How To Practice Your LLM Effectively? Finest Practices for Small-Scale Implementation
Among the many day by day deluge of reports about new developments in Giant Language Fashions (LLMs), you may be asking, “how do I prepare my very own?”. Right this moment, an LLM tailor-made to your particular wants is turning into an more and more important asset, however their ‘Giant’ scale comes with a value. The spectacular success of LLMs can largely be attributed to scaling legal guidelines, which say {that a} mannequin’s efficiency will increase with its variety of parameters and the dimensions of its coaching information. Fashions like GPT-4, Llama2, and Palm2 had been educated on among the world’s largest clusters, and the assets required to coach a full-scale mannequin are sometimes unattainable for people and small enterprises.
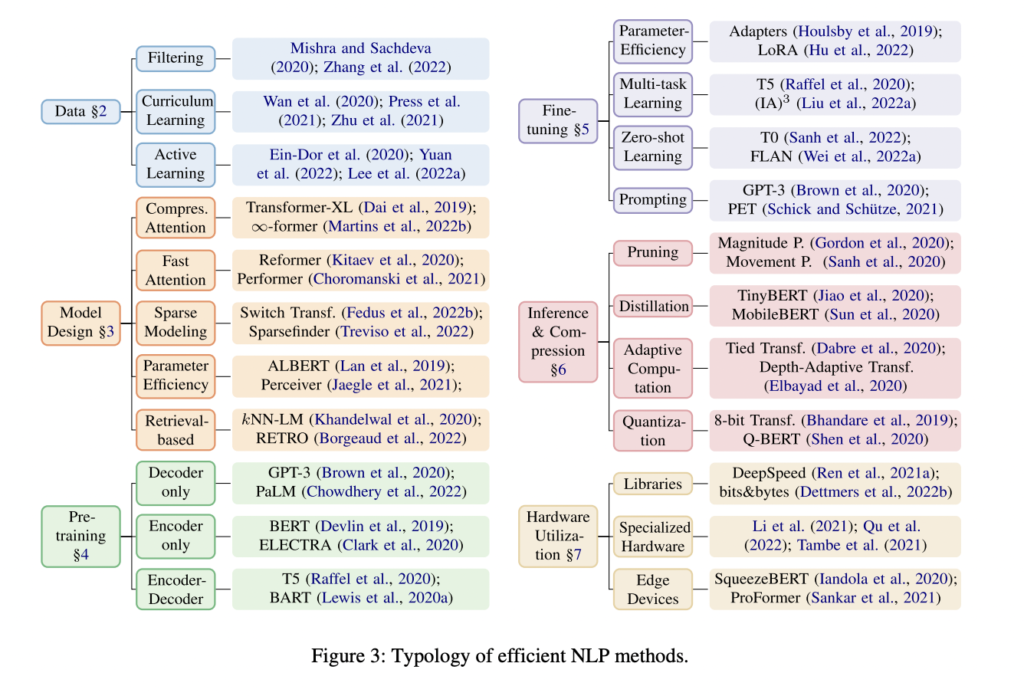
Environment friendly coaching of LLMs is an energetic space of analysis that focuses on making them faster, much less memory-hungry, and extra energy-saving. Effectivity right here is outlined as reaching a steadiness between the standard (for instance, efficiency) of the mannequin and its footprint (useful resource utilization). This text will enable you in choosing both data-efficient or model-efficient coaching methods tailor-made to your wants. For a deeper dive, the commonest fashions and their references are illustrated within the accompanying diagram.
Knowledge Effectivity. Enhancing the effectivity of coaching may be considerably influenced by the strategic collection of information. One strategy is information filtering, which may be finished previous to the coaching to kind a core dataset that comprises sufficient data to realize comparable mannequin efficiency as the complete set. One other methodology is curriculum studying, which entails systematic scheduling of information cases throughout coaching. This might imply beginning with less complicated examples and step by step progressing to extra complicated ones or the reverse. Moreover, these strategies may be adaptive and kind a assorted sampling distribution throughout the dataset all through coaching.

Mannequin effectivity. Essentially the most simple technique to get hold of environment friendly fashions is to design the appropriate structure. In fact, that is removed from simple. Happily, we will make the duty extra accessible by means of automated mannequin choice strategies like neural structure search (NAS) and hyperparameter optimization. Having the appropriate structure, effectivity is launched by emulating the efficiency of large-scale fashions with fewer parameters. Many profitable LLMs use the transformer structure, famend for its multi-level sequence modeling and parallelization capabilities. Nevertheless, because the underlying consideration mechanism scales quadratically with enter measurement, managing lengthy sequences turns into a problem. Improvements on this space embody enhancing the eye mechanism with recurrent networks, long-term reminiscence compression, and balancing native and world consideration.
On the identical time, parameter effectivity strategies can be utilized to overload their utilization for a number of operations. This entails methods like weight sharing throughout comparable operations to scale back reminiscence utilization, as seen in Common or Recursive Transformers. Sparse coaching, which prompts solely a subset of parameters, leverages the “lottery ticket speculation” – the idea that smaller, effectively educated subnetworks can rival full mannequin efficiency.
One other key side is mannequin compression, decreasing computational load and reminiscence wants with out sacrificing efficiency. This contains pruning much less important weights, information distillation to coach smaller fashions that replicate bigger ones, and quantization for improved throughput. These strategies not solely optimize mannequin efficiency but additionally speed up inference occasions, which is very important in cell and real-time functions.
Coaching setup. Because of the huge quantity of accessible information, two widespread themes emerged to make coaching more practical. Pre-training, typically finished in a self-supervised method on a big unlabelled dataset, is step one, utilizing assets like Common Crawl – Get Started for preliminary coaching. The subsequent section, “fine-tuning,” entails coaching on task-specific information. Whereas pre-training a mannequin like BERT from scratch is feasible, utilizing an current mannequin like bert-large-cased · Hugging Face is commonly extra sensible, besides for specialised circumstances. With handiest fashions being too massive for continued coaching on restricted assets, the main focus is on Parameter-Environment friendly High quality-Tuning (PEFT). On the forefront of PEFT are strategies like “adapters,” which introduce further layers educated whereas retaining the remainder of the mannequin mounted, and studying separate “modifier” weights for authentic weights, utilizing strategies like sparse coaching or low-rank adaptation (LoRA). Maybe the best level of entry for adapting fashions is immediate engineering. Right here we depart the mannequin as is, however select prompts strategically such that the mannequin generates essentially the most optimum responses to our duties. Current analysis goals to automate that course of with a further mannequin.
In conclusion, the effectivity of coaching LLMs hinges on good methods like cautious information choice, mannequin structure optimization, and progressive coaching strategies. These approaches democratize the usage of superior LLMs, making them accessible and sensible for a broader vary of functions and customers.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to hitch our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI tasks, and extra.
If you like our work, you will love our newsletter..
Michal Lisicki is a Ph.D. pupil on the College of Guelph and Vector Institute for AI in Canada. His analysis spans a number of matters in deep studying, starting with 3D imaginative and prescient for robotics and medical picture evaluation in his early profession to Bayesian optimization and sequential decision-making underneath uncertainty. His present analysis is concentrated on the event of sequential decision-making algorithms for improved information and mannequin effectivity of deep neural networks.



