Mannequin Collapse: An Experiment – O’Reilly

Ever for the reason that present craze for AI-generated every little thing took maintain, I’ve questioned: what is going to occur when the world is so filled with AI-generated stuff (textual content, software program, footage, music) that our coaching units for AI are dominated by content material created by AI. We already see hints of that on GitHub: in February 2023, GitHub said that 46% of all of the code checked in was written by Copilot. That’s good for the enterprise, however what does that imply for future generations of Copilot? Sooner or later within the close to future, new fashions can be educated on code that they’ve written. The identical is true for each different generative AI software: DALL-E 4 can be educated on information that features photographs generated by DALL-E 3, Secure Diffusion, Midjourney, and others; GPT-5 can be educated on a set of texts that features textual content generated by GPT-4; and so forth. That is unavoidable. What does this imply for the standard of the output they generate? Will that high quality enhance or will it endure?
I’m not the one individual questioning about this. At the very least one analysis group has experimented with coaching a generative mannequin on content material generated by generative AI, and has discovered that the output, over successive generations, was extra tightly constrained, and fewer more likely to be unique or distinctive. Generative AI output grew to become extra like itself over time, with much less variation. They reported their ends in “The Curse of Recursion,” a paper that’s effectively value studying. (Andrew Ng’s newsletter has a superb abstract of this consequence.)

Be taught quicker. Dig deeper. See farther.
I don’t have the assets to recursively prepare massive fashions, however I considered a easy experiment that is likely to be analogous. What would occur should you took an inventory of numbers, computed their imply and commonplace deviation, used these to generate a brand new checklist, and did that repeatedly? This experiment solely requires easy statistics—no AI.
Though it doesn’t use AI, this experiment may nonetheless display how a mannequin may collapse when educated on information it produced. In lots of respects, a generative mannequin is a correlation engine. Given a immediate, it generates the phrase most certainly to come back subsequent, then the phrase largely to come back after that, and so forth. If the phrases “To be” come out, the following phrase in all fairness more likely to be “or”; the following phrase after that’s much more more likely to be “not”; and so forth. The mannequin’s predictions are, kind of, correlations: what phrase is most strongly correlated with what got here earlier than? If we prepare a brand new AI on its output, and repeat the method, what’s the consequence? Will we find yourself with extra variation, or much less?
To reply these questions, I wrote a Python program that generated an extended checklist of random numbers (1,000 parts) in keeping with the Gaussian distribution with imply 0 and commonplace deviation 1. I took the imply and commonplace deviation of that checklist, and use these to generate one other checklist of random numbers. I iterated 1,000 occasions, then recorded the ultimate imply and commonplace deviation. This consequence was suggestive—the usual deviation of the ultimate vector was nearly at all times a lot smaller than the preliminary worth of 1. However it assorted broadly, so I made a decision to carry out the experiment (1,000 iterations) 1,000 occasions, and common the ultimate commonplace deviation from every experiment. (1,000 experiments is overkill; 100 and even 10 will present related outcomes.)
After I did this, the usual deviation of the checklist gravitated (I received’t say “converged”) to roughly 0.45; though it nonetheless assorted, it was nearly at all times between 0.4 and 0.5. (I additionally computed the usual deviation of the usual deviations, although this wasn’t as attention-grabbing or suggestive.) This consequence was outstanding; my instinct informed me that the usual deviation wouldn’t collapse. I anticipated it to remain near 1, and the experiment would serve no objective aside from exercising my laptop computer’s fan. However with this preliminary lead to hand, I couldn’t assist going additional. I elevated the variety of iterations repeatedly. Because the variety of iterations elevated, the usual deviation of the ultimate checklist obtained smaller and smaller, dropping to .0004 at 10,000 iterations.
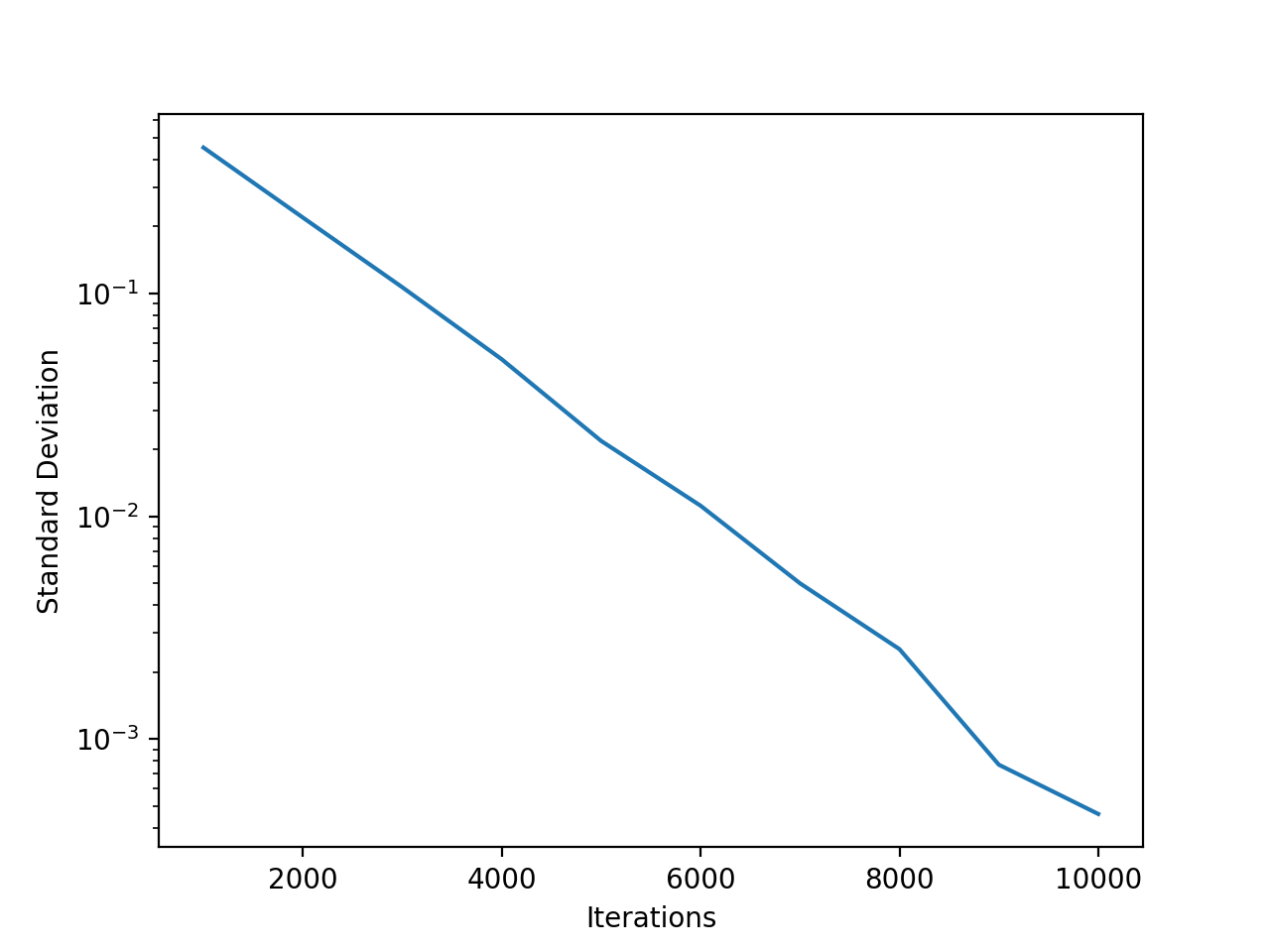
I feel I do know why. (It’s very seemingly that an actual statistician would have a look at this drawback and say “It’s an apparent consequence of the law of large numbers.”) In case you have a look at the usual deviations one iteration at a time, there’s lots a variance. We generate the primary checklist with a typical deviation of 1, however when computing the usual deviation of that information, we’re more likely to get a typical deviation of 1.1 or .9 or nearly the rest. Whenever you repeat the method many occasions, the usual deviations lower than one, though they aren’t extra seemingly, dominate. They shrink the “tail” of the distribution. Whenever you generate an inventory of numbers with a typical deviation of 0.9, you’re a lot much less more likely to get an inventory with a typical deviation of 1.1—and extra more likely to get a typical deviation of 0.8. As soon as the tail of the distribution begins to vanish, it’s most unlikely to develop again.
What does this imply, if something?
My experiment exhibits that should you feed the output of a random course of again into its enter, commonplace deviation collapses. That is precisely what the authors of “The Curse of Recursion” described when working immediately with generative AI: “the tails of the distribution disappeared,” nearly utterly. My experiment gives a simplified mind-set about collapse, and demonstrates that mannequin collapse is one thing we should always anticipate.
Mannequin collapse presents AI improvement with a major problem. On the floor, stopping it’s simple: simply exclude AI-generated information from coaching units. However that’s not doable, a minimum of now as a result of instruments for detecting AI-generated content material have proven inaccurate. Watermarking may assist, though watermarking brings its own set of problems, together with whether or not builders of generative AI will implement it. Tough as eliminating AI-generated content material is likely to be, amassing human-generated content material may change into an equally important drawback. If AI-generated content material displaces human-generated content material, high quality human-generated content material could possibly be laborious to seek out.
If that’s so, then the way forward for generative AI could also be bleak. Because the coaching information turns into ever extra dominated by AI-generated output, its means to shock and delight will diminish. It’ll change into predictable, uninteresting, boring, and doubtless no much less more likely to “hallucinate” than it’s now. To be unpredictable, attention-grabbing, and artistic, we nonetheless want ourselves.



