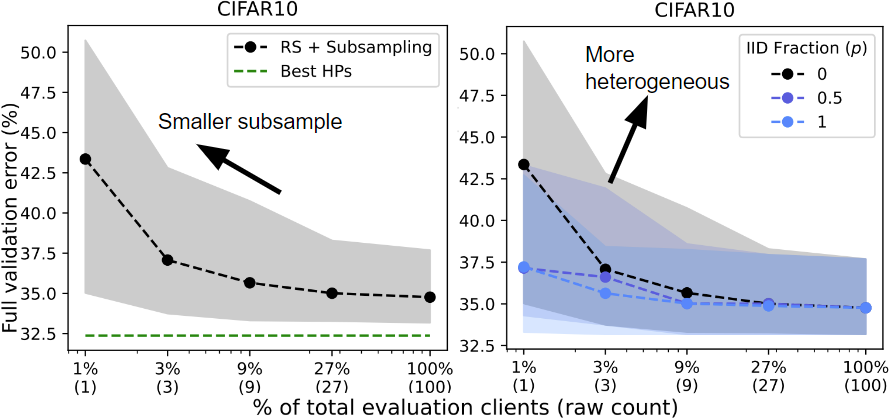
Consumer subsampling. We run RS whereas various the shopper subsampling charge from a single shopper to the complete validation shopper pool. “Greatest HPs” signifies the very best HPs discovered throughout all trials of RS. As we subsample much less purchasers (left), random search performs worse (larger error charge).
Information heterogeneity. We run RS on three separate validation partitions with various levels of knowledge heterogeneity primarily based on the label distributions on every shopper. Consumer subsampling usually harms efficiency however has a higher influence on efficiency when the info is heterogeneous (IID Fraction = 0 vs. 1).
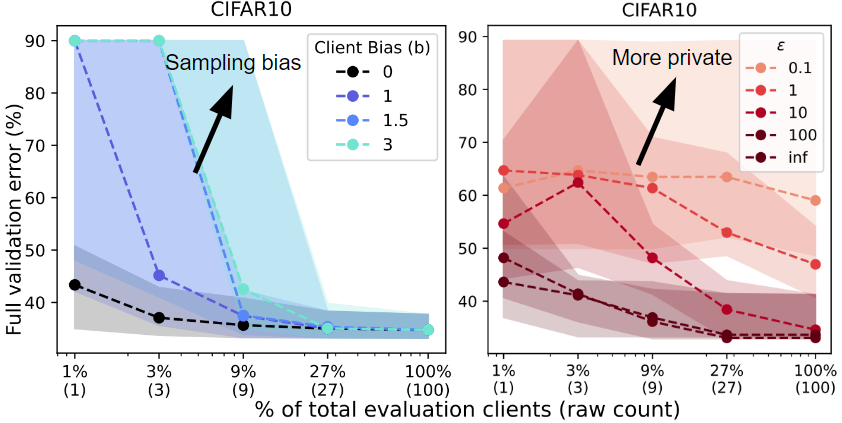
Methods heterogeneity. We run RS and bias the shopper sampling to replicate 4 levels of programs heterogeneity. Primarily based on the mannequin that’s presently being evaluated, we assign a better likelihood of sampling purchasers who carry out effectively on this mannequin. Sampling bias results in worse efficiency for the reason that biased evaluations are overly optimistic and don’t replicate efficiency over your complete validation pool.
Privateness. We run RS with 5 totally different analysis privateness budgets (varepsilon). We add noise sampled from (textual content{Lap}(M/(varepsilon |S|))) to the mixture analysis, the place (M) is the variety of evaluations (16), (varepsilon) is the privateness funds (every curve), and (|S|) is the variety of purchasers sampled for an analysis (x-axis). A smaller privateness funds requires sampling a bigger uncooked variety of purchasers to attain affordable efficiency.
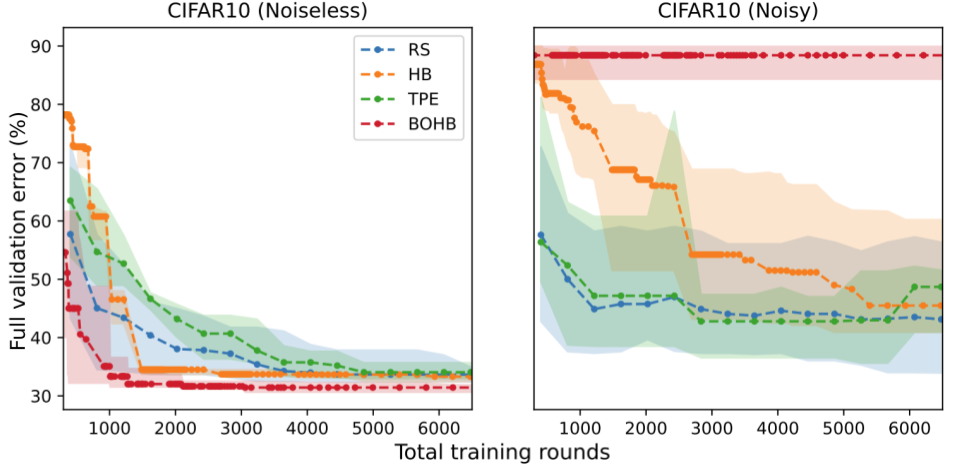
Noise hurts advanced strategies greater than RS
Seeing that noise adversely impacts random search, we now deal with query 3: Do the identical observations maintain for extra advanced tuning strategies? Within the subsequent experiment, we evaluate 4 consultant HP tuning strategies.
- Random Search (RS) is a naive baseline.
- Tree-Structured Parzen Estimator (TPE) is a selection-based technique. These strategies construct a surrogate mannequin that predicts the efficiency of assorted hyperparameters slightly than predictions for the duty at hand (e.g. picture or language information).
- Hyperband (HB) is an allocation-based technique. These strategies allocate extra sources to essentially the most promising configurations. Hyperband initially samples a lot of configurations however stops coaching most of them after the primary few rounds.
- Bayesian Optimization + Hyperband (BOHB) is a mixed technique that makes use of each the sampling technique of TPE and the partial evaluations of HB.
We report the error charge of every HP tuning technique (y-axis) at a given funds of rounds (x-axis). Surprisingly, we discover that the relative rating of those strategies could be reversed when the analysis is noisy. With noise, the efficiency of all strategies degrades, however the degradation is especially excessive for HB and BOHB. Intuitively, it is because these two strategies already inject noise into the HP tuning process through early stopping which interacts poorly with extra sources of noise. Due to this fact, these outcomes point out a necessity for HP tuning strategies which can be specialised for FL, as lots of the guiding ideas for conventional hyperparameter tuning might not be efficient at dealing with noisy analysis in FL.
Proxy analysis outperforms noisy analysis
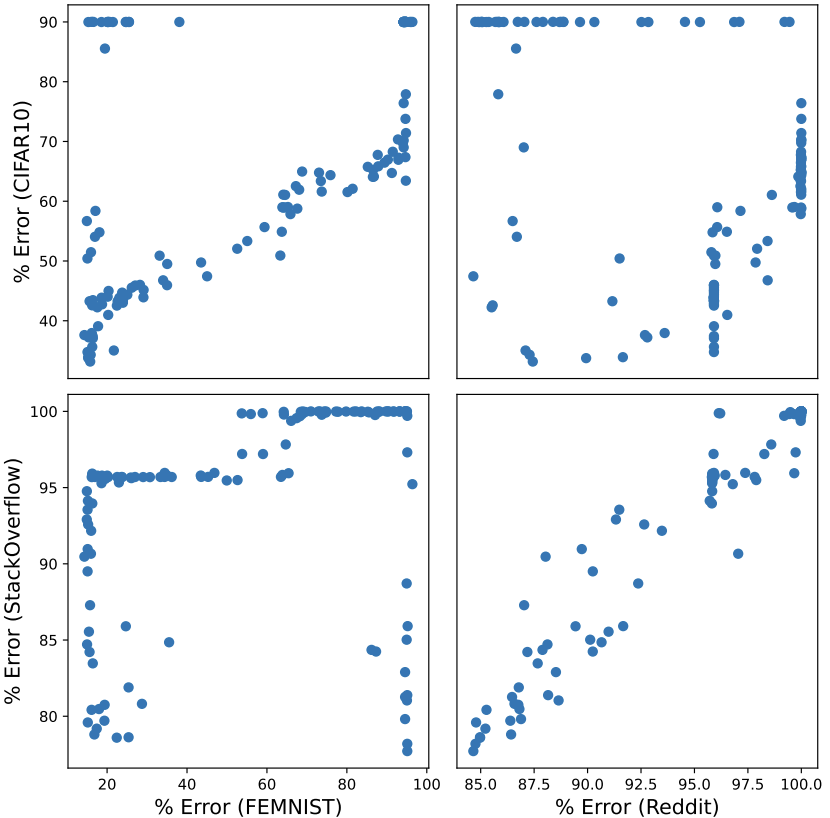
In sensible FL settings, a practitioner might have entry to public proxy information which can be utilized to coach fashions and choose hyperparameters. Nonetheless, given two distinct datasets, it’s unclear how effectively hyperparameters can switch between them. First, we discover the effectiveness of hyperparameter switch between 4 datasets. Beneath, we see that the CIFAR10-FEMNIST and StackOverflow-Reddit pairs (high left, backside proper) present the clearest switch between the 2 datasets. One possible purpose for that is that these job pairs use the identical mannequin structure: CIFAR10 and FEMNIST are each picture classification duties whereas StackOverflow and Reddit are next-word prediction duties.
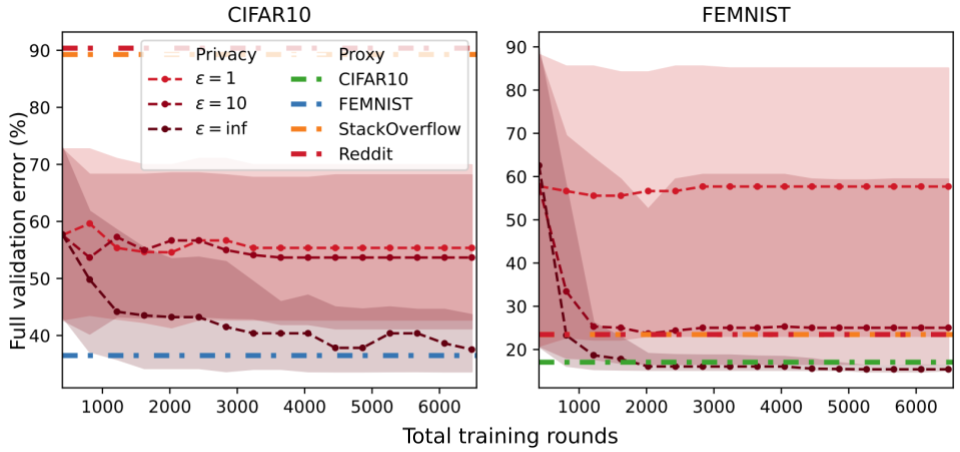
Given the suitable proxy dataset, we present {that a} easy technique known as one-shot proxy random search can carry out extraordinarily effectively. The algorithm has two steps:
- Run a random search utilizing the proxy information to each practice and consider HPs. We assume the proxy information is each public and server-side, so we will all the time consider HPs with out subsampling purchasers or including privateness noise.
- The output configuration from 1. is used to coach a mannequin on the coaching shopper information. Since we cross solely a single configuration to this step, validation shopper information doesn’t have an effect on hyperparameter choice in any respect.
In every experiment, we select one among these datasets to be partitioned among the many purchasers and use the opposite three datasets as server-side proxy datasets. Our outcomes present that proxy information could be an efficient resolution. Even when the proxy dataset is just not a super match for the general public information, it could be the one out there resolution beneath a strict privateness funds. That is proven within the FEMNIST plot the place the orange/pink strains (textual content datasets) carry out equally to the (varepsilon=10) curve.
Conclusion
In conclusion, our research suggests a number of greatest practices for federated HP tuning:
- Use easy HP tuning strategies.
- Pattern a sufficiently massive variety of validation purchasers.
- Consider a consultant set of purchasers.
- If out there, proxy information could be an efficient resolution.
Moreover, we establish a number of instructions for future work in federated HP tuning:
- Tailoring HP tuning strategies for differential privateness and FL. Early stopping strategies are inherently noisy/biased and the massive variety of evaluations they use is at odds with privateness. One other helpful path is to analyze HP strategies particular to noisy analysis.
- Extra detailed value analysis. In our work, we solely thought of the variety of coaching rounds as our useful resource funds. Nonetheless, sensible FL settings think about all kinds of prices, akin to whole communication, quantity of native coaching, or whole time to coach a mannequin.
- Combining proxy and shopper information for HP tuning. A key concern of utilizing public proxy information for HP tuning is that the very best proxy dataset is just not recognized prematurely. One path to deal with that is to design strategies that mix private and non-private evaluations to mitigate bias from proxy information and noise from personal information. One other promising path is to depend on the abundance of public information and design a way that may choose the very best proxy dataset.