Google AI Proposes Straightforward Finish-to-Finish Diffusion-based Textual content to Speech E3-TTS: A Easy and Environment friendly Finish-to-Finish Textual content-to-Speech Mannequin Primarily based on Diffusion
In machine studying, a diffusion mannequin is a generative mannequin generally used for picture and audio technology duties. The diffusion mannequin makes use of a diffusion course of, remodeling a posh information distribution into less complicated distributions. The important thing benefit lies in its skill to generate high-quality outputs, notably in duties like picture and audio synthesis.
Within the context of text-to-speech (TTS) programs, the appliance of diffusion fashions has revealed notable enhancements in comparison with conventional TTS programs. This progress is due to its energy to deal with points encountered by current programs, resembling heavy reliance on the standard of intermediate options and the complexity related to deployment, coaching, and setup procedures.
A workforce of researchers from Google have formulated E3 TTS: Straightforward Finish-to-Finish Diffusion-based Textual content to Speech. This text-to-speech mannequin depends on the diffusion course of to keep up temporal construction. This method permits the mannequin to take plain textual content as enter and instantly produce audio waveforms.
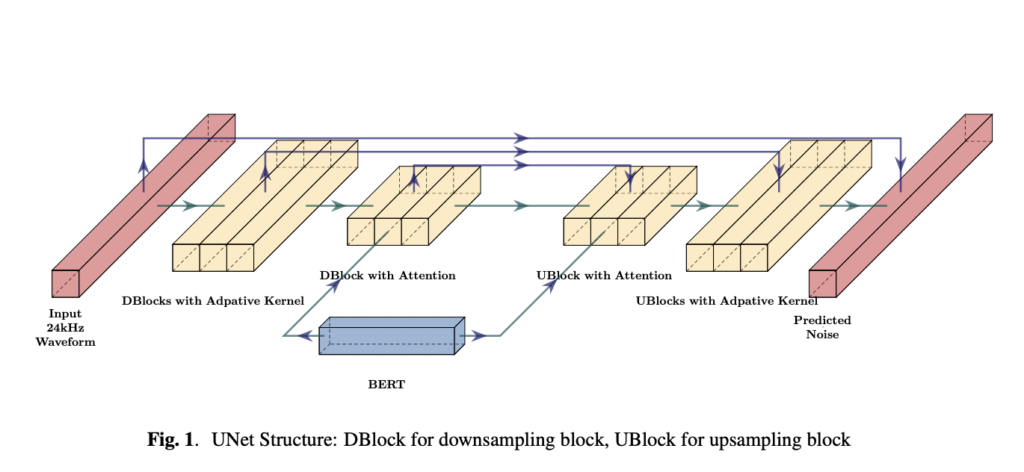
The E3 TTS mannequin effectively processes enter textual content in a non-autoregressive style, permitting it to output a waveform instantly with out requiring sequential processing. Moreover, the dedication of speaker id and alignment happens dynamically throughout diffusion. This mannequin consists of two main modules: A pre-trained BERT mannequin is employed to extract pertinent info from the enter textual content, and A diffusion UNet mannequin processes the output from BERT. It iteratively refines the preliminary noisy waveform, in the end predicting the ultimate uncooked waveform.
The E3 TTS employs an iterative refinement course of to generate an audio waveform. It fashions the temporal construction of the waveform utilizing the diffusion course of, permitting for versatile latent buildings inside the given audio with out the necessity for extra conditioning info.
It’s constructed upon a pre-trained BERT mannequin. Additionally, the system operates with out counting on speech representations like phonemes or graphemes. The BERT mannequin takes subword enter, and its output is processed by a 1D U-Web construction. It contains downsampling and upsampling blocks related by residual connections.
E3 TTS makes use of textual content representations from the pre-trained BERT mannequin, capitalizing on present developments in massive language fashions. The E3 TTS depends on a pretrained textual content language mannequin, streamlining the producing course of.
The system’s adaptability will increase as this mannequin will be educated in lots of languages utilizing textual content enter.
The U-Web construction employed in E3 TTS includes a sequence of downsampling and upsampling blocks related by residual connections. To enhance info extraction from the BERT output, cross-attention is included into the highest downsampling/upsampling blocks. An adaptive softmax Convolutional Neural Community (CNN) kernel is utilized within the decrease blocks, with its kernel dimension decided by the timestep and speaker. Speaker and timestep embeddings are mixed by way of Function-wise Linear Modulation (FiLM), which features a composite layer for channel-wise scaling and bias prediction.
The downsampler in E3 TTS performs a essential function in refining noisy info, changing it from 24kHz to a sequence of comparable size because the encoded BERT output, considerably enhancing total high quality. Conversely, the upsampler predicts noise with the identical size because the enter waveform.
In abstract, E3 TTS demonstrates the potential to generate high-fidelity audio, approaching a noteworthy high quality degree on this area.
Take a look at the Paper and Project Page. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to hitch our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI initiatives, and extra.
If you like our work, you will love our newsletter..
We’re additionally on Telegram and WhatsApp.
Rachit Ranjan is a consulting intern at MarktechPost . He’s at present pursuing his B.Tech from Indian Institute of Know-how(IIT) Patna . He’s actively shaping his profession within the area of Synthetic Intelligence and Information Science and is passionate and devoted for exploring these fields.



