KT’s journey to scale back coaching time for a imaginative and prescient transformers mannequin utilizing Amazon SageMaker
KT Corporation is without doubt one of the largest telecommunications suppliers in South Korea, providing a variety of companies together with fixed-line phone, cellular communication, and web, and AI companies. KT’s AI Meals Tag is an AI-based dietary administration answer that identifies the sort and dietary content material of meals in pictures utilizing a pc imaginative and prescient mannequin. This imaginative and prescient mannequin developed by KT depends on a mannequin pre-trained with a considerable amount of unlabeled picture information to investigate the dietary content material and calorie data of varied meals. The AI Meals Tag may help sufferers with power ailments similar to diabetes handle their diets. KT used AWS and Amazon SageMaker to coach this AI Meals Tag mannequin 29 occasions quicker than earlier than and optimize it for manufacturing deployment with a mannequin distillation approach. On this publish, we describe KT’s mannequin growth journey and success utilizing SageMaker.
Introducing the KT challenge and defining the issue
The AI Meals Tag mannequin pre-trained by KT relies on the imaginative and prescient transformers (ViT) structure and has extra mannequin parameters than their earlier imaginative and prescient mannequin to enhance accuracy. To shrink the mannequin dimension for manufacturing, KT is utilizing a information distillation (KD) approach to scale back the variety of mannequin parameters with out important affect to accuracy. With information distillation, the pre-trained mannequin is known as a instructor mannequin, and a light-weight output mannequin is skilled as a scholar mannequin, as illustrated within the following determine. The light-weight scholar mannequin has fewer mannequin parameters than the instructor, which reduces reminiscence necessities and permits for deployment on smaller, inexpensive cases. The scholar maintains acceptable accuracy although it’s smaller by studying from the outputs of the instructor mannequin.
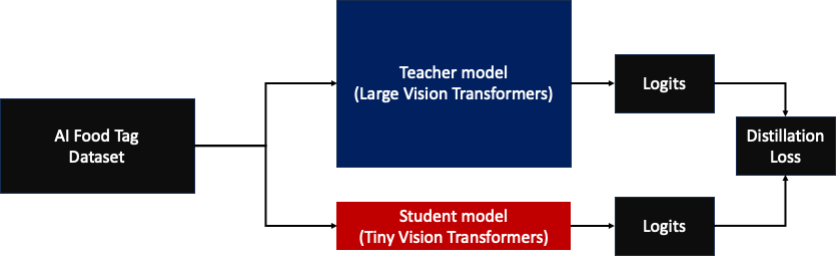
The instructor mannequin stays unchanged throughout KD, however the scholar mannequin is skilled utilizing the output logits of the instructor mannequin as labels to calculate loss. With this KD paradigm, each the instructor and the scholar have to be on a single GPU reminiscence for coaching. KT initially used two GPUs (A100 80 GB) of their inner, on-premises surroundings to coach the scholar mannequin, however the course of took about 40 days to cowl 300 epochs. To speed up coaching and generate a scholar mannequin in much less time, KT partnered with AWS. Collectively, the groups considerably diminished mannequin coaching time. This publish describes how the workforce used Amazon SageMaker Training, the SageMaker Data Parallelism Library, Amazon SageMaker Debugger, and Amazon SageMaker Profiler to efficiently develop a light-weight AI Meals Tag mannequin.
Constructing a distributed coaching surroundings with SageMaker
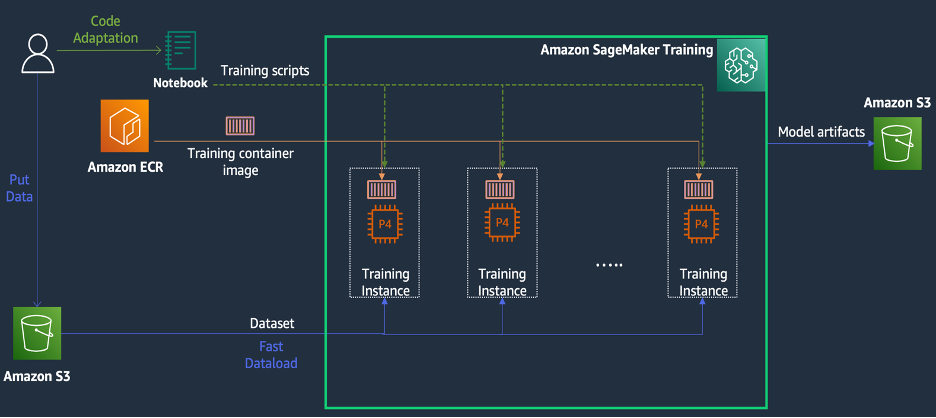
SageMaker Coaching is a managed machine studying (ML) coaching surroundings on AWS that gives a set of options and instruments to simplify the coaching expertise and may be helpful in distributed computing, as illustrated within the following diagram.
SageMaker clients can even entry built-in Docker photos with varied pre-installed deep studying frameworks and the required Linux, NCCL, and Python packages for mannequin coaching. Information scientists or ML engineers who wish to run mannequin coaching can accomplish that with out the burden of configuring coaching infrastructure or managing Docker and the compatibility of various libraries.
Throughout a 1-day workshop, we had been in a position to arrange a distributed coaching configuration primarily based on SageMaker inside KT’s AWS account, speed up KT’s coaching scripts utilizing the SageMaker Distributed Information Parallel (DDP) library, and even check a coaching job utilizing two ml.p4d.24xlarge cases. On this part, we describe KT’s expertise working with the AWS workforce and utilizing SageMaker to develop their mannequin.
Within the proof of idea, we needed to hurry up a coaching job through the use of the SageMaker DDP library, which is optimized for AWS infrastructure throughout distributed coaching. To vary from PyTorch DDP to SageMaker DDP, you merely have to declare the torch_smddp package deal and alter the backend to smddp, as proven within the following code:
To be taught extra concerning the SageMaker DDP library, check with SageMaker’s Data Parallelism Library.
Analyzing the causes of sluggish coaching pace with the SageMaker Debugger and Profiler
Step one in optimizing and accelerating a coaching workload includes understanding and diagnosing the place bottlenecks happen. For KT’s coaching job, we measured the coaching time per iteration of the info loader, ahead go, and backward go:
| 1 iter time – dataloader : 0.00053 sec, ahead : 7.77474 sec, backward: 1.58002 sec |
| 2 iter time – dataloader : 0.00063 sec, ahead : 0.67429 sec, backward: 24.74539 sec |
| 3 iter time – dataloader : 0.00061 sec, ahead : 0.90976 sec, backward: 8.31253 sec |
| 4 iter time – dataloader : 0.00060 sec, ahead : 0.60958 sec, backward: 30.93830 sec |
| 5 iter time – dataloader : 0.00080 sec, ahead : 0.83237 sec, backward: 8.41030 sec |
| 6 iter time – dataloader : 0.00067 sec, ahead : 0.75715 sec, backward: 29.88415 sec |
Wanting on the time in the usual output for every iteration, we noticed that the backward go’s run time fluctuated considerably from iteration to iteration. This variation is uncommon and may affect whole coaching time. To seek out the reason for this inconsistent coaching pace, we first tried to establish useful resource bottlenecks by using the System Monitor (SageMaker Debugger UI), which lets you debug coaching jobs on SageMaker Coaching and examine the standing of sources such because the managed coaching platform’s CPU, GPU, community, and I/O inside a set variety of seconds.
The SageMaker Debugger UI offers detailed and important information that may assist figuring out and diagnose bottlenecks in a coaching job. Particularly, the CPU utilization line chart and CPU/GPU utilization warmth map per occasion tables caught our eye.
Within the CPU utilization line chart, we seen that some CPUs had been getting used 100%.

Within the warmth map (the place darker colours point out larger utilization), we famous that just a few CPU cores had excessive utilization all through the coaching, whereas GPU utilization wasn’t persistently excessive over time.

From right here, we started to suspect that one of many causes for the sluggish coaching pace was a CPU bottleneck. We reviewed the coaching script code to see if something was inflicting the CPU bottleneck. Essentially the most suspicious half was the massive worth of num_workers within the information loader, so we modified this worth to 0 or 1 to scale back CPU utilization. We then ran the coaching job once more and checked the outcomes.
The next screenshots present the CPU utilization line chart, GPU utilization, and warmth map after mitigating the CPU bottleneck.
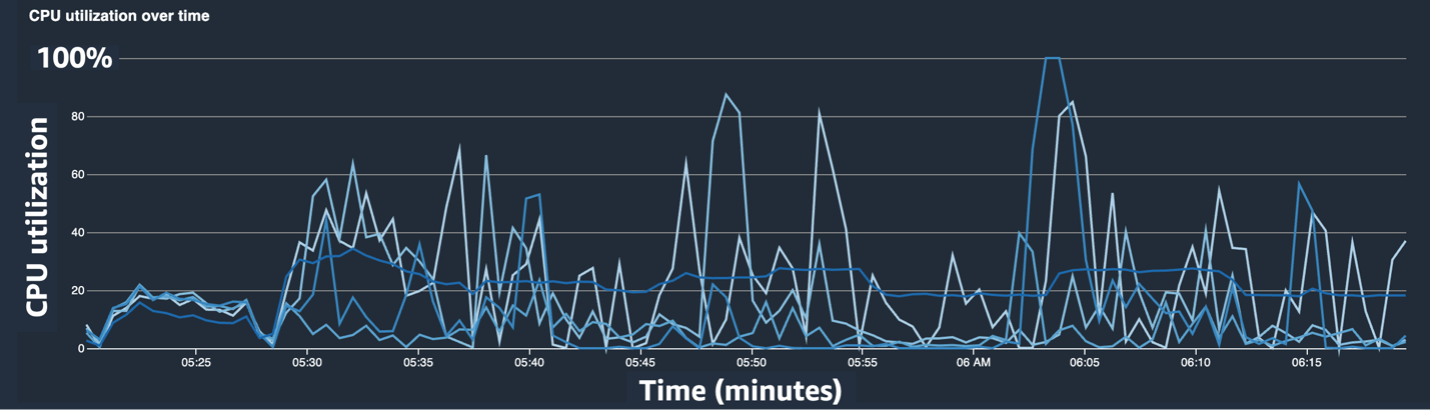


By merely altering num_workers, we noticed a major lower in CPU utilization and an general improve in GPU utilization. This was an vital change that improved coaching pace considerably. Nonetheless, we needed to see the place we may optimize GPU utilization. For this, we used SageMaker Profiler.
SageMaker Profiler helps establish optimization clues by offering visibility into utilization by operations, together with monitoring GPU and CPU utilization metrics and kernel consumption of GPU/CPU inside coaching scripts. It helps customers perceive which operations are consuming sources. First, to make use of SageMaker Profiler, it is advisable add ProfilerConfig to the operate that invokes the coaching job utilizing the SageMaker SDK, as proven within the following code:
Within the SageMaker Python SDK, you’ve gotten the flexibleness so as to add the annotate capabilities for SageMaker Profiler to pick code or steps within the coaching script that wants profiling. The next is an instance of the code that it’s best to declare for SageMaker Profiler within the coaching scripts:
After including the previous code, in case you run a coaching job utilizing the coaching scripts, you will get details about the operations consumed by the GPU kernel (as proven within the following determine) after the coaching runs for a time period. Within the case of KT’s coaching scripts, we ran it for one epoch and acquired the next outcomes.
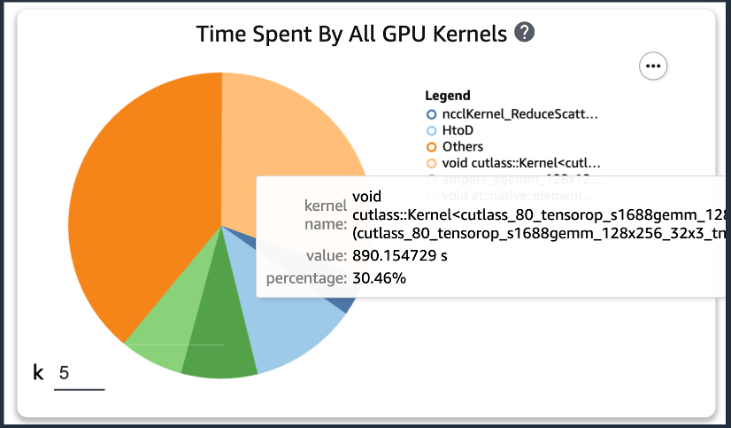
After we checked the highest 5 operation consumption occasions of the GPU kernel among the many outcomes of SageMaker Profiler, we discovered that for the KT coaching script, essentially the most time is consumed by the matrix product operation, which is a normal matrix multiplication (GEMM) operation on GPUs. With this vital perception from the SageMaker Profiler, we started investigating methods to speed up these operations and enhance GPU utilization.
Dashing up coaching time
We reviewed varied methods to scale back computation time of matrix multiplication and utilized two PyTorch capabilities.
Shard optimizer states with ZeroRedundancyOptimizer
Should you take a look at the Zero Redundancy Optimizer (ZeRO), the DeepSpeed/ZeRO approach permits the coaching of a giant mannequin effectively with higher coaching pace by eliminating the redundancies in reminiscence utilized by the mannequin. ZeroRedundancyOptimizer in PyTorch makes use of the strategy of sharding the optimizer state to scale back reminiscence utilization per a course of in Distributed Information Parallel (DDP). DDP makes use of synchronized gradients within the backward go so that every one optimizer replicas iterate over the identical parameters and gradient values, however as a substitute of getting all of the mannequin parameters, every optimizer state is maintained by sharding just for completely different DDP processes to scale back reminiscence utilization.
To make use of it, you may go away your present Optimizer in optimizer_class and declare a ZeroRedundancyOptimizer with the remainder of the mannequin parameters and the training fee as parameters.
Computerized blended precision
Automatic mixed precision (AMP) makes use of the torch.float32 information kind for some operations and torch.bfloat16 or torch.float16 for others, for the comfort of quick computation and diminished reminiscence utilization. Particularly, as a result of deep studying fashions are usually extra delicate to exponent bits than fraction bits of their computations, torch.bfloat16 is equal to the exponent bits of torch.float32, permitting them to be taught rapidly with minimal loss. torch.bfloat16 solely runs on cases with A100 NVIDIA structure (Ampere) or larger, similar to ml.p4d.24xlarge, ml.p4de.24xlarge, and ml.p5.48xlarge.
To use AMP, you may declare torch.cuda.amp.autocast within the coaching scripts as proven within the code above and declare dtype as torch.bfloat16.
Leads to SageMaker Profiler
After making use of the 2 capabilities to the coaching scripts and operating a prepare job for one epoch once more, we checked the highest 5 operations consumption occasions for the GPU kernel in SageMaker Profiler. The next determine reveals our outcomes.
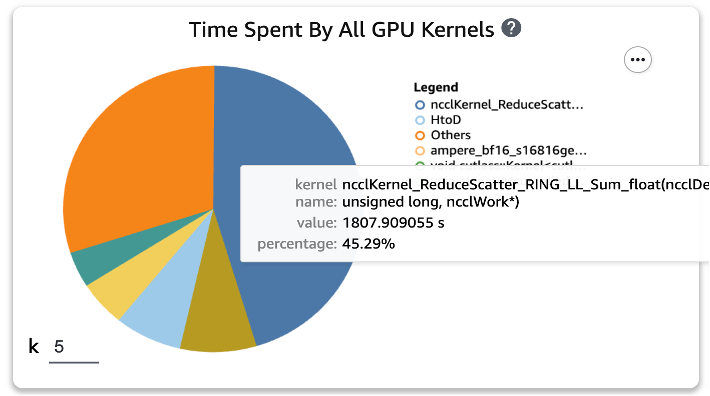
We are able to see that the GEMM operation, which was on the high of the checklist earlier than making use of the 2 Torch capabilities, has disappeared from the highest 5 operations, changed by the ReduceScatter operation, which generally happens in distributed coaching.
Coaching pace outcomes of the KT distilled mannequin
We elevated the coaching batch dimension by 128 extra to account for the reminiscence financial savings from making use of the 2 Torch capabilities, leading to a closing batch dimension of 1152 as a substitute of 1024. The coaching of the ultimate scholar mannequin was in a position to run 210 epochs per 1 day; the coaching time and speedup between KT’s inner coaching surroundings and SageMaker are summarized within the following desk.
| Coaching Atmosphere | Coaching GPU spec. | Variety of GPU | Coaching Time (hours) | Epoch | Hours per Epoch | Discount Ratio |
| KT’s inner coaching surroundings | A100 (80GB) | 2 | 960 | 300 | 3.20 | 29 |
| Amazon SageMaker | A100 (40GB) | 32 | 24 | 210 | 0.11 | 1 |
The scalability of AWS allowed us to finish the coaching job 29 occasions quicker than earlier than utilizing 32 GPUs as a substitute of two on premises. Consequently, utilizing extra GPUs on SageMaker would have considerably diminished coaching time with no distinction in general coaching prices.
Conclusion
Park Sang-min (Imaginative and prescient AI Serving Know-how Crew Chief) from the AI2XL Lab in KT’s Convergence Know-how Middle commented on the collaboration with AWS to develop the AI Meals Tag mannequin:
“Lately, as there are extra transformer-based fashions within the imaginative and prescient subject, the mannequin parameters and required GPU reminiscence are growing. We’re utilizing light-weight know-how to unravel this difficulty, and it takes quite a lot of time, a couple of month to be taught as soon as. Via this PoC with AWS, we had been in a position to establish the useful resource bottlenecks with assist of SageMaker Profiler and Debugger, resolve them, after which use SageMaker’s information parallelism library to finish the coaching in about at some point with optimized mannequin code on 4 ml.p4d.24xlarge cases.”
SageMaker helped save Sang-min’s workforce weeks of time in mannequin coaching and growth.
Primarily based on this collaboration on the imaginative and prescient mannequin, AWS and the SageMaker workforce will proceed to collaborate with KT on varied AI/ML analysis tasks to enhance mannequin growth and repair productiveness by way of making use of SageMaker capabilities.
To be taught extra about associated options in SageMaker, take a look at the next:
In regards to the authors
 Youngjoon Choi, AI/ML Skilled SA, has skilled enterprise IT in varied industries similar to manufacturing, high-tech, and finance as a developer, architect, and information scientist. He carried out analysis on machine studying and deep studying, particularly on subjects like hyperparameter optimization and area adaptation, presenting algorithms and papers. At AWS, he focuses on AI/ML throughout industries, offering technical validation utilizing AWS companies for distributed coaching/massive scale fashions and constructing MLOps. He proposes and critiques architectures, aiming to contribute to the growth of the AI/ML ecosystem.
Youngjoon Choi, AI/ML Skilled SA, has skilled enterprise IT in varied industries similar to manufacturing, high-tech, and finance as a developer, architect, and information scientist. He carried out analysis on machine studying and deep studying, particularly on subjects like hyperparameter optimization and area adaptation, presenting algorithms and papers. At AWS, he focuses on AI/ML throughout industries, offering technical validation utilizing AWS companies for distributed coaching/massive scale fashions and constructing MLOps. He proposes and critiques architectures, aiming to contribute to the growth of the AI/ML ecosystem.
 Jung Hoon Kim is an account SA of AWS Korea. Primarily based on experiences in purposes structure design, growth and methods modeling in varied industries similar to hi-tech, manufacturing, finance and public sector, he’s engaged on AWS Cloud journey and workloads optimization on AWS for enterprise clients.
Jung Hoon Kim is an account SA of AWS Korea. Primarily based on experiences in purposes structure design, growth and methods modeling in varied industries similar to hi-tech, manufacturing, finance and public sector, he’s engaged on AWS Cloud journey and workloads optimization on AWS for enterprise clients.
 Rock Sakong is a researcher at KT R&D. He has carried out analysis and growth for the imaginative and prescient AI in varied fields and primarily carried out facial attributes (gender/glasses, hats, and many others.)/face recognition know-how associated to the face. At the moment, he’s engaged on light-weight know-how for the imaginative and prescient fashions.
Rock Sakong is a researcher at KT R&D. He has carried out analysis and growth for the imaginative and prescient AI in varied fields and primarily carried out facial attributes (gender/glasses, hats, and many others.)/face recognition know-how associated to the face. At the moment, he’s engaged on light-weight know-how for the imaginative and prescient fashions.
 Manoj Ravi is a Senior Product Supervisor for Amazon SageMaker. He’s obsessed with constructing next-gen AI merchandise and works on software program and instruments to make large-scale machine studying simpler for purchasers. He holds an MBA from Haas College of Enterprise and a Masters in Info Programs Administration from Carnegie Mellon College. In his spare time, Manoj enjoys taking part in tennis and pursuing panorama pictures.
Manoj Ravi is a Senior Product Supervisor for Amazon SageMaker. He’s obsessed with constructing next-gen AI merchandise and works on software program and instruments to make large-scale machine studying simpler for purchasers. He holds an MBA from Haas College of Enterprise and a Masters in Info Programs Administration from Carnegie Mellon College. In his spare time, Manoj enjoys taking part in tennis and pursuing panorama pictures.
 Robert Van Dusen is a Senior Product Supervisor with Amazon SageMaker. He leads frameworks, compilers, and optimization methods for deep studying coaching.
Robert Van Dusen is a Senior Product Supervisor with Amazon SageMaker. He leads frameworks, compilers, and optimization methods for deep studying coaching.





