Enhance LLM responses in RAG use circumstances by interacting with the consumer
Probably the most widespread purposes of generative AI and huge language fashions (LLMs) is answering questions primarily based on a selected exterior information corpus. Retrieval-Augmented Technology (RAG) is a well-liked approach for constructing query answering techniques that use an exterior information base. To study extra, consult with Build a powerful question answering bot with Amazon SageMaker, Amazon OpenSearch Service, Streamlit, and LangChain.
Conventional RAG techniques typically wrestle to offer passable solutions when customers ask imprecise or ambiguous questions with out offering ample context. This results in unhelpful responses like “I don’t know” or incorrect, made-up solutions offered by an LLM. On this submit, we display an answer to enhance the standard of solutions in such use circumstances over conventional RAG techniques by introducing an interactive clarification part utilizing LangChain.
The important thing thought is to allow the RAG system to interact in a conversational dialogue with the consumer when the preliminary query is unclear. By asking clarifying questions, prompting the consumer for extra particulars, and incorporating the brand new contextual data, the RAG system can collect the required context to offer an correct, useful reply—even from an ambiguous preliminary consumer question.
Answer overview
To display our resolution, we’ve arrange an Amazon Kendra index (composed of the AWS on-line documentation for Amazon Kendra, Amazon Lex, and Amazon SageMaker), a LangChain agent with an Amazon Bedrock LLM, and a simple Streamlit consumer interface.
Stipulations
To run this demo in your AWS account, full the next stipulations:
- Clone the GitHub repository and observe the steps defined within the README.
- Deploy an Amazon Kendra index in your AWS account. You need to use the next AWS CloudFormation template to create a brand new index or use an already working index. Deploying a brand new index would possibly add extra prices to your invoice, subsequently we advocate deleting it should you don’t longer want it. Be aware that the information inside the index shall be despatched to the chosen Amazon Bedrock basis mannequin (FM).
- The LangChain agent depends on FMs accessible in Amazon Bedrock, however this may be tailored to another LLM that LangChain helps.
- To experiment with the pattern entrance finish shared with the code, you need to use Amazon SageMaker Studio to run a neighborhood deployment of the Streamlit app. Be aware that working this demo will incur some extra prices.
Implement the answer
Conventional RAG brokers are sometimes designed as follows. The agent has entry to a instrument that’s used to retrieve paperwork related to a consumer question. The retrieved paperwork are then inserted into the LLM immediate, in order that the agent can present a solution primarily based on the retrieved doc snippets.
On this submit, we implement an agent that has entry to KendraRetrievalTool and derives related paperwork from the Amazon Kendra index and gives the reply given the retrieved context:
Seek advice from the GitHub repo for the total implementation code. To study extra about conventional RAG use circumstances, consult with Question answering using Retrieval Augmented Generation with foundation models in Amazon SageMaker JumpStart.
Take into account the next instance. A consumer asks “What number of GPUs does my EC2 occasion have?” As proven within the following screenshot, the agent is searching for the reply utilizing KendraRetrievalTool. Nevertheless, the agent realizes it doesn’t know which Amazon Elastic Compute Cloud (Amazon EC2) occasion kind the consumer is referencing and subsequently gives no useful reply to the consumer, resulting in a poor buyer expertise.

To handle this drawback, we outline an extra customized instrument referred to as AskHumanTool and supply it to the agent. The instrument instructs an LLM to learn the consumer query and ask a follow-up query to the consumer if KendraRetrievalTool just isn’t capable of return reply. This means that the agent will now have two instruments at its disposal:
This enables the agent to both refine the query or present extra context that’s wanted to answer the immediate. To information the agent to make use of AskHumanTool for this function, we offer the next instrument description to the LLM:
Use this instrument should you don’t discover a solution utilizing the KendraRetrievalTool. Ask the human to make clear the query or present the lacking data. The enter ought to be a query for the human.
As illustrated within the following screenshot, through the use of AskHumanTool, the agent is now figuring out imprecise consumer questions and returning a follow-up query to the consumer asking to specify what EC2 occasion kind is getting used.

After the consumer has specified the occasion kind, the agent is incorporating the extra reply into the context for the unique query, earlier than deriving the proper reply.

Be aware that the agent can now determine whether or not to make use of KendraRetrievalTool to retrieve the related paperwork or ask a clarifying query utilizing AskHumanTool. The agent’s choice relies on whether or not it finds the doc snippets inserted into the immediate ample to offer the ultimate reply. This flexibility permits the RAG system to assist totally different queries a consumer could submit, together with each well-formulated and imprecise questions.
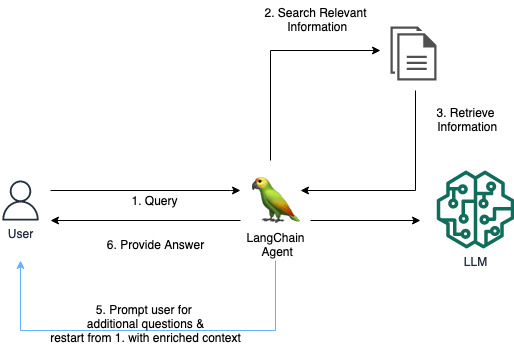
In our instance, the total agent workflow is as follows:
- The consumer makes a request to the RAG app, asking “What number of GPUs does my EC2 occasion have?”
- The agent makes use of the LLM to determine what motion to take: Discover related data to reply the consumer’s request by calling the
KendraRetrievalTool. - The agent retrieves data from the Amazon Kendra index utilizing the instrument. The snippets from the retrieved paperwork are inserted into the agent immediate.
- The LLM (of the agent) derives that the retrieved paperwork from Amazon Kendra aren’t useful or don’t comprise sufficient context to offer a solution to the consumer’s request.
- The agent makes use of
AskHumanToolto formulate a follow-up query: “What’s the particular EC2 occasion kind you might be utilizing? Realizing the occasion kind would assist reply what number of GPUs it has.” The consumer gives the reply “ml.g5.12xlarge,” and the agent callsKendraRetrievalToolonce more, however this time including the EC2 occasion kind into the search question. - After working via Steps 2–4 once more, the agent derives a helpful reply and sends it again to the consumer.
The next diagram illustrates this workflow.
The instance described on this submit illustrates how the addition of the customized AskHumanTool permits the agent to request clarifying particulars when wanted. This may enhance the reliability and accuracy of the responses, resulting in a greater buyer expertise in a rising variety of RAG purposes throughout totally different domains.
Clear up
To keep away from incurring pointless prices, delete the Amazon Kendra index should you’re not utilizing it anymore and shut down the SageMaker Studio occasion should you used it to run the demo.
Conclusion
On this submit, we confirmed the best way to allow a greater buyer expertise for the customers of a RAG system by including a customized instrument that allows the system to ask a consumer for a lacking piece of knowledge. This interactive conversational strategy represents a promising route for bettering conventional RAG architectures. The power to resolve vagueness via a dialogue can result in delivering extra passable solutions from a information base.
Be aware that this strategy just isn’t restricted to RAG use circumstances; you need to use it in different generative AI use circumstances that depend upon an agent at its core, the place a customized AskHumanTool may be added.
For extra details about utilizing Amazon Kendra with generative AI, consult with Quickly build high-accuracy Generative AI applications on enterprise data using Amazon Kendra, LangChain, and large language models.
Concerning the authors
 Antonia Wiebeler is a Information Scientist on the AWS Generative AI Innovation Heart, the place she enjoys constructing proofs of idea for purchasers. Her ardour is exploring how generative AI can resolve real-world issues and create worth for purchasers. Whereas she just isn’t coding, she enjoys working and competing in triathlons.
Antonia Wiebeler is a Information Scientist on the AWS Generative AI Innovation Heart, the place she enjoys constructing proofs of idea for purchasers. Her ardour is exploring how generative AI can resolve real-world issues and create worth for purchasers. Whereas she just isn’t coding, she enjoys working and competing in triathlons.
 Nikita Kozodoi is an Utilized Scientist on the AWS Generative AI Innovation Heart, the place he develops ML options to unravel buyer issues throughout industries. In his function, he focuses on advancing generative AI to deal with real-world challenges. In his spare time, he loves taking part in seashore volleyball and studying.
Nikita Kozodoi is an Utilized Scientist on the AWS Generative AI Innovation Heart, the place he develops ML options to unravel buyer issues throughout industries. In his function, he focuses on advancing generative AI to deal with real-world challenges. In his spare time, he loves taking part in seashore volleyball and studying.





