Scaling multimodal understanding to lengthy movies – Google Analysis Weblog

When constructing machine studying fashions for real-life functions, we have to contemplate inputs from a number of modalities to be able to seize numerous elements of the world round us. For instance, audio, video, and textual content all present assorted and complementary details about a visible enter. Nevertheless, constructing multimodal fashions is difficult because of the heterogeneity of the modalities. A few of the modalities is perhaps effectively synchronized in time (e.g., audio, video) however not aligned with textual content. Moreover, the massive quantity of information in video and audio alerts is way bigger than that in textual content, so when combining them in multimodal fashions, video and audio typically can’t be totally consumed and have to be disproportionately compressed. This drawback is exacerbated for longer video inputs.
In “Mirasol3B: A Multimodal Autoregressive model for time-aligned and contextual modalities”, we introduce a multimodal autoregressive mannequin (Mirasol3B) for studying throughout audio, video, and textual content modalities. The primary thought is to decouple the multimodal modeling into separate centered autoregressive fashions, processing the inputs in line with the traits of the modalities. Our mannequin consists of an autoregressive part for the time-synchronized modalities (audio and video) and a separate autoregressive part for modalities that aren’t essentially time-aligned however are nonetheless sequential, e.g., textual content inputs, similar to a title or description. Moreover, the time-aligned modalities are partitioned in time the place native options might be collectively realized. On this manner, audio-video inputs are modeled in time and are allotted comparatively extra parameters than prior works. With this method, we will effortlessly deal with for much longer movies (e.g., 128-512 frames) in comparison with different multimodal fashions. At 3B parameters, Mirasol3B is compact in comparison with prior Flamingo (80B) and PaLI-X (55B) fashions. Lastly, Mirasol3B outperforms the state-of-the-art approaches on video question answering (video QA), lengthy video QA, and audio-video-text benchmarks.
 |
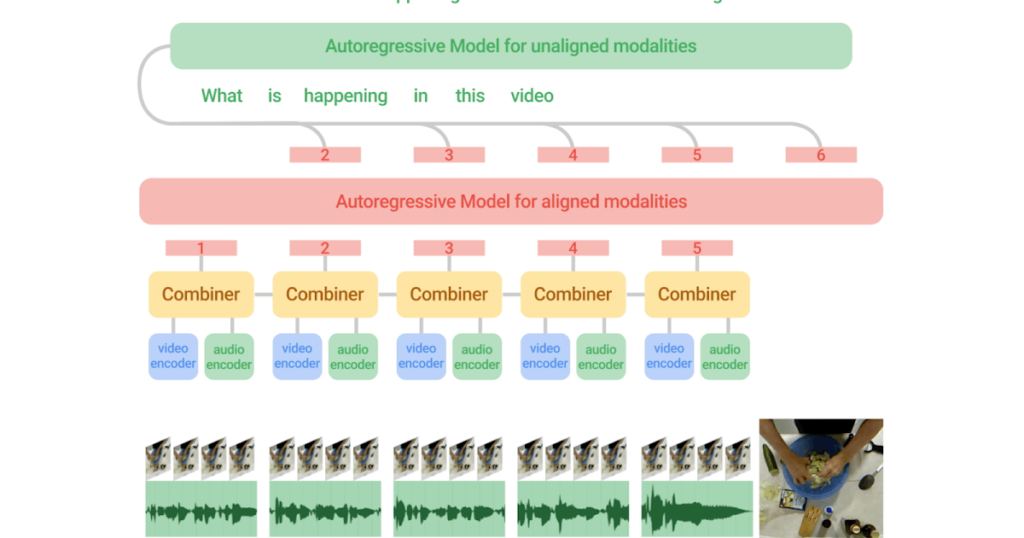
| The Mirasol3B structure consists of an autoregressive mannequin for the time-aligned modalities (audio and video), that are partitioned in chunks, and a separate autoregressive mannequin for the unaligned context modalities (e.g., textual content). Joint function studying is performed by the Combiner, which learns compact however sufficiently informative options, permitting the processing of lengthy video/audio inputs. |
Coordinating time-aligned and contextual modalities
Video, audio and textual content are numerous modalities with distinct traits. For instance, video is a spatio-temporal visible sign with 30–100 frames per second, however because of the giant quantity of information, usually solely 32–64 frames per video are consumed by present fashions. Audio is a one-dimensional temporal sign obtained at a lot increased frequency than video (e.g., at 16 Hz), whereas textual content inputs that apply to the entire video, are usually 200–300 word-sequence and function a context to the audio-video inputs. To that finish, we suggest a mannequin consisting of an autoregressive part that fuses and collectively learns the time-aligned alerts, which happen at excessive frequencies and are roughly synchronized, and one other autoregressive part for processing non-aligned alerts. Studying between the elements for the time-aligned and contextual modalities is coordinated through cross-attention mechanisms that permit the 2 to trade info whereas studying in a sequence with out having to synchronize them in time.
Time-aligned autoregressive modeling of video and audio
Lengthy movies can convey wealthy info and actions occurring in a sequence. Nevertheless, current fashions method video modeling by extracting all the knowledge without delay, with out enough temporal info. To deal with this, we apply an autoregressive modeling technique the place we situation collectively realized video and audio representations for one time interval on function representations from earlier time intervals. This preserves temporal info.
The video is first partitioned into smaller video chunks. Every chunk itself might be 4–64 frames. The options corresponding to every chunk are then processed by a studying module, known as the Combiner (described under), which generates a joint audio and video function illustration on the present step — this step extracts and compacts a very powerful info per chunk. Subsequent, we course of this joint function illustration with an autoregressive Transformer, which applies consideration to the earlier function illustration and generates the joint function illustration for the following step. Consequently, the mannequin learns how one can symbolize not solely every particular person chunk, but additionally how the chunks relate temporally.
 |
| We use an autoregressive modeling of the audio and video inputs, partitioning them in time and studying joint function representations, that are then autoregressively realized in sequence. |
Modeling lengthy movies with a modality combiner
To mix the alerts from the video and audio info in every video chunk, we suggest a studying module known as the Combiner. Video and audio alerts are aligned by taking the audio inputs that correspond to a selected video timeframe. We then course of video and audio inputs spatio-temporally, extracting info significantly related to adjustments within the inputs (for movies we use sparse video tubes, and for audio we apply the spectrogram illustration, each of that are processed by a Vision Transformer). We concatenate and enter these options to the Combiner, which is designed to study a brand new function illustration capturing each these inputs. To deal with the problem of the massive quantity of information in video and audio alerts, one other purpose of the Combiner is to scale back the dimensionality of the joint video/audio inputs, which is completed by choosing a smaller variety of output options to be produced. The Combiner might be applied merely as a causal Transformer, which processes the inputs within the route of time, i.e., utilizing solely inputs of the prior steps or the present one. Alternatively, the Combiner can have a learnable reminiscence, described under.
Combiner types
A easy model of the Combiner adapts a Transformer structure. Extra particularly, all audio and video options from the present chunk (and optionally prior chunks) are enter to a Transformer and projected to a decrease dimensionality, i.e., a smaller variety of options are chosen because the output “mixed” options. Whereas Transformers will not be usually used on this context, we discover it efficient for lowering the dimensionality of the enter options, by choosing the final m outputs of the Transformer, if m is the specified output dimension (proven under). Alternatively, the Combiner can have a reminiscence part. For instance, we use the Token Turing Machine (TTM), which helps a differentiable reminiscence unit, accumulating and compressing options from all earlier timesteps. Utilizing a hard and fast reminiscence permits the mannequin to work with a extra compact set of options at each step, relatively than course of all of the options from earlier steps, which reduces computation.
 |
| We use a easy Transformer-based Combiner (left) and a Reminiscence Combiner (proper), primarily based on the Token Turing Machine (TTM), which makes use of reminiscence to compress earlier historical past of options. |
Outcomes
We consider our method on a number of benchmarks, MSRVTT-QA, ActivityNet-QA and NeXT-QA, for the video QA process, the place a text-based query a few video is issued and the mannequin must reply. This evaluates the power of the mannequin to know each the text-based query and video content material, and to type a solution, specializing in solely related info. Of those benchmarks, the latter two goal lengthy video inputs and have extra complicated questions.
We additionally consider our method within the more difficult open-ended textual content technology setting, whereby the mannequin generates the solutions in an unconstrained trend as free type textual content, requiring an actual match to the bottom fact reply. Whereas this stricter analysis counts synonyms as incorrect, it might higher replicate a mannequin’s capacity to generalize.
Our outcomes point out improved efficiency over state-of-the-art approaches for many benchmarks, together with all with open-ended technology analysis — notable contemplating our mannequin is just 3B parameters, significantly smaller than prior approaches, e.g., Flamingo 80B. We used solely video and textual content inputs to be similar to different work. Importantly, our mannequin can course of 512 frames while not having to extend the mannequin parameters, which is essential for dealing with longer movies. Lastly with the TTM Combiner, we see each higher or comparable efficiency whereas lowering compute by 18%.
 |
| Outcomes on NeXT-QA benchmark, which options lengthy movies for the video QA process. |
Outcomes on audio-video benchmarks
Outcomes on the favored audio-video datasets VGG-Sound and EPIC-SOUNDS are proven under. Since these benchmarks are classification-only, we deal with them as an open-ended textual content generative setting the place our mannequin produces the textual content of the specified class; e.g., for the category ID equivalent to the “taking part in drums” exercise, we anticipate the mannequin to generate the textual content “taking part in drums”. In some circumstances our method outperforms the prior state-of-the-art by giant margins, though our mannequin outputs the leads to the generative open-ended setting.
 |
| Outcomes on the VGG-Sound (audio-video QA) dataset. |
Advantages of autoregressive modeling
We conduct an ablation examine evaluating our method to a set of baselines that use the identical enter info however with commonplace strategies (i.e., with out autoregression and the Combiner). We additionally examine the results of pre-training. As a result of commonplace strategies are ill-suited for processing longer video, this experiment is performed for 32 frames and 4 chunks solely, throughout all settings for honest comparability. We see that Mirasol3B’s enhancements are nonetheless legitimate for comparatively brief movies.
 |
| Ablation experiments evaluating the principle elements of our mannequin. Utilizing the Combiner, the autoregressive modeling, and pre-training all enhance efficiency. |
Conclusion
We current a multimodal autoregressive mannequin that addresses the challenges related to the heterogeneity of multimodal information by coordinating the training between time-aligned and time-unaligned modalities. Time-aligned modalities are additional processed autoregressively in time with a Combiner, controlling the sequence size and producing highly effective representations. We show {that a} comparatively small mannequin can efficiently symbolize lengthy video and successfully mix with different modalities. We outperform the state-of-the-art approaches (together with some a lot greater fashions) on video- and audio-video query answering.
Acknowledgements
This analysis is co-authored by AJ Piergiovanni, Isaac Noble, Dahun Kim, Michael Ryoo, Victor Gomes, and Anelia Angelova. We thank Claire Cui, Tania Bedrax-Weiss, Abhijit Ogale, Yunhsuan Sung, Ching-Chung Chang, Marvin Ritter, Kristina Toutanova, Ming-Wei Chang, Ashish Thapliyal, Xiyang Luo, Weicheng Kuo, Aren Jansen, Bryan Seybold, Ibrahim Alabdulmohsin, Jialin Wu, Luke Friedman, Trevor Walker, Keerthana Gopalakrishnan, Jason Baldridge, Radu Soricut, Mojtaba Seyedhosseini, Alexander D’Amour, Oliver Wang, Paul Natsev, Tom Duerig, Younghui Wu, Slav Petrov, Zoubin Ghahramani for his or her assist and help. We additionally thank Tom Small for getting ready the animation.






