Clever doc processing with Amazon Textract, Amazon Bedrock, and LangChain
In in the present day’s data age, the huge volumes of information housed in numerous paperwork current each a problem and a possibility for companies. Conventional doc processing strategies typically fall quick in effectivity and accuracy, leaving room for innovation, cost-efficiency, and optimizations. Doc processing has witnessed important developments with the appearance of Clever Doc Processing (IDP). With IDP, companies can rework unstructured information from numerous doc varieties into structured, actionable insights, dramatically enhancing effectivity and decreasing guide efforts. Nonetheless, the potential doesn’t finish there. By integrating generative synthetic intelligence (AI) into the method, we are able to additional improve IDP capabilities. Generative AI not solely introduces enhanced capabilities in doc processing, it additionally introduces a dynamic adaptability to altering information patterns. This publish takes you thru the synergy of IDP and generative AI, unveiling how they symbolize the following frontier in doc processing.
We talk about IDP intimately in our sequence Clever doc processing with AWS AI companies (Part 1 and Part 2). On this publish, we talk about find out how to prolong a brand new or present IDP structure with giant language fashions (LLMs). Extra particularly, we talk about how we are able to combine Amazon Textract with LangChain as a doc loader and Amazon Bedrock to extract information from paperwork and use generative AI capabilities throughout the numerous IDP phases.
Amazon Textract is a machine studying (ML) service that mechanically extracts textual content, handwriting, and information from scanned paperwork. Amazon Bedrock is a totally managed service that provides a selection of high-performing basis fashions (FMs) by means of easy-to-use APIs.
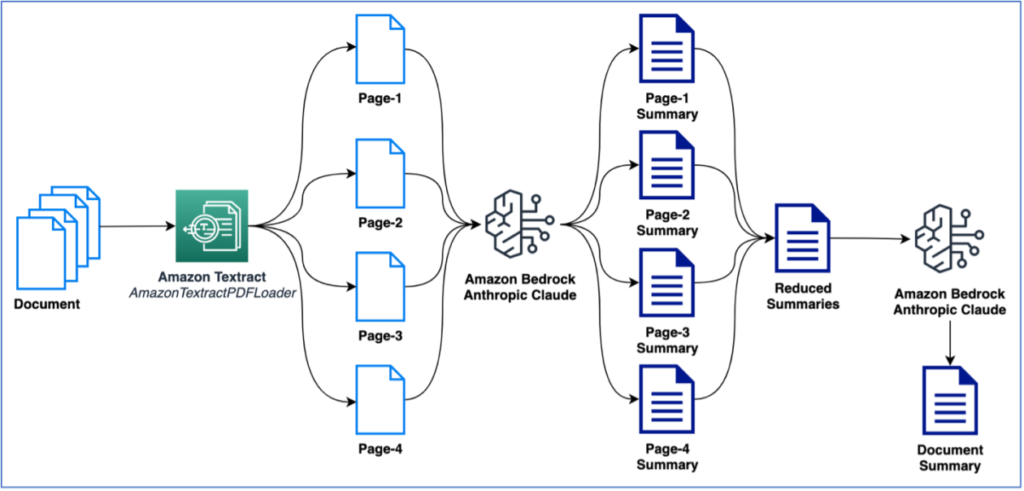
The next diagram is a high-level reference structure that explains how one can additional improve an IDP workflow with basis fashions. You should utilize LLMs in a single or all phases of IDP relying on the use case and desired end result.
Within the following sections, we dive deep into how Amazon Textract is built-in into generative AI workflows utilizing LangChain to course of paperwork for every of those particular duties. The code blocks supplied right here have been trimmed down for brevity. Confer with our GitHub repository for detailed Python notebooks and a step-by-step walkthrough.
Textual content extraction from paperwork is a vital side in terms of processing paperwork with LLMs. You should utilize Amazon Textract to extract unstructured uncooked textual content from paperwork and protect the unique semi-structured or structured objects like key-value pairs and tables current within the doc. Doc packages like healthcare and insurance coverage claims or mortgages include advanced kinds that comprise numerous data throughout structured, semi-structured, and unstructured codecs. Doc extraction is a crucial step right here as a result of LLMs profit from the wealthy content material to generate extra correct and related responses, which in any other case may influence the standard of the LLMs’ output.
LangChain is a robust open-source framework for integrating with LLMs. LLMs generally are versatile however could battle with domain-specific duties the place deeper context and nuanced responses are wanted. LangChain empowers builders in such eventualities to construct brokers that may break down advanced duties into smaller sub-tasks. The sub-tasks can then introduce context and reminiscence into LLMs by connecting and chaining LLM prompts.
LangChain gives document loaders that may load and rework information from paperwork. You should utilize them to construction paperwork into most popular codecs that may be processed by LLMs. The AmazonTextractPDFLoader is a service loader kind of doc loader that gives fast solution to automate doc processing by utilizing Amazon Textract together with LangChain. For extra particulars on AmazonTextractPDFLoader, seek advice from the LangChain documentation. To make use of the Amazon Textract doc loader, you begin by importing it from the LangChain library:
from langchain.document_loaders import AmazonTextractPDFLoaderhttps_loader = AmazonTextractPDFLoader("https://sample-website.com/sample-doc.pdf")
https_document = https_loader.load()
s3_loader = AmazonTextractPDFLoader("s3://sample-bucket/sample-doc.pdf")
s3_document = s3_loader.load()It’s also possible to retailer paperwork in Amazon S3 and seek advice from them utilizing the s3:// URL sample, as defined in Accessing a bucket using S3://, and cross this S3 path to the Amazon Textract PDF loader:
import boto3
textract_client = boto3.shopper('textract', region_name="us-east-2")
file_path = "s3://amazon-textract-public-content/langchain/layout-parser-paper.pdf"
loader = AmazonTextractPDFLoader(file_path, shopper=textract_client)
paperwork = loader.load()A multi-page doc will comprise a number of pages of textual content, which may then be accessed through the paperwork object, which is an inventory of pages. The next code loops by means of the pages within the paperwork object and prints the doc textual content, which is offered through the page_content attribute:
print(len(paperwork))
for doc in paperwork:
print(doc.page_content)Amazon Comprehend and LLMs will be successfully utilized for doc classification. Amazon Comprehend is a pure language processing (NLP) service that makes use of ML to extract insights from textual content. Amazon Comprehend additionally helps customized classification mannequin coaching with format consciousness on paperwork like PDFs, Phrase, and picture codecs. For extra details about utilizing the Amazon Comprehend doc classifier, seek advice from Amazon Comprehend document classifier adds layout support for higher accuracy.
When paired with LLMs, doc classification turns into a robust strategy for managing giant volumes of paperwork. LLMs are useful in doc classification as a result of they’ll analyze the textual content, patterns, and contextual parts within the doc utilizing pure language understanding. It’s also possible to fine-tune them for particular doc courses. When a brand new doc kind launched within the IDP pipeline wants classification, the LLM can course of textual content and categorize the doc given a set of courses. The next is a pattern code that makes use of the LangChain doc loader powered by Amazon Textract to extract the textual content from the doc and use it for classifying the doc. We use the Anthropic Claude v2 mannequin through Amazon Bedrock to carry out the classification.
Within the following instance, we first extract textual content from a affected person discharge report and use an LLM to categorise it given an inventory of three totally different doc varieties—DISCHARGE_SUMMARY, RECEIPT, and PRESCRIPTION. The next screenshot exhibits our report.
from langchain.document_loaders import AmazonTextractPDFLoader
from langchain.llms import Bedrock
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
loader = AmazonTextractPDFLoader("./samples/doc.png")
doc = loader.load()
template = """
Given an inventory of courses, classify the doc into considered one of these courses. Skip any preamble textual content and simply give the category title.
<courses>DISCHARGE_SUMMARY, RECEIPT, PRESCRIPTION</courses>
<doc>{doc_text}<doc>
<classification>"""
immediate = PromptTemplate(template=template, input_variables=["doc_text"])
bedrock_llm = Bedrock(shopper=bedrock, model_id="anthropic.claude-v2")
llm_chain = LLMChain(immediate=immediate, llm=bedrock_llm)
class_name = llm_chain.run(doc[0].page_content)
print(f"The supplied doc is = {class_name}")
Summarization entails condensing a given textual content or doc right into a shorter model whereas retaining its key data. This method is helpful for environment friendly data retrieval, which permits customers to rapidly grasp the important thing factors of a doc with out studying your entire content material. Though Amazon Textract doesn’t immediately carry out textual content summarization, it supplies the foundational capabilities of extracting your entire textual content from paperwork. This extracted textual content serves as an enter to our LLM mannequin for performing textual content summarization duties.
Utilizing the identical pattern discharge report, we use AmazonTextractPDFLoader to extract textual content from this doc. As earlier than, we use the Claude v2 mannequin through Amazon Bedrock and initialize it with a immediate that accommodates the directions on what to do with the textual content (on this case, summarization). Lastly, we run the LLM chain by passing within the extracted textual content from the doc loader. This runs an inference motion on the LLM with the immediate that consists of the directions to summarize, and the doc’s textual content marked by Doc. See the next code:
The code generates the abstract of a affected person discharge abstract report:
The previous instance used a single-page doc to carry out summarization. Nonetheless, you’ll doubtless take care of paperwork containing a number of pages that want summarization. A typical solution to carry out summarization on a number of pages is to first generate summaries on smaller chunks of textual content after which mix the smaller summaries to get a closing abstract of the doc. Notice that this technique requires a number of calls to the LLM. The logic for this may be crafted simply; nonetheless, LangChain supplies a built-in summarize chain that may summarize giant texts (from multi-page paperwork). The summarization can occur both through map_reduce or with stuff choices, which can be found as choices to handle the a number of calls to the LLM. Within the following instance, we use map_reduce to summarize a multi-page doc. The next determine illustrates our workflow.
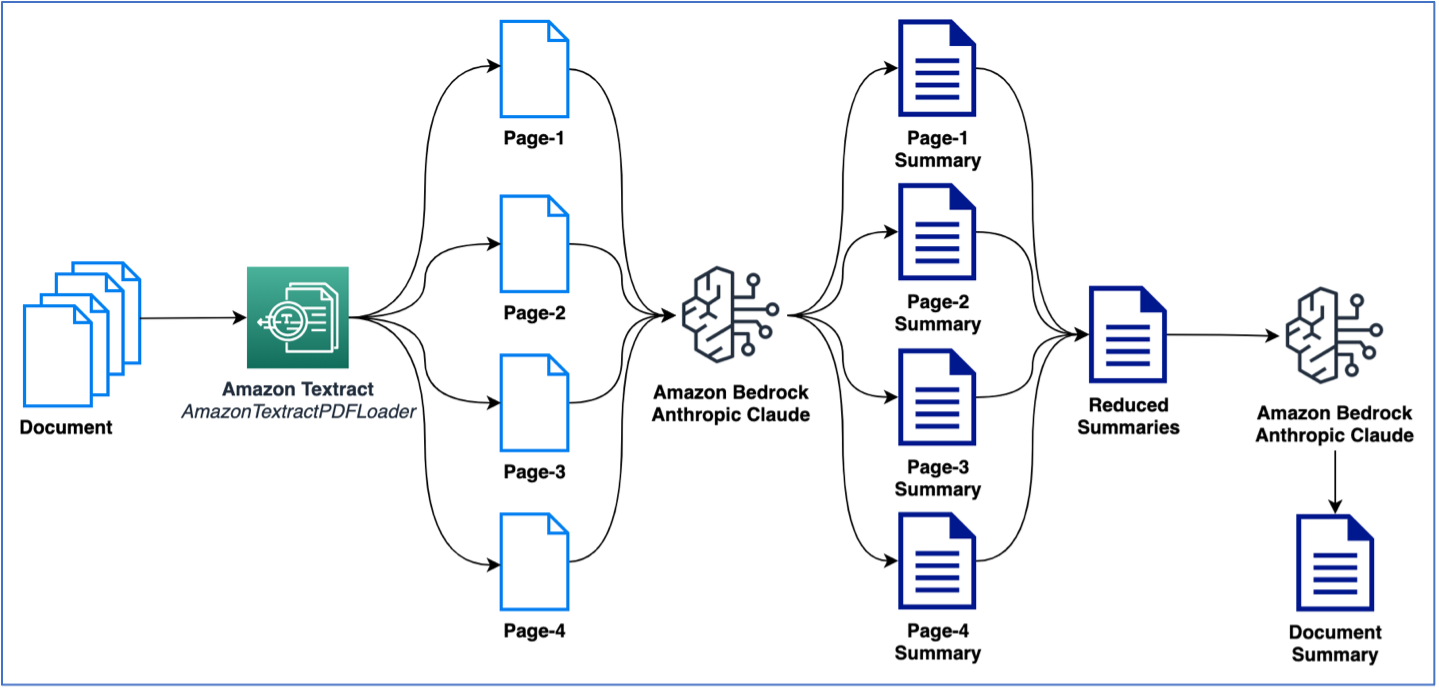
Let’s first begin by extracting the doc and see the whole token depend per web page and the whole variety of pages:
Subsequent, we use LangChain’s built-in load_summarize_chain to summarize your entire doc:
from langchain.chains.summarize import load_summarize_chain
summary_chain = load_summarize_chain(llm=bedrock_llm,
chain_type="map_reduce")
output = summary_chain.run(doc)
print(output.strip())Standardization and Q&A
On this part, we talk about standardization and Q&A duties.
Standardization
Output standardization is a textual content era process the place LLMs are used to offer a constant formatting of the output textual content. This process is especially helpful for automation of key entity extraction that requires the output to be aligned with desired codecs. For instance, we are able to observe immediate engineering greatest practices to fine-tune an LLM to format dates into MM/DD/YYYY format, which can be suitable with a database DATE column. The next code block exhibits an instance of how that is completed utilizing an LLM and immediate engineering. Not solely can we standardize the output format for the date values, we additionally immediate the mannequin to generate the ultimate output in a JSON format in order that it’s simply consumable in our downstream purposes. We use LangChain Expression Language (LCEL) to chain collectively two actions. The primary motion prompts the LLM to generate a JSON format output of simply the dates from the doc. The second motion takes the JSON output and standardizes the date format. Notice that this two-step motion may be carried out in a single step with correct immediate engineering, as we’ll see in normalization and templating.
The output of the previous code pattern is a JSON construction with dates 07/09/2020 and 08/09/2020, that are within the format DD/MM/YYYY and are the affected person’s admit and discharge date from the hospital, respectively, in accordance with the discharge abstract report.
Q&A with Retrieval Augmented Era
LLMs are recognized to retain factual data, sometimes called their world information or world view. When fine-tuned, they’ll produce state-of-the-art outcomes. Nonetheless, there are constraints to how successfully an LLM can entry and manipulate this data. Because of this, in duties that closely depend on particular information, their efficiency won’t be optimum for sure use circumstances. For example, in Q&A eventualities, it’s important for the mannequin to stick strictly to the context supplied within the doc with out relying solely on its world information. Deviating from this will result in misrepresentations, inaccuracies, and even incorrect responses. Essentially the most generally used technique to deal with this drawback is named Retrieval Augmented Generation (RAG). This strategy synergizes the strengths of each retrieval fashions and language fashions, enhancing the precision and high quality of the responses generated.
LLMs may also impose token limitations on account of their reminiscence constraints and the constraints of the {hardware} they run on. To deal with this drawback, methods like chunking are used to divide giant paperwork into smaller parts that match throughout the token limits of LLMs. Then again, embeddings are employed in NLP primarily to seize the semantic which means of phrases and their relationships with different phrases in a high-dimensional house. These embeddings rework phrases into vectors, permitting fashions to effectively course of and perceive textual information. By understanding the semantic nuances between phrases and phrases, embeddings allow LLMs to generate coherent and contextually related outputs. Notice the next key phrases:
- Chunking – This course of breaks down giant quantities of textual content from paperwork into smaller, significant chunks of textual content.
- Embeddings – These are fixed-dimensional vector transformations of every chunk that retain the semantic data from the chunks. These embeddings are subsequently loaded right into a vector database.
- Vector database – It is a database of phrase embeddings or vectors that symbolize the context of phrases. It acts as a information supply that aides NLP duties in doc processing pipelines. The advantage of the vector database right here is that’s permits solely the mandatory context to be supplied to the LLMs throughout textual content era, as we clarify within the following part.
RAG makes use of the facility of embeddings to grasp and fetch related doc segments through the retrieval part. By doing so, RAG can work throughout the token limitations of LLMs, making certain essentially the most pertinent data is chosen for era, leading to extra correct and contextually related outputs.
The next diagram illustrates the mixing of those methods to craft the enter to LLMs, enhancing their contextual understanding and enabling extra related in-context responses. One strategy entails similarity search, using each a vector database and chunking. The vector database shops embeddings representing semantic data, and chunking divides textual content into manageable sections. Utilizing this context from similarity search, LLMs can run duties comparable to query answering and domain-specific operations like classification and enrichment.
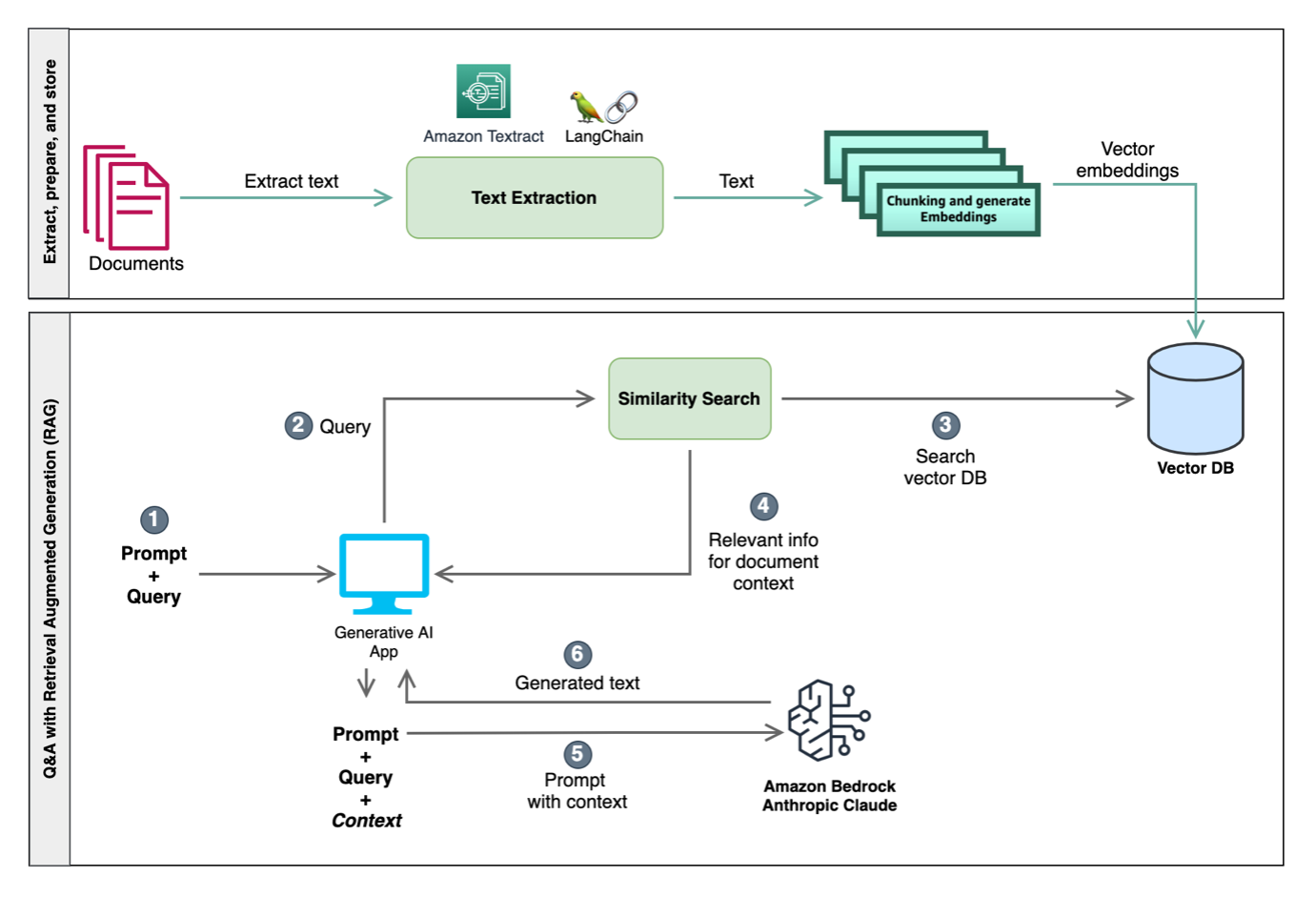
For this publish, we use a RAG-based strategy to carry out in-context Q&A with paperwork. Within the following code pattern, we extract textual content from a doc after which break up the doc into smaller chunks of textual content. Chunking is required as a result of we could have giant multi-page paperwork and our LLMs could have token limits. These chunks are then loaded into the vector database for performing similarity search within the subsequent steps. Within the following instance, we use the Amazon Titan Embed Textual content v1 mannequin, which performs the vector embeddings of the doc chunks:
The code creates a related context for the LLM utilizing the chunks of textual content which are returned by the similarity search motion from the vector database. For this instance, we use an open-source FAISS vector store as a pattern vector database to retailer vector embeddings of every chunk of textual content. We then outline the vector database as a LangChain retriever, which is handed into the RetrievalQA chain. This internally runs a similarity search question on the vector database that returns the highest n (the place n=3 in our instance) chunks of textual content which are related to the query. Lastly, the LLM chain is run with the related context (a gaggle of related chunks of textual content) and the query for the LLM to reply. For a step-by-step code walkthrough of Q&A with RAG, seek advice from the Python pocket book on GitHub.
As a substitute for FAISS, you too can use Amazon OpenSearch Service vector database capabilities, Amazon Relational Database Service (Amazon RDS) for PostgreSQL with the pgvector extension as vector databases, or open-source Chroma Database.
Q&A with tabular information
Tabular information inside paperwork will be difficult for LLMs to course of due to its structural complexity. Amazon Textract will be augmented with LLMs as a result of it permits extracting tables from paperwork in a nested format of parts comparable to web page, desk, and cells. Performing Q&A with tabular information is a multi-step course of, and will be achieved through self-querying. The next is an summary of the steps:
- Extract tables from paperwork utilizing Amazon Textract. With Amazon Textract, the tabular construction (rows, columns, headers) will be extracted from a doc.
- Retailer the tabular information right into a vector database together with metadata data, such because the header names and the outline of every header.
- Use the immediate to assemble a structured question, utilizing an LLM, to derive the info from the desk.
- Use the question to extract the related desk information from the vector database.
For instance, in a financial institution assertion, given the immediate “What are the transactions with greater than $1000 in deposits,” the LLM would full the next steps:
- Craft a question, comparable to
“Question: transactions” , “filter: higher than (Deposit$)”. - Convert the question right into a structured question.
- Apply the structured question to the vector database the place our desk information is saved.
For a step-by-step pattern code walkthrough of Q&A with tabular, seek advice from the Python pocket book in GitHub.
Templating and normalizations
On this part, we have a look at find out how to use immediate engineering methods and LangChain’s built-in mechanism to generate an output with extractions from a doc in a specified schema. We additionally carry out some standardization on the extracted information, utilizing the methods mentioned beforehand. We begin by defining a template for our desired output. It will function a schema and encapsulate the main points about every entity we wish to extract from the doc’s textual content.
Notice that for every of the entities, we use the outline to clarify what that entity is to assist help the LLM in extracting the worth from the doc’s textual content. Within the following pattern code, we use this template to craft our immediate for the LLM together with the textual content extracted from the doc utilizing AmazonTextractPDFLoader and subsequently carry out inference with the mannequin:
As you’ll be able to see, the {keys} a part of the immediate is the keys from our template, and the {particulars} are the keys together with their description. On this case, we don’t immediate the mannequin explicitly with the format of the output aside from specifying within the instruction to generate the output in JSON format. This works for essentially the most half; nonetheless, as a result of the output from LLMs is non-deterministic textual content era, we wish to specify the format explicitly as a part of the instruction within the immediate. To resolve this, we are able to use LangChain’s structured output parser module to reap the benefits of the automated immediate engineering that helps convert our template to a format instruction immediate. We use the template outlined earlier to generate the format instruction immediate as follows:
We then use this variable inside our authentic immediate as an instruction to the LLM in order that it extracts and codecs the output within the desired schema by making a small modification to our immediate:
To this point, we’ve got solely extracted the info out of the doc in a desired schema. Nonetheless, we nonetheless have to carry out some standardization. For instance, we would like the affected person’s admitted date and discharge date to be extracted in DD/MM/YYYY format. On this case, we increase the description of the important thing with the formatting instruction:
Confer with the Python pocket book in GitHub for a full step-by-step walkthrough and clarification.
Spellchecks and corrections
LLMs have demonstrated outstanding skills in understanding and producing human-like textual content. One of many lesser-discussed however immensely helpful purposes of LLMs is their potential in grammatical checks and sentence correction in paperwork. Not like conventional grammar checkers that depend on a set of predefined guidelines, LLMs use patterns that they’ve recognized from huge quantities of textual content information to find out what constitutes as appropriate or fluent language. This implies they’ll detect nuances, context, and subtleties that rule-based methods may miss.
Think about the textual content extracted from a affected person discharge abstract that reads “Affected person Jon Doe, who was admittd with sever pnemonia, has proven important improvemnt and will be safely discharged. Followups are scheduled for nex week.” A standard spellchecker may acknowledge “admittd,” “pneumonia,” “enchancment,” and “nex” as errors. Nonetheless, the context of those errors may result in additional errors or generic ideas. An LLM, geared up with its in depth coaching, may recommend: “Affected person John Doe, who was admitted with extreme pneumonia, has proven important enchancment and will be safely discharged. Observe-ups are scheduled for subsequent week.”
The next is a poorly handwritten pattern doc with the identical textual content as defined beforehand.

We extract the doc with an Amazon Textract doc loader after which instruct the LLM, through immediate engineering, to rectify the extracted textual content to appropriate any spelling and or grammatical errors:
The output of the previous code exhibits the unique textual content extracted by the doc loader adopted by the corrected textual content generated by the LLM:
Needless to say as highly effective as LLMs are, it’s important to view their ideas as simply that—ideas. Though they seize the intricacies of language impressively properly, they aren’t infallible. Some ideas may change the meant which means or tone of the unique textual content. Due to this fact, it’s essential for human reviewers to make use of LLM-generated corrections as a information, not an absolute. The collaboration of human instinct with LLM capabilities guarantees a future the place our written communication isn’t just error-free, but in addition richer and extra nuanced.
Conclusion
Generative AI is altering how one can course of paperwork with IDP to derive insights. Within the publish Enhancing AWS intelligent document processing with generative AI, we mentioned the assorted phases of the pipeline and the way AWS buyer Ricoh is enhancing their IDP pipeline with LLMs. On this publish, we mentioned numerous mechanisms of augmenting the IDP workflow with LLMs through Amazon Bedrock, Amazon Textract, and the favored LangChain framework. You will get began with the brand new Amazon Textract doc loader with LangChain in the present day utilizing the pattern notebooks out there in our GitHub repository. For extra data on working with generative AI on AWS, seek advice from Announcing New Tools for Building with Generative AI on AWS.
In regards to the Authors
 Sonali Sahu is main clever doc processing with the AI/ML companies crew in AWS. She is an creator, thought chief, and passionate technologist. Her core space of focus is AI and ML, and she or he often speaks at AI and ML conferences and meetups all over the world. She has each breadth and depth of expertise in expertise and the expertise business, with business experience in healthcare, the monetary sector, and insurance coverage.
Sonali Sahu is main clever doc processing with the AI/ML companies crew in AWS. She is an creator, thought chief, and passionate technologist. Her core space of focus is AI and ML, and she or he often speaks at AI and ML conferences and meetups all over the world. She has each breadth and depth of expertise in expertise and the expertise business, with business experience in healthcare, the monetary sector, and insurance coverage.
 Anjan Biswas is a Senior AI Companies Options Architect with a concentrate on AI/ML and Knowledge Analytics. Anjan is a part of the world-wide AI companies crew and works with prospects to assist them perceive and develop options to enterprise issues with AI and ML. Anjan has over 14 years of expertise working with international provide chain, manufacturing, and retail organizations, and is actively serving to prospects get began and scale on AWS AI companies.
Anjan Biswas is a Senior AI Companies Options Architect with a concentrate on AI/ML and Knowledge Analytics. Anjan is a part of the world-wide AI companies crew and works with prospects to assist them perceive and develop options to enterprise issues with AI and ML. Anjan has over 14 years of expertise working with international provide chain, manufacturing, and retail organizations, and is actively serving to prospects get began and scale on AWS AI companies.
 Chinmayee Rane is an AI/ML Specialist Options Architect at Amazon Internet Companies. She is obsessed with utilized arithmetic and machine studying. She focuses on designing clever doc processing and generative AI options for AWS prospects. Exterior of labor, she enjoys salsa and bachata dancing.
Chinmayee Rane is an AI/ML Specialist Options Architect at Amazon Internet Companies. She is obsessed with utilized arithmetic and machine studying. She focuses on designing clever doc processing and generative AI options for AWS prospects. Exterior of labor, she enjoys salsa and bachata dancing.





