Microsoft Researchers Suggest DeepSpeed-VisualChat: A Leap Ahead in Scalable Multi-Modal Language Mannequin Coaching
Giant language fashions are subtle synthetic intelligence techniques created to grasp and produce language just like people on a big scale. These fashions are helpful in numerous purposes, corresponding to question-answering, content material era, and interactive dialogues. Their usefulness comes from an extended studying course of the place they analyze and perceive large quantities of on-line knowledge.
These fashions are superior devices that enhance human-computer interplay by encouraging a extra subtle and efficient use of language in numerous contexts.
Past studying and writing textual content, analysis is being carried out to show them methods to comprehend and use numerous types of data, corresponding to sounds and pictures. The development in multi-modal capabilities is extremely fascinating and holds nice promise. Modern giant language fashions (LLMs), corresponding to GPT, have proven distinctive efficiency throughout a spread of text-related duties. These fashions develop into superb at completely different interactive duties by utilizing further coaching strategies like supervised fine-tuning or reinforcement studying with human steering. To achieve the extent of experience seen in human specialists, particularly in challenges involving coding, quantitative pondering, mathematical reasoning, and fascinating in conversations like AI chatbots, it’s important to refine the fashions via these coaching strategies.
It’s getting nearer to permitting these fashions to grasp and create materials in numerous codecs, together with photographs, sounds, and movies. Strategies, together with function alignment and mannequin modification, are utilized. Giant imaginative and prescient and language fashions (LVLMs) are one in all these initiatives. Nevertheless, due to issues with coaching and knowledge availability, present fashions have issue addressing sophisticated eventualities, corresponding to multi-image multi-round dialogues, and they’re constrained by way of adaptability and scalability in numerous interplay contexts.
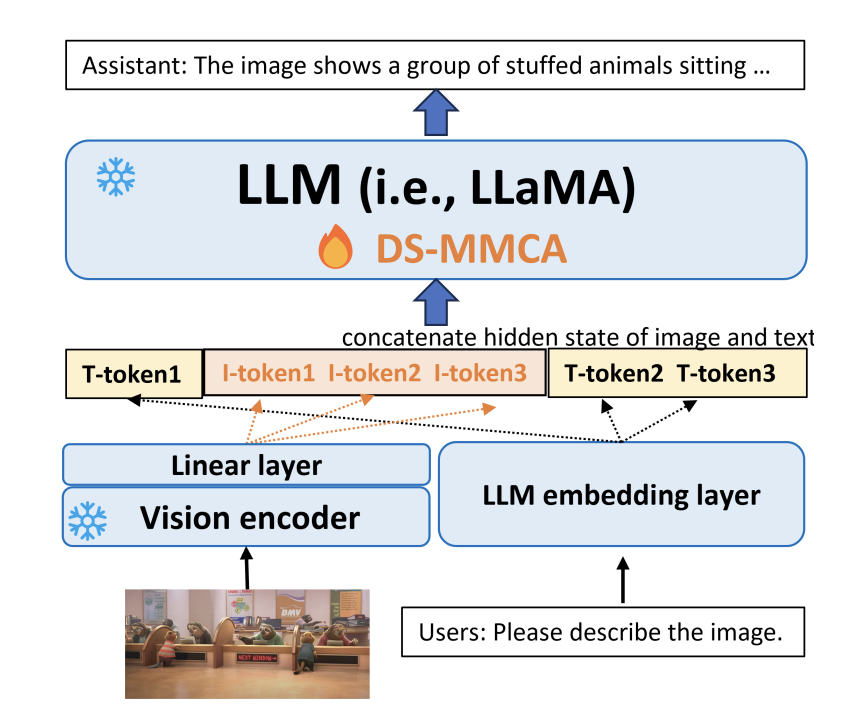
The researchers of Microsoft have dubbed DeepSpeed-VisualChat. This framework enhances LLMs by incorporating multi-modal capabilities, demonstrating excellent scalability even with a language mannequin measurement of 70 billion parameters. This was formulated to facilitate dynamic chats with multi-round and multi-picture dialogues, seamlessly fusing textual content and picture inputs. To extend the adaptability and responsiveness of multi-modal fashions, the framework makes use of Multi-Modal Causal Consideration (MMCA), a way that individually estimates consideration weights throughout a number of modalities. The workforce has used knowledge mixing approaches to beat points with the accessible datasets, leading to a wealthy and assorted coaching atmosphere.
DeepSpeed-VisualChat is distinguished by its excellent scalability, which was made doable by thoughtfully integrating the DeepSpeed framework. This framework reveals distinctive scalability and pushes the bounds of what’s doable in multi-modal dialogue techniques by using a 2 billion parameter visible encoder and a 70 billion parameter language decoder from LLaMA-2.
The researchers emphasize that DeepSpeed-VisualChat’s structure relies on MiniGPT4. On this construction, a picture is encoded utilizing a pre-trained imaginative and prescient encoder after which aligned with the output of the textual content embedding layer’s hidden dimension utilizing a linear layer. These inputs are fed into language fashions like LLaMA2, supported by the ground-breaking Multi-Modal Causal Consideration (MMCA) mechanism. It’s important that in this process, each the language mannequin and the imaginative and prescient encoder keep frozen.
Based on the researchers, basic Cross Consideration (CrA) supplies new dimensions and issues, however Multi-Modal Causal Consideration (MMCA) takes a special strategy. For textual content and picture tokens, MMCA makes use of separate consideration weight matrices such that visible tokens deal with themselves and textual content permits deal with the tokens that got here earlier than them.
DeepSpeed-VisualChat is extra scalable than earlier fashions, in response to real-world outcomes. It enhances adaption in numerous interplay eventualities with out growing complexity or coaching prices. With scaling as much as a language mannequin measurement of 70 billion parameters, it delivers significantly wonderful scalability. This achievement supplies a robust basis for continued development in multi-modal language fashions and constitutes a big step ahead.
Take a look at the Paper and Github. All Credit score For This Analysis Goes To the Researchers on This Venture. Additionally, don’t overlook to affix our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra.
If you like our work, you will love our newsletter..
We’re additionally on WhatsApp. Join our AI Channel on Whatsapp..
Rachit Ranjan is a consulting intern at MarktechPost . He’s presently pursuing his B.Tech from Indian Institute of Expertise(IIT) Patna . He’s actively shaping his profession within the discipline of Synthetic Intelligence and Knowledge Science and is passionate and devoted for exploring these fields.



