Dialogue-guided visible language processing with Amazon SageMaker JumpStart

Visible language processing (VLP) is on the forefront of generative AI, driving developments in multimodal studying that encompasses language intelligence, imaginative and prescient understanding, and processing. Mixed with massive language fashions (LLM) and Contrastive Language-Picture Pre-Coaching (CLIP) skilled with a big amount of multimodality knowledge, visible language fashions (VLMs) are notably adept at duties like picture captioning, object detection and segmentation, and visible query answering. Their use instances span numerous domains, from media leisure to medical diagnostics and high quality assurance in manufacturing.
Key strengths of VLP embody the efficient utilization of pre-trained VLMs and LLMs, enabling zero-shot or few-shot predictions with out necessitating task-specific modifications, and categorizing photographs from a broad spectrum by informal multi-round dialogues. Augmented by Grounded Segment Anything, VLP displays prowess in visible recognition, with object detection and segmentation being notably notable. The potential exists to fine-tune VLMs and LLMs additional utilizing domain-specific knowledge, aiming to spice up precision and mitigate hallucination. Nevertheless, like different nascent applied sciences, obstacles stay in managing mannequin intricacy, harmonizing numerous modalities, and formulating uniform analysis metrics.
Courtesy of NOMIC for OBELICS, HuggingFaceM4 for IDEFICS, Charles Bensimon for Gradio and Amazon Polly for TTS
On this publish, we discover the technical nuances of VLP prototyping utilizing Amazon SageMaker JumpStart along with modern generative AI fashions. By way of multi-round dialogues, we spotlight the capabilities of instruction-oriented zero-shot and few-shot imaginative and prescient language processing, emphasizing its versatility and aiming to seize the curiosity of the broader multimodal group. The demo implementation code is offered within the following GitHub repo.
Resolution overview
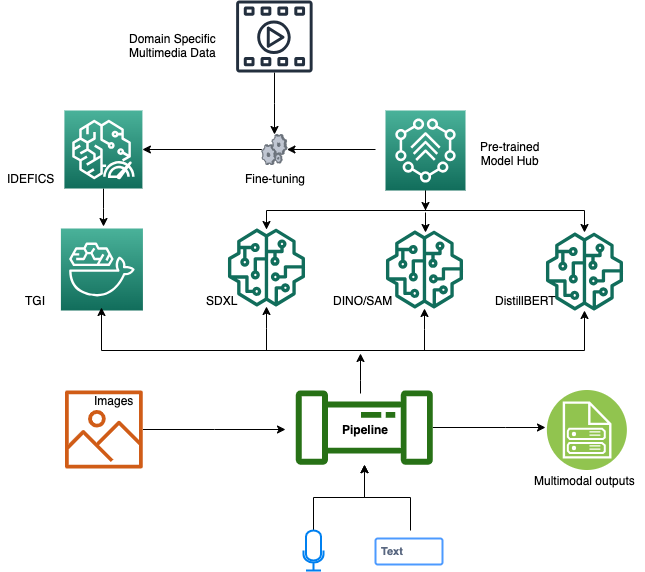
The proposed VLP resolution integrates a set of state-of-the-art generative AI modules to yield correct multimodal outputs. Central to the structure are the fine-tuned VLM and LLM, each instrumental in decoding visible and textual knowledge streams. The TGI framework underpins the mannequin inference layer, offering RESTful APIs for sturdy integration and easy accessibility. Supplementing our auditory knowledge processing, the Whisper ASR can also be furnished with a RESTful API, enabling streamlined voice-to-text conversions. Addressing complicated challenges like image-to-text segmentation, we use the containerized Grounded Segment Anything module, synergizing with the Grounded DINO and Segment Anything Model (SAM) mechanism for text-driven object detection and segmentation. The system is additional refined with DistilBERT, optimizing our dialogue-guided multi-class classification course of. Orchestrating these parts is the LangChain processing pipeline, a classy mechanism proficient in dissecting textual content or voice inputs, discerning person intentions, and methodically delegating sub-tasks to the related providers. The synthesis of those operations produces aggregated outputs, delivering pinpoint and context-aware multimodal solutions.
The next diagram illustrates the structure of our dialogue-guided VLP resolution.
Textual content Era Inference
Textual content Era Inference (TGI) is an open-source toolkit developed by Hugging Face for deploying LLMs in addition to VLMs for inference. It permits high-performance textual content era utilizing tensor parallelism, mannequin parallelism, and dynamic batching supporting some main open-source LLMs equivalent to Falcon and Llama V2, in addition to VLMs like IDEFICS. Using the newest Hugging Face LLM modules on Amazon SageMaker, AWS prospects can now faucet into the ability of SageMaker deep studying containers (DLCs). This enables for the seamless deployment of LLMs from the Hugging Face hubs through pre-built SageMaker DLCs supporting TGI. This inference setup not solely provides distinctive efficiency but in addition eliminates the necessity for managing the heavy lifting GPU infrastructure. Moreover, you profit from superior options like auto scaling of inference endpoints, enhanced safety, and built-in mannequin monitoring.
TGI provides textual content era speeds as much as 100 occasions quicker than conventional inference strategies and scales effectively to deal with elevated requests. Its design ensures compatibility with numerous LLMs and, being open-source, democratizes superior options for the tech group. TGI’s versatility extends throughout domains, enhancing chatbots, enhancing machine translations, summarizing texts, and producing numerous content material, from poetry to code. Due to this fact, TGI emerges as a complete resolution for textual content era challenges. TGI is carried out in Python and makes use of the PyTorch framework. It’s open-source and obtainable on GitHub. It additionally helps PEFT with QLoRA for quicker efficiency and logits warping to regulate generated textual content attributes, equivalent to figuring out its size and variety, with out modifying the underlying mannequin.
You’ll be able to construct a personalized TGI Docker container immediately from the next Dockerfile after which push the container picture to Amazon Elastic Container Registry (ECR) for inference deployment. See the next code:
%%sh
# Outline docker picture identify and container's Amazon Reource Identify on ECR
container_name="tgi1.03"
area=`aws configure get area`
account=`aws sts get-caller-identity --query "Account" --output textual content`
full_name="${account}.dkr.ecr.${area}.amazonaws.com/${container_name}:newest"
# Get the login command from ECR and execute it immediately
aws ecr get-login-password --region ${area}|docker login --username AWS
--password-stdin ${account}.dkr.ecr.${area}.amazonaws.com
# Construct the TGI docker picture domestically
docker construct . -f Dockerfile -t ${container_name}
docker tag ${container_name} ${full_name}
docker push ${full_name}
LLM inference with TGI
The VLP resolution on this publish employs the LLM in tandem with LangChain, harnessing the chain-of-thought (CoT) method for extra correct intent classification. CoT processes queries to discern intent and trigger-associated sub-tasks to satisfy the question’s objectives. Llama-2-7b-chat-hf (license agreement) is the streamlined model of the Llama-2 line, designed for dialogue contexts. The inference of Llama-2-7b-chat-hf is powered by the TGI container picture, making it obtainable as an API-enabled service.
For Llama-2-7b-chat-hf inference, a g5.2xlarge (24G VRAM) is beneficial to realize peak efficiency. For purposes necessitating a extra sturdy LLM, the Llama-v2-13b fashions match properly with a g5.12xlarge (96G VRAM) occasion. For the Llama-2-70b fashions, contemplate both the GPU [2xlarge] – 2x Nvidia A100 using bitsandbytes quantization or the g5.48xlarge. Notably, using bitsandbytes quantization can scale back the required inference GPU VRAM by 50%.
You should use SageMaker DLCs with the TGI container picture detailed earlier to deploy Llama-2-7b-chat-hf for inference (see the next code). Alternatively, you may arise a fast native inference for a proof of idea on a g5.2xlarge occasion utilizing a Docker container.
import json
from time import gmtime, strftime
from sagemaker.huggingface import get_huggingface_llm_image_uri
from sagemaker.huggingface import HuggingFaceModel
from sagemaker import get_execution_role
# Prerequisite:create an distinctive mannequin identify
model_name="Llama-7b-chat-hf" + strftime("%Y-%m-%d-%H-%M-%S", gmtime())
# retrieve the llm picture uri of SageMaker pre-built DLC TGI v1.03
tgi_image_ecr_uri = get_huggingface_llm_image_uri(
"huggingface",
model="1.0.3"
)
# Outline Mannequin and Endpoint configuration parameter
hf_config = {
'HF_MODEL_ID': "meta-research/Llama-2-7b-chat-hf", # Matching model_id on Hugging Face Hub
'SM_NUM_GPUS': json.dumps(number_of_gpu),
'MAX_TOTAL_TOKENS': json.dumps(1024),
'HF_MODEL_QUANTIZE': "bitsandbytes", # Use quantization for much less vram requirement, commet it if no wanted.
}
# create HuggingFaceModel with the SageMaker pre-built DLC TGI picture uri
sm_llm_model = HuggingFaceModel(
function=get_execution_role(),
image_uri=tgi_image_ecr_uri,
env=hf_config
)
# Deploy the mannequin
llm = sm_llm_model.deploy(
initial_instance_count=1,
instance_type="ml.g5.2xlarge",
container_startup_health_check_timeout=300, # in sec. Enable 5 minutes to have the ability to load the mannequin
)
# outline inference payload
immediate="""<|prompter|>Learn how to choose a proper LLM in your generative AI undertaking?<|endoftext|><|assistant|>"""
# hyperparameters for llm
payload = {
"inputs": immediate,
"parameters": {
"best_of": 1,
"decoder_input_details": true,
"particulars": true,
"do_sample": true,
"max_new_tokens": 20,
"repetition_penalty": 1.03,
"return_full_text": false,
"seed": null,
"cease": [
"photographer"
],
"temperature": 0.5,
"top_k": 10,
"top_p": 0.95,
"truncate": null,
"typical_p": 0.95,
"watermark": true
},
"stream": false
}
# ship request to endpoint
response = llm.predict(payload)
Wonderful-tune and customise your LLM
SageMaker JumpStart provides quite a few pocket book samples that show the usage of Parameter Environment friendly Wonderful Tuning (PEFT), together with QLoRA for coaching and fine-tuning LLMs. QLoRA maintains the pre-trained mannequin weights in a static state and introduces trainable rank decomposition matrices into every layer of the Transformer construction. This technique considerably decreases the variety of trainable parameters wanted for downstream duties.
Alternatively, you may discover Direct Preference Optimization (DPO), which obviates the need for establishing a reward mannequin, drawing samples throughout fine-tuning from the LLM, or intensive hyperparameter changes. Latest analysis has proven that DPO’s fine-tuning surpasses RLHF in managing sentiment era and enhances the standard of summaries and single-conversation responses, all whereas being significantly simpler to arrange and educate. There are three most important steps to the DPO coaching course of (consult with the GitHub repo for particulars):
- Carry out supervised fine-tuning of a pre-trained base LLM to create a fine-tuned LLM.
- Run the DPO coach utilizing the fine-tuned mannequin to create a reinforcement studying mannequin.
- Merge the adaptors from DPO into the bottom LLM mannequin for textual content era inference.
You’ll be able to deploy the merged mannequin for inference utilizing the TGI container picture.
Visible language mannequin
Visible Language Fashions (VLM) which mix each the imaginative and prescient and language modalities have been displaying their enhancing effectiveness in generalization, main to numerous sensible use instances with zero-shot prompts or few-shot prompts with directions. A VLM sometimes consists of three key components: a picture encoder, a textual content encoder, and a method to fuse info from the 2 encoders. These key components are tightly coupled collectively as a result of the loss capabilities are designed round each the mannequin structure and the educational technique. Many state-of-the-art VLMs use CLIP/ViT (equivalent to OpenCLIP) and LLMs (equivalent to Llama-v1) and are skilled on a number of publicly obtainable datasets equivalent to Wikipedia, LAION, and Public Multimodal Dataset.
This demo used a pre-trained IDEFICS-9b-instruct mannequin developed by HuggingFaceM4, a fine-tuned model of IDEFICS-9b, following the coaching process specified by Flamingo by combining the 2 pre-trained fashions (laion/CLIP-ViT-H-14-laion2B-s32B-b79K and huggyllama/llama-7b) with modified Transformer blocks. The IDEFICS-9b was skilled on OBELIC, Wikipedia, LAION, and PMD multimodal datasets with a complete 150 billion tokens and 1.582 billion photographs with 224×224 decision every. The IDEFICS-9b was primarily based on Llama-7b with a 1.31 million efficient batch dimension. The IDEFICS-9b-instruct was then fine-tuned with 6.8 million multimodality instruction datasets created from augmentation utilizing generative AI by unfreezing all of the parameters (imaginative and prescient encoder, language mannequin, cross-attentions). The fine-tuning datasets embody the pre-training knowledge with the next sampling ratios: 5.1% of image-text pairs and 30.7% of OBELICS multimodal internet paperwork.
The coaching software program is constructed on high of Hugging Face Transformers and Speed up, and DeepSpeed ZeRO-3 for coaching, plus WebDataset and Image2DataSets for knowledge loading. The pre-training of IDEFICS-9b took 350 hours to finish on 128 Nvidia A100 GPUs, whereas fine-tuning of IDEFICS-9b-instruct took 70 hours on 128 Nvidia A100 GPUs, each on AWS p4.24xlarge situations.
With SageMaker, you may seamlessly deploy IDEFICS-9b-instruct on a g5.2xlarge occasion for inference duties. The next code snippet illustrates tips on how to launch a tailor-made deep studying native container built-in with the personalized TGI Docker picture:
%%sh
llm_model="HuggingFaceM4/idefics-9b-instruct"
docker_rt_name="idefics-9b-instruct"
docker_image_name="tgi1.03"
docker run --gpus="1,2,3,4" --shm-size 20g -p 8080:80 --restart unless-stopped --name ${docker_rt_name} ${docker_image_name} --model-id ${llm_model}
# Check the LLM API utilizing curl
curl -X 'POST' 'http://<hostname_or_ip>:8080/'
-H 'settle for: software/json'
-H 'Content material-Sort: software/json'
-d '{
"inputs": "Consumer:Which machine produced this picture? Please clarify the primary scientific goal of such picture?Are you able to write a radiology report primarily based on this picture?<end_of_utterance>", "parameters": {
"best_of": 1, "decoder_input_details": true,
"particulars": true, "do_sample": true, "max_new_tokens": 20,
"repetition_penalty": 1.03, "return_full_text": false,
"seed": null, "cease": [ "photographer" ],
"temperature": 0.5, "top_k": 10, "top_p": 0.95,
"truncate": null, "typical_p": 0.95, "watermark": true },
"stream": false
}'
You’ll be able to fine-tune IDEFICS or different VLMs together with Open Flamingo with your personal domain-specific knowledge with directions. Discuss with the next README for multimodality dataset preparation and the fine-tuning script for additional particulars.
Intent classification with chain-of-thought
An image is value a thousand phrases, subsequently VLM requires steerage to generate an correct caption from a given picture and query. We are able to use few-shot prompting to allow in-context studying, the place we offer demonstrations within the immediate to steer the mannequin to raised efficiency. The demonstrations function conditioning for subsequent examples the place we wish the mannequin to generate a response.
Commonplace few-shot prompting works properly for a lot of duties however continues to be not an ideal method, particularly when coping with extra complicated reasoning duties. The few-shot prompting template just isn’t sufficient to get dependable responses. It would assist if we break the issue down into steps and show that to the mannequin. Extra lately, chain-of-thought (CoT) prompting has been popularized to handle extra complicated arithmetic, widespread sense, and symbolic reasoning duties
CoT get rid of handbook efforts through the use of LLMs with a “Let’s assume step-by-step” immediate to generate reasoning chains for demonstrations one after the other. Nevertheless, this automated course of can nonetheless find yourself with errors in generated chains. To mitigate the results of the errors, the range of demonstrations matter. This publish proposes Auto-CoT, which samples questions with range and generates reasoning chains to assemble the demonstrations. CoT consists of two most important phases:
- Query clustering – Partition questions of a given dataset into a couple of clusters
- Demonstration sampling – Choose a consultant query from every cluster and generate its reasoning chain utilizing zero-shot CoT with easy heuristics
See the next code snippet:
from langchain.llms import HuggingFaceTextGenInference
from langchain import PromptTemplate, LLMChain
inference_server_url_local = <Your_local_url_for_llm_on_tgi:port>
llm_local = HuggingFaceTextGenInference(
inference_server_url=inference_server_url_local,
max_new_tokens=512,
top_k=10,
top_p=0.95,
typical_p=0.95,
temperature=0.1,
repetition_penalty=1.05,
template = """Use the next items of context to reply the query on the finish. If you do not know the reply, simply say that you do not know, do not attempt to make up a solution.
Use ten 5 most and maintain the reply as refined as potential. Record all actionable sub-tasks step-by-step intimately. Be cautious to keep away from phrasing that may replicate earlier
inquiries. This can assist in acquiring an correct and detailed reply. Keep away from repetition for readability.
Query: {query}
Reply: Perceive the intent of the query then break down the {query} in to sub-tasks. """
immediate = PromptTemplate(
template=template,
input_variables= ["question"]
)
llm_chain_local = LLMChain(immediate=immediate, llm=llm_local)
llm_chain_local("Are you able to describe the character of this picture? Do you assume it is actual??")
Computerized Speech Recognition
The VLP resolution incorporates Whisper, an Computerized Speech Recognition (ASR) mannequin by OpenAI, to deal with audio queries. Whisper will be effortlessly deployed through SageMaker JumpStart utilizing its template. SageMaker JumpStart, identified for its easy setup, excessive efficiency, scalability, and dependability, is right for builders aiming to craft distinctive voice-driven purposes. The next GitHub repo demonstrates tips on how to harness SageMaker real-time inference endpoints to fine-tune and host Whisper for immediate audio-to-text transcription, showcasing the synergy between SageMaker internet hosting and generative fashions.
Alternatively, you may immediately obtain the Dockerfile.gpu from GitHub developed by ahmetoner, which features a pre-configured RESTful API. You’ll be able to then assemble a Docker picture and run the container on a GPU-powered Amazon Elastic Compute Cloud (EC2) occasion for a fast proof of idea. See the next code:
%%sh
docker_iamge_name="whisper-asr-webservice-gpu"
docker construct -f Dockerfile.gpu -t ${docker_iamge_nam}
docker run -d --gpus all -p 8083:9000 --restart unless-stopped -e ASR_MODEL=base ${docker_iamge_nam}
curl -X 'POST' 'http://<asr_api_hostname>:<port>/asr?activity=transcribe&encode=true&output=txt'
-H 'settle for: software/json'
-H 'Content material-Sort: multipart/form-data'
-F 'audio_file=@dgvlp_3_5.mp3;sort=audio/mpeg'
Within the supplied instance, port 8083 is chosen to host the Whisper API, with inbound community safety guidelines activated. To check, direct an online browser to http://<IP_or_hostname>:8083/docs and provoke a POST request check to the ASR endpoint. Instead, run the given command or make use of the whisper-live module to confirm API connectivity.
!pip set up whisper-live
from whisper_live.consumer import TranscriptionClient
consumer = TranscriptionClient("<whisper_hostname_or_IP>", 8083, is_multilingual=True, lang="zh", translate=True)
consumer(audio_file_path) # Use sudio file
consumer() # Use microphone for transcribe
Multi-class textual content classification and key phrase extraction
Multi-class classification performs a pivotal function in textual content prompt-driven object detection and segmentation. The distilbert-base-uncased-finetuned-sst-2-english mannequin is a refined checkpoint of DistilBERT-base-uncased, optimized on the Stanford Sentiment Treebank (SST2) dataset by Hugging Face. This mannequin achieves a 91.3% accuracy on the event set, whereas its counterpart bert-base-uncased boasts an accuracy of 92.7%. The Hugging Face Hub gives entry to over 1,000 pre-trained textual content classification fashions. For these in search of enhanced precision, SageMaker JumpStart gives templates to fine-tune DistilBERT utilizing customized annotated datasets for extra tailor-made classification duties.
import torch
from transformers import pipeline
def mclass(text_prompt, top_k=3, matters = ['Mask creation', 'Object detection',
'Inpainting', 'Segmentation', 'Upscaling', 'Creating an image from another one', 'Generating:q an image from text'],
mannequin="distilbert-base-uncased-finetuned-sst-2-english"):
machine = torch.machine('cuda' if torch.cuda.is_available() else 'cpu')
# Outline a german speculation template and the potential candidates for entailment/contradiction
template_de="The subject is {}"
# Pipeline abstraction from hugging face
pipe = pipeline(activity='zero-shot-classification', mannequin=mannequin, tokenizer=mannequin, machine=machine)
# Run pipeline with a check case
prediction = pipe(text_prompt, matters, hypothesis_template=template_de)
# High 3 matters as predicted in zero-shot regime
return zip(prediction['labels'][0:top_k], prediction['scores'][0:top_k])
top_3_intend = mclass(text_prompt=user_prompt_str, matters=['Others', 'Create image mask', 'Image segmentation'], top_k=3)
The key phrase extraction course of employs the KeyBERT module, a streamlined and user-friendly technique that harnesses BERT embeddings to generate key phrases and key phrases carefully aligned with a doc—on this case, the objects specified within the question:
# Key phrase extraction
from keybert import KeyBERT
kw_model = KeyBERT()
words_list = kw_model.extract_keywords(docs=<user_prompt_str>, keyphrase_ngram_range=(1,3))
Textual content prompt-driven object detection and classification
The VLP resolution employs dialogue-guided object detection and segmentation by analyzing the semantic which means of the textual content and figuring out the motion and objects from textual content immediate. Grounded-SAM is an open-source package deal created by IDEA-Analysis to detect and phase something from a given picture with textual content inputs. It combines the strengths of Grounding DINO and Phase Something to be able to construct a really highly effective pipeline for fixing complicated issues.
The next determine illustrates how Grounded-SAM can detect objects and conduct occasion segmentation by comprehending textual enter.

SAM stands out as a strong segmentation mannequin, although it requires prompts, equivalent to bounding containers or factors, to provide high-quality object masks. Grounding DINO excels as a zero-shot detector, adeptly creating high-quality containers and labels utilizing free-form textual content prompts. When these two fashions are mixed, they provide the exceptional functionality to detect and phase any object purely by textual content inputs. The Python utility script dino_sam_inpainting.py was developed to combine Grounded-SAM strategies:
!pip set up git+https://github.com/facebookresearch/segment-anything.git
import dino_sam_inpainting as D
def dino_sam(image_path, text_prompt, text_threshold=0.4, box_threshold=0.5, output_dir="/temp/gradio/outputs"):
config_file="GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py" # change the trail of the mannequin config file
grounded_checkpoint="./fashions/groundingdino_swint_ogc.pth" # change the trail of the mannequin
sam_checkpoint="./fashions/sam_vit_h_4b8939.pth"
sam_hq_checkpoint="" #if to make use of top quality, like sam_hq_vit_h.pth
use_sam_hq = ''
output_dir="/tmp/gradio/outputs"
machine="cuda"
# make dir
os.makedirs(output_dir, exist_ok=True)
# load picture
image_pil, picture = D.load_image(image_path)
# load mannequin
mannequin = D.load_model(config_file, grounded_checkpoint, machine=machine)
output_file_name = f'{format(os.path.basename(image_path))}'
# visualize uncooked picture
image_pil.save(os.path.be a part of(output_dir, output_file_name))
# run grounding dino mannequin
boxes_filt, pred_phrases = D.get_grounding_output(
mannequin, picture, text_prompt, box_threshold, text_threshold, machine=machine
)
# initialize SAM
if use_sam_hq:
predictor = D.SamPredictor(D.build_sam_hq(checkpoint=sam_hq_checkpoint).to(machine))
else:
predictor = D.SamPredictor(D.build_sam(checkpoint=sam_checkpoint).to(machine))
picture = cv2.imread(image_path)
picture = cv2.cvtColor(picture, cv2.COLOR_BGR2RGB)
predictor.set_image(picture)
dimension = image_pil.dimension
H, W = dimension[1], dimension[0]
for i in vary(boxes_filt.dimension(0)):
boxes_filt[i] = boxes_filt[i] * torch.Tensor([W, H, W, H])
boxes_filt[i][:2] -= boxes_filt[i][2:] / 2
boxes_filt[i][2:] += boxes_filt[i][:2]
boxes_filt = boxes_filt.cpu()
transformed_boxes = predictor.remodel.apply_boxes_torch(boxes_filt, picture.form[:2]).to(machine)
masks, _, _ = predictor.predict_torch(
point_coords = None,
point_labels = None,
containers = transformed_boxes.to(machine),
multimask_output = False,
)
# draw output picture
plt.determine(figsize=(10, 10))
plt.imshow(picture)
for masks in masks:
D.show_mask(masks.cpu().numpy(), plt.gca(), random_color=True)
for field, label in zip(boxes_filt, pred_phrases):
D.show_box(field.numpy(), plt.gca(), label)
output_file_name = f'{format(os.path.basename(image_path))}'
plt.axis('off')
plt.savefig(
os.path.be a part of(output_dir, f'grounded_sam_{output_file_name}'),
bbox_inches="tight", dpi=300, pad_inches=0.0
)
D.save_mask_data(output_dir, masks, boxes_filt, pred_phrases)
return f'grounded_sam_{output_file_name}'
filename = dino_sam(image_path=<image_path_str>, text_prompt=<object_name_str>, output_dir=<output_image_filename_path_str>, box_threshold=0.5, text_threshold=0.55)
You’ll be able to select HQ-SAM to improve SAM for high-quality zero-shot segmentation. Discuss with the next paper and code pattern on GitHub for extra particulars.
VLP processing pipeline
The principle goal of the VLP processing pipeline is to mix the strengths of various fashions, creating a classy workflow specialised for VLP. It’s vital to spotlight that this setup prioritizes the combination of top-tier fashions throughout visible, textual content, and voice domains. Every phase of the pipeline is modular, facilitating both standalone use or mixed operation. Moreover, the design ensures flexibility, enabling the alternative of parts with extra superior fashions but to come back, whereas supporting multithreading and error dealing with with respected implementation.
The next determine illustrates a VLP pipeline knowledge stream and repair parts.

In our exploration of the VLP pipeline, we design one which may course of each textual content prompts from open textual content format and informal voice inputs from microphones. The audio processing is facilitated by Whisper, able to multilingual speech recognition and translation. The transcribed textual content is then channeled to an intent classification module, which discerns the semantic essence of the prompts. This works in tandem with a LangChain pushed CoT engine, dissecting the primary intent into finer sub-tasks for extra detailed info retrieval and era. If picture processing is inferred from the enter, the pipeline commences a key phrase extraction course of, choosing the highest N key phrases by cross-referencing objects detected within the unique picture. Subsequently, these key phrases are routed to the Grounded-SAM engine, which generates bounding containers. These bounding containers are then provided to the SAM mannequin, which crafts exact segmentation masks, pinpointing every distinctive object occasion within the supply picture. The ultimate step includes overlaying the masks and bounding containers onto the unique picture, yielding a processed picture that’s offered as a multimodal output.
When the enter question seeks to interpret a picture, the pipeline engages the LLM to prepare the sub-tasks and refine the question with focused objectives. Subsequently, the result is directed to the VLM API, accompanied by few-shot directions, the URL of the enter picture, and the rephrased textual content immediate. In response, the VLM gives the textual output. The VLP pipeline will be carried out utilizing a Python-based workflow pipeline or various orchestration utilities. Such pipelines function by chaining a sequential set of subtle fashions, culminating in a structured modeling process sequentially. The pipeline integrates with the Gradio engine for demonstration functions:
def vlp_text_pipeline(str input_text, str original_image_path, chat_history):
intent_class = intent_classification(input_text)
key_words = keyword_extraction(input_text)
image_caption = vlm(input_text, original_image_path)
chat_history.append(image_caption)
if intent_class in {supported intents}:
object_bounding_box = object_detection(intent_class, key_words, original_image_path)
mask_image_path = image_segmentation(object_bounding_box, key_words, original_image_path)
chat_history.append(mask_image_path)
return chat_history
def vlp_voice_pipeline(str audio_file_path, str original_image_path, chat_history):
asr_text = whisper_transcrib(audio_file_path)
chat_history.append(asr_text, original_image_path, chat_history)
return chat_history
chat_history = map(vlp_pipelines, input_text, original_image_path, chat_history)
if (audio_file_path is None)
else map(vlp_voice_pipelines, original_image_path, chat_history)
Limitations
Utilizing pre-trained VLM fashions for VLP has demonstrated promising potential for picture understanding. Together with language-based object detection and segmentation, VLP can produce helpful outputs with cheap high quality. Nevertheless, VLP nonetheless suffers from inconsistent outcomes, lacking particulars from footage, and it’d even hallucinate. Furthermore, fashions may produce factually incorrect texts and shouldn’t be relied on to provide factually correct info. Since not one of the referenced pre-trained VLM, SAM, or LLM fashions has been skilled or fine-tuned for domain-specific production-grade purposes, this resolution just isn’t designed for mission-critical purposes that may affect livelihood or trigger materials losses
With immediate engineering, the IDEFICS mannequin generally can acknowledge further particulars after a textual content trace; nevertheless, the result’s removed from constant and dependable. It may be persistent in sustaining inaccuracies and could also be unable or unwilling to make corrections even when customers spotlight these throughout a dialog. Enhancing the spine mannequin by integrating Swin-ViT and fusing it with CNN-based fashions like DualToken-ViT, together with coaching utilizing extra superior fashions like Llama-v2, might doubtlessly deal with a few of these limitations.
Subsequent steps
The VLP resolution is poised for notable progress. As we glance forward, there are a number of key alternatives to advance VLP options:
- Prioritize integrating dynamic immediate directions and few-shot studying hints. These enhancements will allow extra correct AI suggestions.
- Intent classification groups ought to focus efforts on refining the classifier to select up on nuanced, domain-specific intents from open prompts. With the ability to perceive exact person intents will probably be important.
- Implement an agent tree of ideas mannequin into the reasoning pipeline. This construction will enable for specific reasoning steps to finish sub-tasks.
- Pilot fine-tuning initiatives on main fashions. Tailoring VLM, LLM, and SAM fashions to key industries and use instances by fine-tuning will probably be pivotal.
Acknowledgment
The authors lengthen their gratitude to Vivek Madan and Ashish Rawat for his or her insightful suggestions and overview of this publish.
Concerning the authors
 Alfred Shen is a Senior AI/ML Specialist at AWS. He has been working in Silicon Valley, holding technical and managerial positions in numerous sectors together with healthcare, finance, and high-tech. He’s a devoted utilized AI/ML researcher, concentrating on CV, NLP, and multimodality. His work has been showcased in publications equivalent to EMNLP, ICLR, and Public Well being.
Alfred Shen is a Senior AI/ML Specialist at AWS. He has been working in Silicon Valley, holding technical and managerial positions in numerous sectors together with healthcare, finance, and high-tech. He’s a devoted utilized AI/ML researcher, concentrating on CV, NLP, and multimodality. His work has been showcased in publications equivalent to EMNLP, ICLR, and Public Well being.
 Dr. Li Zhang is a Principal Product Supervisor-Technical for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms, a service that helps knowledge scientists and machine studying practitioners get began with coaching and deploying their fashions, and makes use of reinforcement studying with Amazon SageMaker. His previous work as a principal analysis workers member and grasp inventor at IBM Analysis has received the check of time paper award at IEEE INFOCOM.
Dr. Li Zhang is a Principal Product Supervisor-Technical for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms, a service that helps knowledge scientists and machine studying practitioners get began with coaching and deploying their fashions, and makes use of reinforcement studying with Amazon SageMaker. His previous work as a principal analysis workers member and grasp inventor at IBM Analysis has received the check of time paper award at IEEE INFOCOM.
 Dr. Changsha Ma is an AI/ML Specialist at AWS. She is a technologist with a PhD in Pc Science, a grasp’s diploma in Training Psychology, and years of expertise in knowledge science and impartial consulting in AI/ML. She is obsessed with researching methodological approaches for machine and human intelligence. Exterior of labor, she loves climbing, cooking, looking meals, mentoring faculty college students for entrepreneurship, and spending time with pals and households.
Dr. Changsha Ma is an AI/ML Specialist at AWS. She is a technologist with a PhD in Pc Science, a grasp’s diploma in Training Psychology, and years of expertise in knowledge science and impartial consulting in AI/ML. She is obsessed with researching methodological approaches for machine and human intelligence. Exterior of labor, she loves climbing, cooking, looking meals, mentoring faculty college students for entrepreneurship, and spending time with pals and households.
 Xin Huang is a Senior Utilized Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on growing scalable machine studying algorithms. His analysis pursuits are within the space of pure language processing, explainable deep studying on tabular knowledge, and sturdy evaluation of non-parametric space-time clustering. He has revealed many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Collection A.
Xin Huang is a Senior Utilized Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on growing scalable machine studying algorithms. His analysis pursuits are within the space of pure language processing, explainable deep studying on tabular knowledge, and sturdy evaluation of non-parametric space-time clustering. He has revealed many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Collection A.





