Robotically redact PII for machine studying utilizing Amazon SageMaker Information Wrangler
Prospects more and more wish to use deep studying approaches equivalent to large language models (LLMs) to automate the extraction of knowledge and insights. For a lot of industries, knowledge that’s helpful for machine studying (ML) might include personally identifiable data (PII). To make sure buyer privateness and keep regulatory compliance whereas coaching, fine-tuning, and utilizing deep studying fashions, it’s typically essential to first redact PII from supply knowledge.
This put up demonstrates the right way to use Amazon SageMaker Data Wrangler and Amazon Comprehend to routinely redact PII from tabular knowledge as a part of your machine learning operations (ML Ops) workflow.
Drawback: ML knowledge that accommodates PII
PII is outlined as any illustration of knowledge that allows the identification of a person to whom the data applies to be moderately inferred by both direct or oblique means. PII is data that both instantly identifies a person (identify, deal with, social safety quantity or different figuring out quantity or code, phone quantity, e-mail deal with, and so forth) or data that an company intends to make use of to determine particular people along with different knowledge parts, particularly, oblique identification.
Prospects in enterprise domains equivalent to monetary, retail, authorized, and authorities cope with PII knowledge frequently. As a result of numerous authorities rules and guidelines, clients must discover a mechanism to deal with this delicate knowledge with applicable safety measures to keep away from regulatory fines, attainable fraud, and defamation. PII redaction is the method of masking or eradicating delicate data from a doc so it may be used and distributed, whereas nonetheless defending confidential data.
Companies have to ship pleasant buyer experiences and higher enterprise outcomes through the use of ML. Redaction of PII knowledge is commonly a key first step to unlock the bigger and richer knowledge streams wanted to make use of or fine-tune generative AI models, with out worrying about whether or not their enterprise knowledge (or that of their clients) will likely be compromised.
Resolution overview
This resolution makes use of Amazon Comprehend and SageMaker Information Wrangler to routinely redact PII knowledge from a pattern dataset.
Amazon Comprehend is a pure language processing (NLP) service that makes use of ML to uncover insights and relationships in unstructured knowledge, with no managing infrastructure or ML expertise required. It offers performance to find various PII entity types inside textual content, for instance names or bank card numbers. Though the newest generative AI fashions have demonstrated some PII redaction functionality, they often don’t present a confidence rating for PII identification or structured knowledge describing what was redacted. The PII performance of Amazon Comprehend returns each, enabling you to create redaction workflows which can be absolutely auditable at scale. Moreover, utilizing Amazon Comprehend with AWS PrivateLink implies that buyer knowledge by no means leaves the AWS community and is repeatedly secured with the identical knowledge entry and privateness controls as the remainder of your functions.
Just like Amazon Comprehend, Amazon Macie makes use of a rules-based engine to determine delicate knowledge (together with PII) saved in Amazon Simple Storage Service (Amazon S3). Nevertheless, its rules-based method depends on having particular key phrases that point out delicate knowledge situated near that knowledge (within 30 characters). In distinction, the NLP-based ML method of Amazon Comprehend makes use of sematic understanding of longer chunks of textual content to determine PII, making it extra helpful for locating PII inside unstructured knowledge.
Moreover, for tabular knowledge equivalent to CSV or plain textual content recordsdata, Macie returns less detailed location information than Amazon Comprehend (both a row/column indicator or a line quantity, respectively, however not begin and finish character offsets). This makes Amazon Comprehend notably useful for redacting PII from unstructured textual content that will include a mixture of PII and non-PII phrases (for instance, help tickets or LLM prompts) that’s saved in a tabular format.
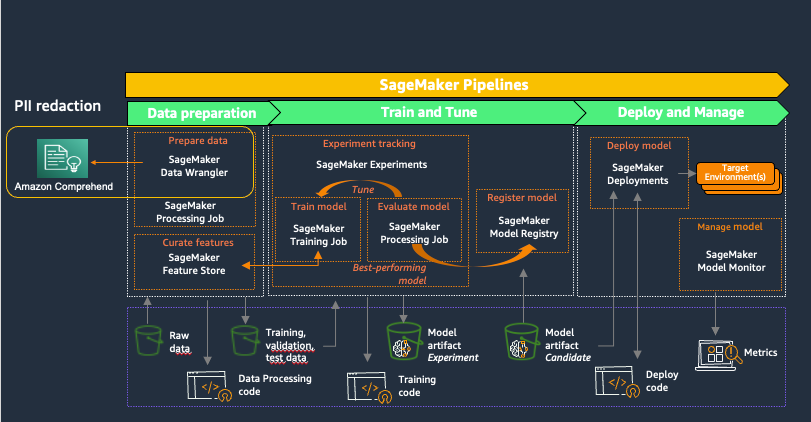
Amazon SageMaker offers purpose-built instruments for ML groups to automate and standardize processes throughout the ML lifecycle. With SageMaker MLOps instruments, groups can simply put together, practice, take a look at, troubleshoot, deploy, and govern ML fashions at scale, boosting productiveness of knowledge scientists and ML engineers whereas sustaining mannequin efficiency in manufacturing. The next diagram illustrates the SageMaker MLOps workflow.
SageMaker Information Wrangler is a function of Amazon SageMaker Studio that gives an end-to-end resolution to import, put together, remodel, featurize, and analyze datasets saved in areas equivalent to Amazon S3 or Amazon Athena, a typical first step within the ML lifecycle. You need to use SageMaker Information Wrangler to simplify and streamline dataset preprocessing and have engineering by both utilizing built-in, no-code transformations or customizing with your personal Python scripts.
Utilizing Amazon Comprehend to redact PII as a part of a SageMaker Information Wrangler knowledge preparation workflow retains all downstream makes use of of the information, equivalent to mannequin coaching or inference, in alignment along with your group’s PII necessities. You may combine SageMaker Information Wrangler with Amazon SageMaker Pipelines to automate end-to-end ML operations, together with knowledge preparation and PII redaction. For extra particulars, discuss with Integrating SageMaker Data Wrangler with SageMaker Pipelines. The remainder of this put up demonstrates a SageMaker Information Wrangler movement that makes use of Amazon Comprehend to redact PII from textual content saved in tabular knowledge format.
This resolution makes use of a public synthetic dataset together with a customized SageMaker Information Wrangler movement, out there as a file in GitHub. The steps to make use of the SageMaker Information Wrangler movement to redact PII are as follows:
- Open SageMaker Studio.
- Obtain the SageMaker Information Wrangler movement.
- Assessment the SageMaker Information Wrangler movement.
- Add a vacation spot node.
- Create a SageMaker Information Wrangler export job.
This walkthrough, together with operating the export job, ought to take 20–25 minutes to finish.
Conditions
For this walkthrough, you must have the next:
Open SageMaker Studio
To open SageMaker Studio, full the next steps:
- On the SageMaker console, select Studio within the navigation pane.
- Select the area and consumer profile
- Select Open Studio.
To get began with the brand new capabilities of SageMaker Information Wrangler, it’s beneficial to upgrade to the latest release.
Obtain the SageMaker Information Wrangler movement
You first have to retrieve the SageMaker Information Wrangler movement file from GitHub and add it to SageMaker Studio. Full the next steps:
- Navigate to the SageMaker Information Wrangler
redact-pii.flowfile on GitHub. - On GitHub, select the obtain icon to obtain the movement file to your native pc.
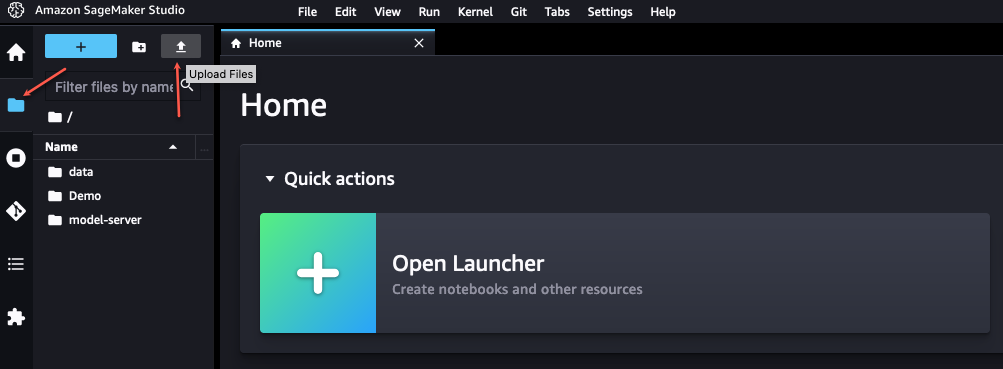
- In SageMaker Studio, select the file icon within the navigation pane.
- Select the add icon, then select
redact-pii.movement.
Assessment the SageMaker Information Wrangler movement
In SageMaker Studio, open redact-pii.movement. After a couple of minutes, the movement will end loading and present the movement diagram (see the next screenshot). The movement accommodates six steps: an S3 Supply step adopted by 5 transformation steps.

On the movement diagram, select the final step, Redact PII. The All Steps pane opens on the proper and reveals an inventory of the steps within the movement. You may develop every step to view particulars, change parameters, and probably add customized code.
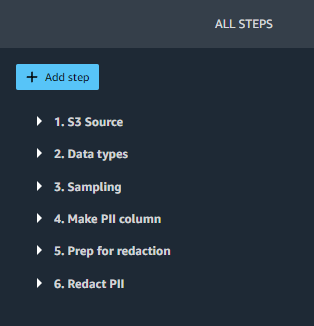
Let’s stroll by means of every step within the movement.
Steps 1 (S3 Supply) and a pair of (Information varieties) are added by SageMaker Information Wrangler each time knowledge is imported for a brand new movement. In S3 Supply, the S3 URI area factors to the pattern dataset, which is a CSV file saved in Amazon S3. The file accommodates roughly 116,000 rows, and the movement units the worth of the Sampling area to 1,000, which implies that SageMaker Information Wrangler will pattern 1,000 rows to show within the consumer interface. Information varieties units the information sort for every column of imported knowledge.
Step 3 (Sampling) units the variety of rows SageMaker Information Wrangler will pattern for an export job to five,000, through the Approximate pattern measurement area. Notice that that is completely different from the variety of rows sampled to show within the consumer interface (Step 1). To export knowledge with extra rows, you may enhance this quantity or take away Step 3.
Steps 4, 5, and 6 use SageMaker Data Wrangler custom transforms. Customized transforms help you run your personal Python or SQL code inside a Information Wrangler movement. The customized code could be written in 4 methods:
- In SQL, utilizing PySpark SQL to switch the dataset
- In Python, utilizing a PySpark knowledge body and libraries to switch the dataset
- In Python, utilizing a pandas knowledge body and libraries to switch the dataset
- In Python, utilizing a user-defined perform to switch a column of the dataset
The Python (pandas) method requires your dataset to suit into reminiscence and may solely be run on a single occasion, limiting its potential to scale effectively. When working in Python with bigger datasets, we suggest utilizing both the Python (PySpark) or Python (user-defined perform) method. SageMaker Information Wrangler optimizes Python user-defined features to provide performance similar to an Apache Spark plugin, while not having to know PySpark or Pandas. To make this resolution as accessible as attainable, this put up makes use of a Python user-defined perform written in pure Python.
Develop Step 4 (Make PII column) to see its particulars. This step combines various kinds of PII knowledge from a number of columns right into a single phrase that’s saved in a brand new column, pii_col. The next desk reveals an instance row containing knowledge.
| customer_name | customer_job | billing_address | customer_email |
| Katie | Journalist | 19009 Vang Squares Suite 805 | hboyd@gmail.com |
That is mixed into the phrase “Katie is a Journalist who lives at 19009 Vang Squares Suite 805 and could be emailed at hboyd@gmail.com”. The phrase is saved in pii_col, which this put up makes use of because the goal column to redact.
Step 5 (Prep for redaction) takes a column to redact (pii_col) and creates a brand new column (pii_col_prep) that’s prepared for environment friendly redaction utilizing Amazon Comprehend. To redact PII from a distinct column, you may change the Enter column area of this step.
There are two components to contemplate to effectively redact knowledge utilizing Amazon Comprehend:
- The cost to detect PII is outlined on a per-unit foundation, the place 1 unit = 100 characters, with a 3-unit minimal cost for every doc. As a result of tabular knowledge typically accommodates small quantities of textual content per cell, it’s usually extra time- and cost-efficient to mix textual content from a number of cells right into a single doc to ship to Amazon Comprehend. Doing this avoids the buildup of overhead from many repeated perform calls and ensures that the information despatched is all the time higher than the 3-unit minimal.
- As a result of we’re doing redaction as one step of a SageMaker Information Wrangler movement, we will likely be calling Amazon Comprehend synchronously. Amazon Comprehend units a 100 KB (100,000 character) limit per synchronous perform name, so we have to make sure that any textual content we ship is below that restrict.
Given these components, Step 5 prepares the information to ship to Amazon Comprehend by appending a delimiter string to the top of the textual content in every cell. For the delimiter, you should use any string that doesn’t happen within the column being redacted (ideally, one that’s as few characters as attainable, as a result of they’re included within the Amazon Comprehend character complete). Including this cell delimiter permits us to optimize the decision to Amazon Comprehend, and will likely be mentioned additional in Step 6.
Notice that if the textual content in any particular person cell is longer than the Amazon Comprehend restrict, the code on this step truncates it to 100,000 characters (roughly equal to fifteen,000 phrases or 30 single-spaced pages). Though this quantity of textual content is unlikely to be saved in in a single cell, you may modify the transformation code to deal with this edge case one other method if wanted.
Step 6 (Redact PII) takes a column identify to redact as enter (pii_col_prep) and saves the redacted textual content to a brand new column (pii_redacted). If you use a Python customized perform remodel, SageMaker Information Wrangler defines an empty custom_func that takes a pandas series (a column of textual content) as enter and returns a modified pandas sequence of the identical size. The next screenshot reveals a part of the Redact PII step.
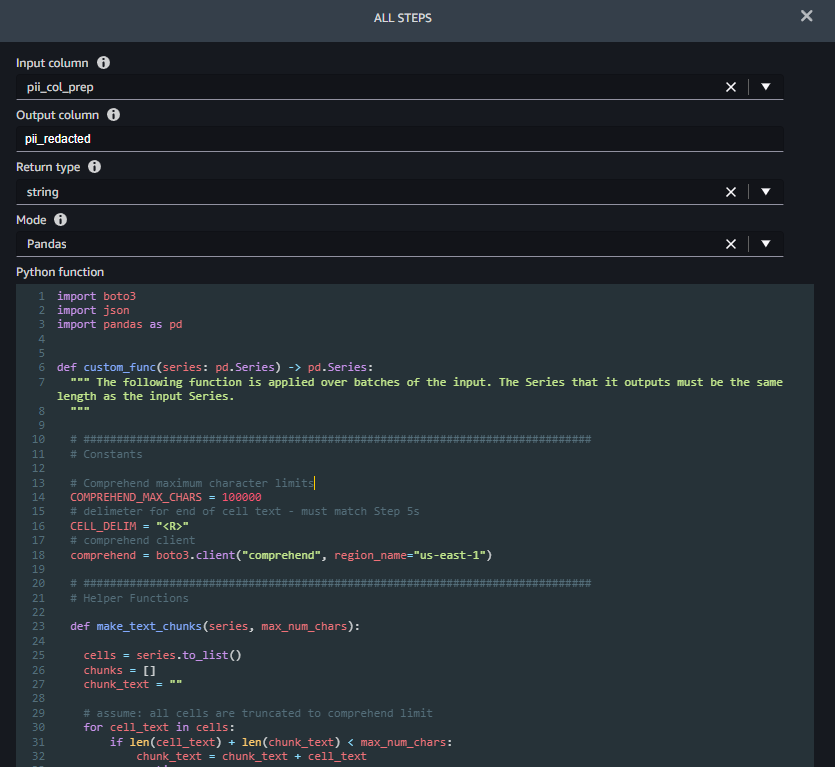
The perform custom_func accommodates two helper (interior) features:
make_text_chunks– This perform does the work of concatenating textual content from particular person cells within the sequence (together with their delimiters) into longer strings (chunks) to ship to Amazon Comprehend.redact_pii– This perform takes textual content as enter, calls Amazon Comprehend to detect PII, redacts any that’s discovered, and returns the redacted textual content. Redaction is finished by changing any PII textual content with the kind of PII present in sq. brackets, for instance John Smith would get replaced with [NAME]. You may modify this perform to exchange PII with any string, together with the empty string (“”) to take away it. You additionally might modify the perform to examine the boldness rating of every PII entity and solely redact if it’s above a particular threshold.
After the interior features are outlined, custom_func makes use of them to do the redaction, as proven within the following code excerpt. When the redaction is full, it converts the chunks again into unique cells, which it saves within the pii_redacted column.
Add a vacation spot node
To see the results of your transformations, SageMaker Information Wrangler helps exporting to Amazon S3, SageMaker Pipelines, Amazon SageMaker Feature Store, and Python code. To export the redacted knowledge to Amazon S3, we first have to create a vacation spot node:
- Within the SageMaker Information Wrangler movement diagram, select the plus signal subsequent to the Redact PII step.
- Select Add vacation spot, then select Amazon S3.
- Present an output identify on your reworked dataset.
- Browse or enter the S3 location to retailer the redacted knowledge file.
- Select Add vacation spot.
You need to now see the vacation spot node on the finish of your knowledge movement.
Create a SageMaker Information Wrangler export job
Now that the vacation spot node has been added, we will create the export job to course of the dataset:
- In SageMaker Information Wrangler, select Create job.
- The vacation spot node you simply added ought to already be chosen. Select Subsequent.
- Settle for the defaults for all different choices, then select Run.
This creates a SageMaker Processing job. To view the standing of the job, navigate to the SageMaker console. Within the navigation pane, develop the Processing part and select Processing jobs. Redacting all 116,000 cells within the goal column utilizing the default export job settings (two ml.m5.4xlarge situations) takes roughly 8 minutes and prices roughly $0.25. When the job is full, obtain the output file with the redacted column from Amazon S3.
Clear up
The SageMaker Information Wrangler utility runs on an ml.m5.4xlarge occasion. To close it down, in SageMaker Studio, select Operating Terminals and Kernels within the navigation pane. Within the RUNNING INSTANCES part, discover the occasion labeled Information Wrangler and select the shutdown icon subsequent to it. This shuts down the SageMaker Information Wrangler utility operating on the occasion.
Conclusion
On this put up, we mentioned the right way to use customized transformations in SageMaker Information Wrangler and Amazon Comprehend to redact PII knowledge out of your ML dataset. You may download the SageMaker Information Wrangler movement and begin redacting PII out of your tabular knowledge right now.
For different methods to reinforce your MLOps workflow utilizing SageMaker Information Wrangler customized transformations, try Authoring custom transformations in Amazon SageMaker Data Wrangler using NLTK and SciPy. For extra knowledge preparation choices, try the weblog put up sequence that explains the right way to use Amazon Comprehend to react, translate, and analyze textual content from both Amazon Athena or Amazon Redshift.
In regards to the Authors
 Tricia Jamison is a Senior Prototyping Architect on the AWS Prototyping and Cloud Acceleration (PACE) Staff, the place she helps AWS clients implement progressive options to difficult issues with machine studying, web of issues (IoT), and serverless applied sciences. She lives in New York Metropolis and enjoys basketball, lengthy distance treks, and staying one step forward of her kids.
Tricia Jamison is a Senior Prototyping Architect on the AWS Prototyping and Cloud Acceleration (PACE) Staff, the place she helps AWS clients implement progressive options to difficult issues with machine studying, web of issues (IoT), and serverless applied sciences. She lives in New York Metropolis and enjoys basketball, lengthy distance treks, and staying one step forward of her kids.
 Neelam Koshiya is an Enterprise Options Architect at AWS. With a background in software program engineering, she organically moved into an structure function. Her present focus helps enterprise clients with their cloud adoption journey for strategic enterprise outcomes with the realm of depth being AI/ML. She is captivated with innovation and inclusion. In her spare time, she enjoys studying and being outdoor.
Neelam Koshiya is an Enterprise Options Architect at AWS. With a background in software program engineering, she organically moved into an structure function. Her present focus helps enterprise clients with their cloud adoption journey for strategic enterprise outcomes with the realm of depth being AI/ML. She is captivated with innovation and inclusion. In her spare time, she enjoys studying and being outdoor.
 Adeleke Coker is a International Options Architect with AWS. He works with clients globally to supply steerage and technical help in deploying manufacturing workloads at scale on AWS. In his spare time, he enjoys studying, studying, gaming and watching sport occasions.
Adeleke Coker is a International Options Architect with AWS. He works with clients globally to supply steerage and technical help in deploying manufacturing workloads at scale on AWS. In his spare time, he enjoys studying, studying, gaming and watching sport occasions.





