Grammar checking at Google Search scale – Google Analysis Weblog
Many individuals with questions on grammar flip to Google Seek for steerage. Whereas current options, akin to “Did you imply”, already deal with easy typo corrections, extra advanced grammatical error correction (GEC) is past their scope. What makes the event of recent Google Search options difficult is that they will need to have excessive precision and recall whereas outputting outcomes quickly.
The traditional strategy to GEC is to deal with it as a translation problem and use autoregressive Transformer fashions to decode the response token-by-token, conditioning on the beforehand generated tokens. Nonetheless, though Transformer fashions have confirmed to be efficient at GEC, they aren’t significantly environment friendly as a result of the era can’t be parallelized as a result of autoregressive decoding. Usually, just a few modifications are wanted to make the enter textual content grammatically right, so one other attainable resolution is to deal with GEC as a text editing drawback. If we may run the autoregressive decoder solely to generate the modifications, that might considerably lower the latency of the GEC mannequin.
To this finish, in “EdiT5: Semi-Autoregressive Text-Editing with T5 Warm-Start”, printed at Findings of EMNLP 2022, we describe a novel text-editing mannequin that’s primarily based on the T5 Transformer encoder-decoder structure. EdiT5 powers the brand new Google Search grammar check feature that lets you verify if a phrase or sentence is grammatically right and offers corrections when wanted. Grammar verify exhibits up when the phrase “grammar verify” is included in a search question, and if the underlying mannequin is assured in regards to the correction. Moreover, it exhibits up for some queries that don’t include the “grammar verify” phrase when Search understands that’s the probably intent.
 |
Mannequin structure
For low-latency purposes at Google, Transformer fashions are usually run on TPUs. As a result of their quick matrix multiplication models (MMUs), these gadgets are optimized for performing giant matrix multiplications rapidly, for instance working a Transformer encoder on a whole lot of tokens in just a few milliseconds. In distinction, Transformer decoding makes poor use of a TPU’s capabilities, as a result of it forces it to course of just one token at a time. This makes autoregressive decoding probably the most time-consuming a part of a translation-based GEC mannequin.
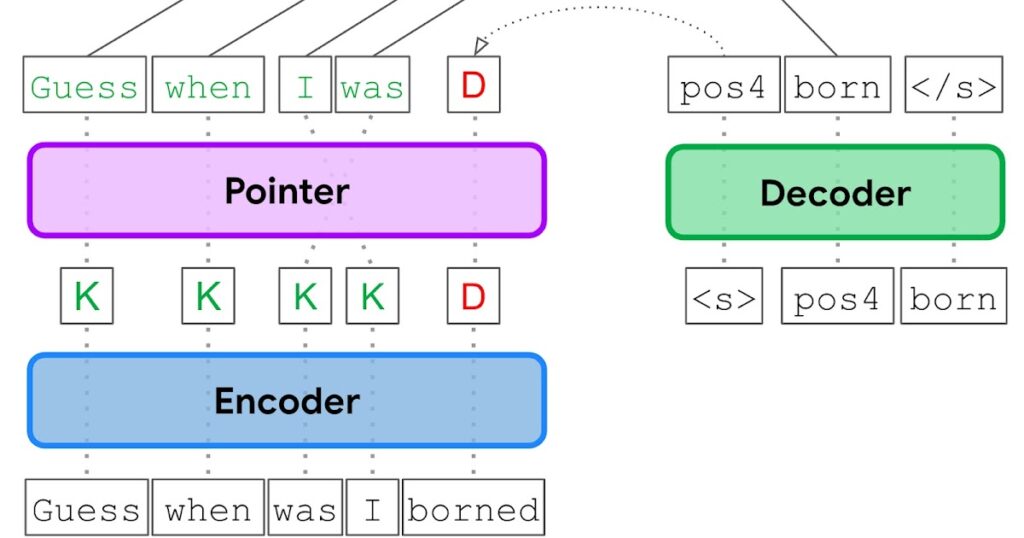
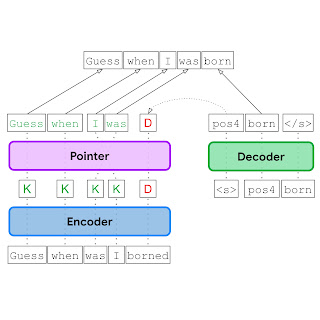
Within the EdiT5 strategy, we cut back the variety of decoding steps by treating GEC as a textual content enhancing drawback. The EdiT5 text-editing mannequin relies on the T5 Transformer encoder-decoder structure with a couple of essential modifications. Given an enter with grammatical errors, the EdiT5 mannequin makes use of an encoder to find out which enter tokens to maintain or delete. The saved enter tokens type a draft output, which is optionally reordered utilizing a non-autoregressive pointer network. Lastly, a decoder outputs the tokens which can be lacking from the draft, and makes use of a pointing mechanism to point the place every new token must be positioned to generate a grammatically right output. The decoder is just run to provide tokens that have been lacking within the draft, and in consequence, runs for a lot fewer steps than could be wanted within the translation strategy to GEC.
To additional lower the decoder latency, we cut back the decoder right down to a single layer, and we compensate by growing the scale of the encoder. Total, this decreases latency considerably as a result of the additional work within the encoder is effectively parallelized.
 |
| Given an enter with grammatical errors (“Guess when was I borned”), the EdiT5 mannequin makes use of an encoder to find out which enter tokens to maintain (Ok) or delete (D), a pointer community (pointer) to reorder saved tokens, and a decoder to insert any new tokens which can be wanted to generate a grammatically right output. |
We utilized the EdiT5 mannequin to the public BEA grammatical error correction benchmark, evaluating totally different mannequin sizes. The experimental outcomes present that an EdiT5 giant mannequin with 391M parameters yields a better F0.5 score, which measures the accuracy of the corrections, whereas delivering a 9x speedup in comparison with a T5 base mannequin with 248M parameters. The imply latency of the EdiT5 mannequin was merely 4.1 milliseconds.
 |
| Efficiency of the T5 and EdiT5 fashions of assorted sizes on the general public BEA GEC benchmark plotted in opposition to imply latency. In comparison with T5, EdiT5 presents a greater latency-F0.5 trade-off. Word that the x axis is logarithmic. |
Improved coaching information with giant language fashions
Our earlier research, in addition to the outcomes above, present that mannequin dimension performs an important function in producing correct grammatical corrections. To mix the benefits of giant language fashions (LLMs) and the low latency of EdiT5, we leverage a way known as hard distillation. First, we prepare a trainer LLM utilizing related datasets used for the Gboard grammar model. The trainer mannequin is then used to generate coaching information for the coed EdiT5 mannequin.
Coaching units for grammar fashions include ungrammatical supply / grammatical goal sentence pairs. A number of the coaching units have noisy targets that include grammatical errors, pointless paraphrasing, or undesirable artifacts. Subsequently, we generate new pseudo-targets with the trainer mannequin to get cleaner and extra constant coaching information. Then, we re-train the trainer mannequin with the pseudo-targets utilizing a way known as self-training. Lastly, we discovered that when the supply sentence incorporates many errors, the trainer generally corrects solely a part of the errors. Thus, we are able to additional enhance the standard of the pseudo-targets by feeding them to the trainer LLM for a second time, a way known as iterative refinement.
 |
| Steps for coaching a big trainer mannequin for grammatical error correction (GEC). Self-training and iterative refinement take away pointless paraphrasing, artifacts, and grammatical errors showing within the authentic targets. |
Placing all of it collectively
Utilizing the improved GEC information, we prepare two EdiT5-based fashions: a grammatical error correction mannequin, and a grammaticality classifier. When the grammar verify function is used, we run the question first via the correction mannequin, after which we verify if the output is certainly right with the classifier mannequin. Solely then will we floor the correction to the consumer.
The rationale to have a separate classifier mannequin is to extra simply commerce off between precision and recall. Moreover, for ambiguous or nonsensical queries to the mannequin the place one of the best correction is unclear, the classifier reduces the danger of serving inaccurate or complicated corrections.
Conclusion
We’ve developed an environment friendly grammar correction mannequin primarily based on the state-of-the-art EdiT5 mannequin structure. This mannequin permits customers to verify for the grammaticality of their queries in Google Search by together with the “grammar verify” phrase within the question.
Acknowledgements
We gratefully acknowledge the important thing contributions of the opposite crew members, together with Akash R, Aliaksei Severyn, Harsh Shah, Jonathan Mallinson, Mithun Kumar S R, Samer Hassan, Sebastian Krause, and Shikhar Thakur. We’d additionally prefer to thank Felix Stahlberg, Shankar Kumar, and Simon Tong for useful discussions and pointers.





