Retrieval-Augmented Era with LangChain, Amazon SageMaker JumpStart, and MongoDB Atlas semantic search
Generative AI fashions have the potential to revolutionize enterprise operations, however companies should rigorously take into account how one can harness their energy whereas overcoming challenges resembling safeguarding knowledge and making certain the standard of AI-generated content material.
The Retrieval-Augmented Era (RAG) framework augments prompts with exterior knowledge from a number of sources, resembling doc repositories, databases, or APIs, to make basis fashions efficient for domain-specific duties. This submit presents the capabilities of the RAG mannequin and highlights the transformative potential of MongoDB Atlas with its Vector Search characteristic.
MongoDB Atlas is an built-in suite of information providers that speed up and simplify the event of data-driven functions. Its vector knowledge retailer seamlessly integrates with operational knowledge storage, eliminating the necessity for a separate database. This integration permits highly effective semantic search capabilities by way of Vector Search, a quick approach to construct semantic search and AI-powered functions.
Amazon SageMaker permits enterprises to construct, practice, and deploy machine studying (ML) fashions. Amazon SageMaker JumpStart gives pre-trained fashions and knowledge that will help you get began with ML. You may entry, customise, and deploy pre-trained fashions and knowledge by way of the SageMaker JumpStart touchdown web page in Amazon SageMaker Studio with only a few clicks.
Amazon Lex is a conversational interface that helps companies create chatbots and voice bots that have interaction in pure, lifelike interactions. By integrating Amazon Lex with generative AI, companies can create a holistic ecosystem the place consumer enter seamlessly transitions into coherent and contextually related responses.
Resolution overview
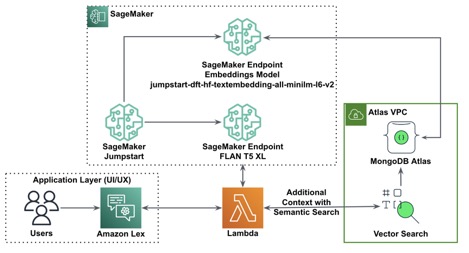
The next diagram illustrates the answer structure.

Within the following sections, we stroll by way of the steps to implement this resolution and its elements.
Arrange a MongoDB cluster
To create a free tier MongoDB Atlas cluster, comply with the directions in Create a Cluster. Arrange the database access and community access.
Deploy the SageMaker embedding mannequin
You may select the embedding mannequin (ALL MiniLM L6 v2) on the SageMaker JumpStart Fashions, notebooks, options web page.

Select Deploy to deploy the mannequin.
Confirm the mannequin is efficiently deployed and confirm the endpoint is created.

Vector embedding
Vector embedding is a technique of changing a textual content or picture right into a vector illustration. With the next code, we will generate vector embeddings with SageMaker JumpStart and replace the gathering with the created vector for each doc:
payload = {"text_inputs": [document[field_name_to_be_vectorized]]}
query_response = query_endpoint_with_json_payload(json.dumps(payload).encode('utf-8'))
embeddings = parse_response_multiple_texts(query_response)
# replace the doc
replace = {'$set': {vector_field_name : embeddings[0]}}
assortment.update_one(question, replace)The code above reveals how one can replace a single object in a group. To replace all objects comply with the instructions.
MongoDB vector knowledge retailer
MongoDB Atlas Vector Search is a brand new characteristic that permits you to retailer and search vector knowledge in MongoDB. Vector knowledge is a sort of information that represents some extent in a high-dimensional area. The sort of knowledge is commonly utilized in ML and synthetic intelligence functions. MongoDB Atlas Vector Search makes use of a way known as k-nearest neighbors (k-NN) to seek for comparable vectors. k-NN works by discovering the okay most comparable vectors to a given vector. Probably the most comparable vectors are those which can be closest to the given vector by way of the Euclidean distance.
Storing vector knowledge subsequent to operational knowledge can enhance efficiency by decreasing the necessity to transfer knowledge between totally different storage methods. That is particularly useful for functions that require real-time entry to vector knowledge.
Create a Vector Search index
The subsequent step is to create a MongoDB Vector Search index on the vector discipline you created within the earlier step. MongoDB makes use of the knnVector sort to index vector embeddings. The vector discipline must be represented as an array of numbers (BSON int32, int64, or double knowledge varieties solely).
Consult with Review knnVector Type Limitations for extra details about the restrictions of the knnVector sort.
The next code is a pattern index definition:
{
"mappings": {
"dynamic": true,
"fields": {
"egVector": {
"dimensions": 384,
"similarity": "euclidean",
"sort": "knnVector"
}
}
}
}
Be aware that the dimension should match you embeddings mannequin dimension.
Question the vector knowledge retailer
You may question the vector knowledge retailer utilizing the Vector Search aggregation pipeline. It makes use of the Vector Search index and performs a semantic search on the vector knowledge retailer.
The next code is a pattern search definition:
{
$search: {
"index": "<index identify>", // elective, defaults to "default"
"knnBeta": {
"vector": [<array-of-numbers>],
"path": "<field-to-search>",
"filter": {<filter-specification>},
"okay": <quantity>,
"rating": {<choices>}
}
}
}
Deploy the SageMaker massive language mannequin
SageMaker JumpStart foundation models are pre-trained massive language fashions (LLMs) which can be used to resolve a wide range of pure language processing (NLP) duties, resembling textual content summarization, query answering, and pure language inference. They’re obtainable in a wide range of sizes and configurations. On this resolution, we use the Hugging Face FLAN-T5-XL mannequin.
Seek for the FLAN-T5-XL mannequin in SageMaker JumpStart.

Select Deploy to arrange the FLAN-T5-XL mannequin.

Confirm the mannequin is deployed efficiently and the endpoint is lively.

Create an Amazon Lex bot
To create an Amazon Lex bot, full the next steps:
- On the Amazon Lex console, select Create bot.

- For Bot identify, enter a reputation.
- For Runtime position, choose Create a task with primary Amazon Lex permissions.

- Specify your language settings, then select Completed.

- Add a pattern utterance within the
NewIntentUI and select Save intent.
- Navigate to the
FallbackIntentthat was created for you by default and toggle Energetic within the Achievement part.
- Select Construct and after the construct is profitable, select Check.

- Earlier than testing, select the gear icon.

- Specify the AWS Lambda perform that may work together with MongoDB Atlas and the LLM to offer responses. To create the lambda perform comply with these steps.

- Now you can work together with the LLM.
Clear up
To scrub up your assets, full the next steps:
- Delete the Amazon Lex bot.
- Delete the Lambda perform.
- Delete the LLM SageMaker endpoint.
- Delete the embeddings mannequin SageMaker endpoint.
- Delete the MongoDB Atlas cluster.
Conclusion
Within the submit, we confirmed how one can create a easy bot that makes use of MongoDB Atlas semantic search and integrates with a mannequin from SageMaker JumpStart. This bot permits you to rapidly prototype consumer interplay with totally different LLMs in SageMaker Jumpstart whereas pairing them with the context originating in MongoDB Atlas.
As at all times, AWS welcomes suggestions. Please depart your suggestions and questions within the feedback part.
Concerning the authors

Igor Alekseev is a Senior Companion Resolution Architect at AWS in Information and Analytics area. In his position Igor is working with strategic companions serving to them construct advanced, AWS-optimized architectures. Prior becoming a member of AWS, as a Information/Resolution Architect he carried out many tasks in Huge Information area, together with a number of knowledge lakes in Hadoop ecosystem. As a Information Engineer he was concerned in making use of AI/ML to fraud detection and workplace automation.
 Babu Srinivasan is a Senior Companion Options Architect at MongoDB. In his present position, he’s working with AWS to construct the technical integrations and reference architectures for the AWS and MongoDB options. He has greater than 20 years of expertise in Database and Cloud applied sciences . He’s obsessed with offering technical options to clients working with a number of World System Integrators(GSIs) throughout a number of geographies.
Babu Srinivasan is a Senior Companion Options Architect at MongoDB. In his present position, he’s working with AWS to construct the technical integrations and reference architectures for the AWS and MongoDB options. He has greater than 20 years of expertise in Database and Cloud applied sciences . He’s obsessed with offering technical options to clients working with a number of World System Integrators(GSIs) throughout a number of geographies.






