From textual content to dream job: Constructing an NLP-based job recommender at Expertise.com with Amazon SageMaker
This put up is co-authored by Anatoly Khomenko, Machine Studying Engineer, and Abdenour Bezzouh, Chief Expertise Officer at Expertise.com.
Based in 2011, Talent.com is likely one of the world’s largest sources of employment. The corporate combines paid job listings from their purchasers with public job listings right into a single searchable platform. With over 30 million jobs listed in additional than 75 nations, Expertise.com serves jobs throughout many languages, industries, and distribution channels. The result’s a platform that matches thousands and thousands of job seekers with out there jobs.
Expertise.com’s mission is to centralize all jobs out there on the net to assist job seekers discover their finest match whereas offering them with the perfect search expertise. Its focus is on relevancy, as a result of the order of the really useful jobs is vitally vital to indicate the roles most pertinent to customers’ pursuits. The efficiency of Expertise.com’s matching algorithm is paramount to the success of the enterprise and a key contributor to their customers’ expertise. It’s difficult to foretell which jobs are pertinent to a job seeker based mostly on the restricted quantity of data offered, normally contained to a couple key phrases and a location.
Given this mission, Expertise.com and AWS joined forces to create a job suggestion engine utilizing state-of-the-art pure language processing (NLP) and deep studying mannequin coaching methods with Amazon SageMaker to offer an unmatched expertise for job seekers. This put up reveals our joint strategy to designing a job suggestion system, together with function engineering, deep studying mannequin structure design, hyperparameter optimization, and mannequin analysis that ensures the reliability and effectiveness of our resolution for each job seekers and employers. The system is developed by a staff of devoted utilized machine studying (ML) scientists, ML engineers, and subject material consultants in collaboration between AWS and Expertise.com.
The advice system has pushed an 8.6% improve in clickthrough fee (CTR) in on-line A/B testing in opposition to a earlier XGBoost-based resolution, serving to join thousands and thousands of Expertise.com’s customers to higher jobs.
Overview of resolution
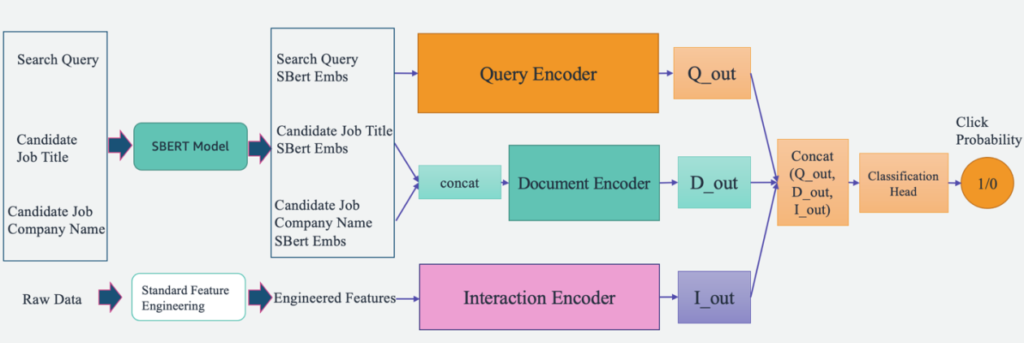
An outline of the system is illustrated within the following determine. The system takes a person’s search question as enter and outputs a ranked record of jobs so as of pertinence. Job pertinence is measured by the clicking likelihood (the likelihood of a job seeker clicking on a job for extra info).

The system contains 4 major parts:
- Mannequin structure – The core of this job suggestion engine is a deep learning-based Triple Tower Pointwise mannequin, which features a question encoder that encodes person search queries, a doc encoder that encodes the job descriptions, and an interplay encoder that processes the previous user-job interplay options. The outputs of the three towers are concatenated and handed by means of a classification head to foretell the job’s click on possibilities. By coaching this mannequin on search queries, job specifics, and historic person interplay information from Expertise.com, this technique supplies customized and extremely related job suggestions to job seekers.
- Characteristic engineering – We carry out two units of function engineering to extract priceless info from enter information and feed it into the corresponding towers within the mannequin. The 2 units are normal function engineering and fine-tuned Sentence-BERT (SBERT) embeddings. We use the usual engineered options as enter into the interplay encoder and feed the SBERT derived embedding into the question encoder and doc encoder.
- Mannequin optimization and tuning – We make the most of superior coaching methodologies to coach, take a look at, and deploy the system with SageMaker. This contains SageMaker Distributed Information Parallel (DDP) coaching, SageMaker Computerized Mannequin Tuning (AMT), studying fee scheduling, and early stopping to enhance mannequin efficiency and coaching pace. Utilizing the DDP coaching framework helped pace up our mannequin coaching to roughly eight occasions quicker.
- Mannequin analysis – We conduct each offline and on-line analysis. We consider the mannequin efficiency with Space Underneath the Curve (AUC) and Imply Common Precision at Okay (mAP@Okay) in offline analysis. Throughout on-line A/B testing, we consider the CTR enhancements.
Within the following sections, we current the main points of those 4 parts.
Deep studying mannequin structure design
We design a Triple Tower Deep Pointwise (TTDP) mannequin utilizing a triple-tower deep studying structure and the pointwise pair modeling strategy. The triple-tower structure supplies three parallel deep neural networks, with every tower processing a set of options independently. This design sample permits the mannequin to be taught distinct representations from totally different sources of data. After the representations from all three towers are obtained, they’re concatenated and handed by means of a classification head to make the ultimate prediction (0–1) on the clicking likelihood (a pointwise modeling setup).
The three towers are named based mostly on the data they course of: the question encoder processes the person search question, the doc encoder processes the candidate job’s documentational contents together with the job title and firm title, and the interplay encoder makes use of related options extracted from previous person interactions and historical past (mentioned extra within the subsequent part).
Every of those towers performs an important position in studying tips on how to advocate jobs:
- Question encoder – The question encoder takes within the SBERT embeddings derived from the person’s job search question. We improve the embeddings by means of an SBERT mannequin we fine-tuned. This encoder processes and understands the person’s job search intent, together with particulars and nuances captured by our domain-specific embeddings.
- Doc encoder – The doc encoder processes the data of every job itemizing. Particularly, it takes the SBERT embeddings of the concatenated textual content from the job title and firm. The instinct is that customers might be extra concerned with candidate jobs which can be extra related to the search question. By mapping the roles and the search queries to the identical vector house (outlined by SBERT), the mannequin can be taught to foretell the likelihood of the potential jobs a job seeker will click on.
- Interplay encoder – The interplay encoder offers with the person’s previous interactions with job listings. The options are produced by way of an ordinary function engineering step, which incorporates calculating reputation metrics for job roles and corporations, establishing context similarity scores, and extracting interplay parameters from earlier person engagements. It additionally processes the named entities recognized within the job title and search queries with a pre-trained named entity recognition (NER) mannequin.
Every tower generates an impartial output in parallel, all of that are then concatenated collectively. This mixed function vector is then handed to foretell the clicking likelihood of a job itemizing for a person question. The triple-tower structure supplies flexibility in capturing complicated relationships between totally different inputs or options, permitting the mannequin to reap the benefits of the strengths of every tower whereas studying extra expressive representations for the given process.
Candidate jobs’ predicted click on possibilities are ranked from excessive to low, producing customized job suggestions. Via this course of, we make sure that each bit of data—whether or not it’s the person’s search intent, job itemizing particulars, or previous interactions—is absolutely captured by a particular tower devoted to it. The complicated relationships between them are additionally captured by means of the mixture of the tower outputs.
Characteristic engineering
We carry out two units of function engineering processes to extract priceless info from the uncooked information and feed it into the corresponding towers within the mannequin: normal function engineering and fine-tuned SBERT embeddings.
Customary function engineering
Our information preparation course of begins with normal function engineering. Total, we outline 4 sorts of options:
- Reputation – We calculate reputation scores on the particular person job degree, occupation degree, and firm degree. This supplies a metric of how enticing a specific job or firm could be.
- Textual similarity – To grasp the contextual relationship between totally different textual parts, we compute similarity scores, together with string similarity between the search question and the job title. This helps us gauge the relevance of a job opening to a job seeker’s search or software historical past.
- Interplay – As well as, we extract interplay options from previous person engagements with job listings. A first-rate instance of that is the embedding similarity between previous clicked job titles and candidate job titles. This measure helps us perceive the similarity between earlier jobs a person has proven curiosity in vs. upcoming job alternatives. This enhances the precision of our job suggestion engine.
- Profile – Lastly, we extract user-defined job curiosity info from the person profile and evaluate it with new job candidates. This helps us perceive if a job candidate matches a person’s curiosity.
An important step in our information preparation is the appliance of a pre-trained NER mannequin. By implementing an NER mannequin, we are able to establish and label named entities inside job titles and search queries. Consequently, this enables us to compute similarity scores between these recognized entities, offering a extra centered and context-aware measure of relatedness. This technique reduces the noise in our information and offers us a extra nuanced, context-sensitive methodology of evaluating jobs.
High-quality-tuned SBERT embeddings
To reinforce the relevance and accuracy of our job suggestion system, we use the facility of SBERT, a strong transformer-based mannequin, recognized for its proficiency in capturing semantic meanings and contexts from textual content. Nonetheless, generic embeddings like SBERT, though efficient, might not absolutely seize the distinctive nuances and terminologies inherent in a particular area similar to ours, which facilities round employment and job searches. To beat this, we fine-tune the SBERT embeddings utilizing our domain-specific information. This fine-tuning course of optimizes the mannequin to higher perceive and course of the industry-specific language, jargon, and context, making the embeddings extra reflective of our particular area. Because of this, the refined embeddings supply improved efficiency in capturing each semantic and contextual info inside our sphere, resulting in extra correct and significant job suggestions for our customers.
The next determine illustrates the SBERT fine-tuning step.
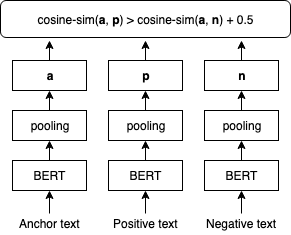
We fine-tune SBERT embeddings utilizing TripletLoss with a cosine distance metric that learns textual content embedding the place anchor and optimistic texts have a better cosine similarity than anchor and unfavorable texts. We use customers’ search queries as anchor texts. We mix job titles and employer names as inputs to the optimistic and unfavorable texts. The optimistic texts are sampled from job postings that the corresponding person clicked on, whereas the unfavorable texts are sampled from job postings that the person didn’t click on on. The next is pattern implementation of the fine-tuning process:
Mannequin coaching with SageMaker Distributed Information Parallel
We use SageMaker Distributed Information Parallel (SMDDP), a function of the SageMaker ML platform that’s constructed on prime of PyTorch DDP. It supplies an optimized surroundings for working PyTorch DDP coaching jobs on the SageMaker platform. It’s designed to considerably pace up deep studying mannequin coaching. It accomplishes this by splitting a big dataset into smaller chunks and distributing them throughout a number of GPUs. The mannequin is replicated on each GPU. Every GPU processes its assigned information independently, and the outcomes are collated and synchronized throughout all GPUs. DDP takes care of gradient communication to maintain mannequin replicas synchronized and overlaps them with gradient computations to hurry up coaching. SMDDP makes use of an optimized AllReduce algorithm to reduce communication between GPUs, decreasing synchronization time and enhancing total coaching pace. The algorithm adapts to totally different community circumstances, making it extremely environment friendly for each on-premises and cloud-based environments. Within the SMDDP structure (as proven within the following determine), distributed coaching can also be scaled utilizing a cluster of many nodes. This implies not simply a number of GPUs in a computing occasion, however many cases with a number of GPUs, which additional hastens coaching.

For extra details about this structure, discuss with Introduction to SageMaker’s Distributed Data Parallel Library.
With SMDDP, we’ve got been in a position to considerably scale back the coaching time for our TTDP mannequin, making it eight occasions quicker. Sooner coaching occasions imply we are able to iterate and enhance our fashions extra shortly, main to higher job suggestions for our customers in a shorter period of time. This effectivity acquire is instrumental in sustaining the competitiveness of our job suggestion engine in a fast-evolving job market.
You’ll be able to adapt your coaching script with the SMDDP with solely three strains of code, as proven within the following code block. Utilizing PyTorch for example, the one factor it is advisable do is import the SMDDP library’s PyTorch shopper (smdistributed.dataparallel.torch.torch_smddp). The shopper registers smddp as a backend for PyTorch.
After you’ve got a working PyTorch script that’s tailored to make use of the distributed information parallel library, you’ll be able to launch a distributed training job using the SageMaker Python SDK.
Evaluating mannequin efficiency
When evaluating the efficiency of a suggestion system, it’s essential to decide on metrics that align carefully with enterprise targets and supply a transparent understanding of the mannequin’s effectiveness. In our case, we use the AUC to judge our TTDP mannequin’s job click on prediction efficiency and the mAP@Okay to evaluate the standard of the ultimate ranked jobs record.
The AUC refers back to the space beneath the receiver working attribute (ROC) curve. It represents the likelihood {that a} randomly chosen optimistic instance might be ranked greater than a randomly chosen unfavorable instance. It ranges from 0–1, the place 1 signifies a really perfect classifier and 0.5 represents a random guess. mAP@Okay is a metric generally used to evaluate the standard of data retrieval methods, similar to our job recommender engine. It measures the typical precision of retrieving the highest Okay related gadgets for a given question or person. It ranges from 0–1, with 1 indicating optimum rating and 0 indicating the bottom potential precision on the given Okay worth. We consider the AUC, mAP@1, and mAP@3. Collectively, these metrics permit us to gauge the mannequin’s skill to tell apart between optimistic and unfavorable courses (AUC) and its success at rating essentially the most related gadgets on the prime (mAP@Okay).
Primarily based on our offline analysis, the TTDP mannequin outperformed the baseline mannequin—the present XGBoost-based manufacturing mannequin—by 16.65% for AUC, 20% for mAP@1, and 11.82% for mAP@3.

Moreover, we designed an internet A/B take a look at to judge the proposed system and ran the take a look at on a proportion of the US e-mail inhabitants for six weeks. In complete, roughly 22 million emails had been despatched utilizing the job really useful by the brand new system. The ensuing uplift in clicks in comparison with the earlier manufacturing mannequin was 8.6%. Expertise.com is step by step rising the proportion to roll out the brand new system to its full inhabitants and channels.
Conclusion
Making a job suggestion system is a posh endeavor. Every job seeker has distinctive wants, preferences, {and professional} experiences that may’t be inferred from a brief search question. On this put up, Expertise.com collaborated with AWS to develop an end-to-end deep learning-based job recommender resolution that ranks lists of jobs to advocate to customers. The Expertise.com staff really loved collaborating with the AWS staff all through the method of fixing this drawback. This marks a big milestone in Expertise.com’s transformative journey, because the staff takes benefit of the facility of deep studying to empower its enterprise.
This venture was fine-tuned utilizing SBERT to generate textual content embeddings. On the time of writing, AWS launched Amazon Titan Embeddings as a part of their foundational fashions (FMs) supplied by means of Amazon Bedrock, which is a totally managed service offering a number of high-performing foundational fashions from main AI corporations. We encourage readers to discover the machine studying methods introduced on this weblog put up and leverage the capabilities offered by AWS, similar to SMDDP, whereas making use of AWS Bedrock’s foundational fashions to create their very own search functionalities.
References
In regards to the authors
 Yi Xiang is a Utilized Scientist II on the Amazon Machine Studying Options Lab, the place she helps AWS prospects throughout totally different industries speed up their AI and cloud adoption.
Yi Xiang is a Utilized Scientist II on the Amazon Machine Studying Options Lab, the place she helps AWS prospects throughout totally different industries speed up their AI and cloud adoption.
 Tong Wang is a Senior Utilized Scientist on the Amazon Machine Studying Options Lab, the place he helps AWS prospects throughout totally different industries speed up their AI and cloud adoption.
Tong Wang is a Senior Utilized Scientist on the Amazon Machine Studying Options Lab, the place he helps AWS prospects throughout totally different industries speed up their AI and cloud adoption.
 Dmitriy Bespalov is a Senior Utilized Scientist on the Amazon Machine Studying Options Lab, the place he helps AWS prospects throughout totally different industries speed up their AI and cloud adoption.
Dmitriy Bespalov is a Senior Utilized Scientist on the Amazon Machine Studying Options Lab, the place he helps AWS prospects throughout totally different industries speed up their AI and cloud adoption.
 Anatoly Khomenko is a Senior Machine Studying Engineer at Expertise.com with a ardour for pure language processing matching good folks to good jobs.
Anatoly Khomenko is a Senior Machine Studying Engineer at Expertise.com with a ardour for pure language processing matching good folks to good jobs.
 Abdenour Bezzouh is an government with greater than 25 years expertise constructing and delivering know-how options that scale to thousands and thousands of shoppers. Abdenour held the place of Chief Expertise Officer (CTO) at Talent.com when the AWS staff designed and executed this explicit resolution for Talent.com.
Abdenour Bezzouh is an government with greater than 25 years expertise constructing and delivering know-how options that scale to thousands and thousands of shoppers. Abdenour held the place of Chief Expertise Officer (CTO) at Talent.com when the AWS staff designed and executed this explicit resolution for Talent.com.
 Dale Jacques is a Senior AI Strategist throughout the Generative AI Innovation Heart the place he helps AWS prospects translate enterprise issues into AI options.
Dale Jacques is a Senior AI Strategist throughout the Generative AI Innovation Heart the place he helps AWS prospects translate enterprise issues into AI options.
 Yanjun Qi is a Senior Utilized Science Supervisor on the Amazon Machine Studying Resolution Lab. She innovates and applies machine studying to assist AWS prospects pace up their AI and cloud adoption.
Yanjun Qi is a Senior Utilized Science Supervisor on the Amazon Machine Studying Resolution Lab. She innovates and applies machine studying to assist AWS prospects pace up their AI and cloud adoption.



