Stanford and UT Austin Researchers Suggest Contrastive Choice Studying (CPL): A Easy Reinforcement Studying RL-Free Technique for RLHF that Works with Arbitrary MDPs and off-Coverage Knowledge
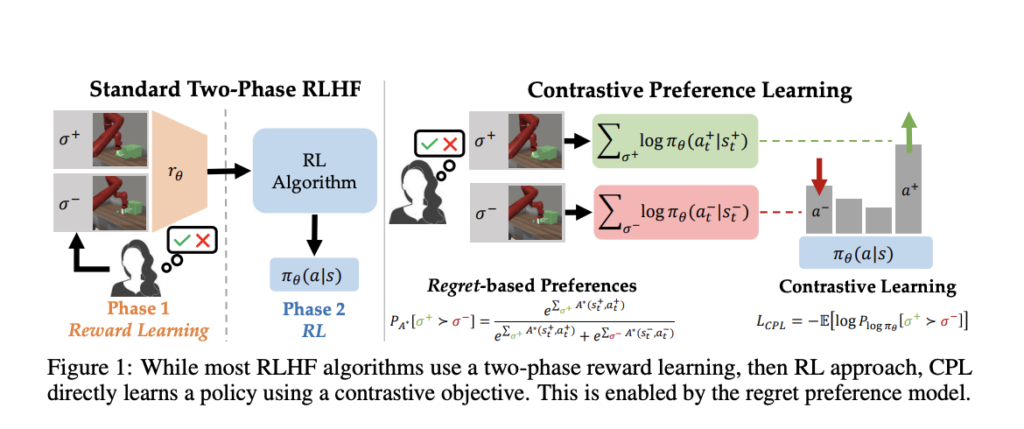
The problem of matching human preferences to large pretrained fashions has gained prominence within the research as these fashions have grown in efficiency. This alignment turns into notably difficult when there are unavoidably poor behaviours in larger datasets. For this difficulty, reinforcement studying from human enter, or RLHF has grow to be in style. RLHF approaches use human preferences to differentiate between acceptable and dangerous behaviours to enhance a identified coverage. This method has demonstrated encouraging outcomes when used to regulate robotic guidelines, improve picture era fashions, and fine-tune giant language fashions (LLMs) utilizing less-than-ideal knowledge. There are two levels to this process for almost all of RLHF algorithms.
First, person desire knowledge is gathered to coach a reward mannequin. An off-the-shelf reinforcement studying (RL) algorithm optimizes that reward mannequin. Regretfully, there must be a correction within the basis of this two-phase paradigm. Human preferences should be allotted by the discounted whole of rewards or partial return of every behaviour section for algorithms to develop reward fashions from desire knowledge. Current analysis, nevertheless, challenges this concept, suggesting that human preferences must be based mostly on the remorse of every motion below the perfect coverage of the professional’s reward operate. Human analysis might be intuitively centered on optimality somewhat than whether or not conditions and behaviours present better rewards.
Due to this fact, the optimum benefit operate, or the negated remorse, could be the very best quantity to study from suggestions somewhat than the reward. Two-phase RLHF algorithms use RL of their second part to optimize the reward operate identified within the first part. In real-world purposes, temporal credit score task presents a wide range of optimization difficulties for RL algorithms, together with the instability of approximation dynamic programming and the excessive variance of coverage gradients. Because of this, earlier works limit their attain to keep away from these issues. For instance, contextual bandit formulation is assumed by RLHF approaches for LLMs, the place the coverage is given a single reward worth in response to a person query.
The only-step bandit assumption is damaged as a result of person interactions with LLMs are multi-step and sequential, even whereas this lessens the requirement for long-horizon credit score task and, consequently, the excessive variation of coverage gradients. One other instance is the appliance of RLHF to low-dimensional state-based robotics points, which works nicely for approximation dynamic programming. Nonetheless, it has but to be scaled to higher-dimensional steady management domains with image inputs, that are extra life like. On the whole, RLHF approaches require decreasing the optimisation constraints of RL by making restricted assumptions in regards to the sequential nature of issues or dimensionality. They often mistakenly imagine that the reward operate alone determines human preferences.
In distinction to the broadly used partial return mannequin, which considers the full rewards, researchers from Stanford College, UMass Amherst and UT Austin present a novel household of RLHF algorithms on this research that employs a regret-based mannequin of preferences. In distinction to the partial return mannequin, the regret-based method offers exact data on the most effective plan of action. Happily, this removes the need for RL, enabling us to deal with RLHF points with high-dimensional state and motion areas within the generic MDP framework. Their basic discovering is to create a bijection between benefit features and insurance policies by combining the regret-based desire framework with the Most Entropy (MaxEnt) precept.
They’ll set up a purely supervised studying goal whose optimum is the most effective coverage below the professional’s reward by buying and selling optimization over benefits for optimization over insurance policies. As a result of their methodology resembles well known contrastive studying aims, they name it Contrastive Choice Studying—three principal advantages of CPL over earlier efforts. First, as a result of CPL matches the optimum benefit completely utilizing supervised objectives—somewhat than utilizing dynamic programming or coverage gradients—it could scale in addition to supervised studying. Second, CPL is totally off-policy, making utilizing any offline, less-than-ideal knowledge supply attainable. Lastly, CPL allows desire searches over sequential knowledge for studying on arbitrary Markov Determination Processes (MDPs).
So far as they know, earlier strategies for RLHF have but to fulfill all three of those necessities concurrently. They illustrate CPL’s efficiency on sequential decision-making points utilizing sub-optimal and high-dimensional off-policy inputs to show that it adheres to the abovementioned three tenets. Curiously, they reveal that CPL could study temporally prolonged manipulation guidelines within the MetaWorld Benchmark by effectively utilising the identical RLHF fine-tuning course of as dialogue fashions. To be extra exact, they use supervised studying from high-dimensional image observations to pre-train insurance policies, which they then fine-tune utilizing preferences. CPL can match the efficiency of earlier RL-based strategies with out the necessity for dynamic programming or coverage gradients. It’s also 4 occasions extra parameter environment friendly and 1.6 occasions faster concurrently. On 5 duties out of six, CPL outperforms RL baselines when using denser desire knowledge. Researchers can keep away from the need for reinforcement studying (RL) by using the idea of most entropy to create Contrastive Choice Studying (CPL), an algorithm for studying optimum insurance policies from preferences with out studying reward features.
Try the Paper. All Credit score For This Analysis Goes To the Researchers on This Mission. Additionally, don’t overlook to affix our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI initiatives, and extra.
If you like our work, you will love our newsletter..
We’re additionally on Telegram and WhatsApp.
Aneesh Tickoo is a consulting intern at MarktechPost. He’s at the moment pursuing his undergraduate diploma in Knowledge Science and Synthetic Intelligence from the Indian Institute of Know-how(IIT), Bhilai. He spends most of his time engaged on initiatives geared toward harnessing the ability of machine studying. His analysis curiosity is picture processing and is obsessed with constructing options round it. He loves to attach with individuals and collaborate on attention-grabbing initiatives.



