Rethinking calibration for in-context studying and immediate engineering – Google Analysis Weblog
Prompting giant language fashions (LLMs) has grow to be an environment friendly studying paradigm for adapting LLMs to a brand new job by conditioning on human-designed directions. The exceptional in-context learning (ICL) capability of LLMs additionally results in environment friendly few-shot learners that may generalize from few-shot input-label pairs. Nonetheless, the predictions of LLMs are extremely delicate and even biased to the choice of templates, label spaces (equivalent to sure/no, true/false, right/incorrect), and demonstration examples, leading to surprising efficiency degradation and obstacles for pursuing sturdy LLM functions. To deal with this downside, calibration strategies have been developed to mitigate the results of those biases whereas recovering LLM efficiency. Although a number of calibration options have been offered (e.g., contextual calibration and domain-context calibration), the sector presently lacks a unified evaluation that systematically distinguishes and explains the distinctive traits, deserves, and drawbacks of every method.
With this in thoughts, in “Batch Calibration: Rethinking Calibration for In-Context Learning and Prompt Engineering”, we conduct a scientific evaluation of the present calibration strategies, the place we each present a unified view and reveal the failure instances. Impressed by these analyses, we suggest Batch Calibration (BC), a easy but intuitive methodology that mitigates the bias from a batch of inputs, unifies varied prior approaches, and successfully addresses the constraints in earlier strategies. BC is zero-shot, self-adaptive (i.e., inference-only), and incurs negligible further prices. We validate the effectiveness of BC with PaLM 2 and CLIP fashions and exhibit state-of-the-art efficiency over earlier calibration baselines throughout greater than 10 pure language understanding and picture classification duties.
Motivation
In pursuit of sensible tips for ICL calibration, we began with understanding the constraints of present strategies. We discover that the calibration downside may be framed as an unsupervised decision boundary studying downside. We observe that uncalibrated ICL may be biased in direction of predicting a category, which we explicitly seek advice from as contextual bias, the a priori propensity of LLMs to foretell sure lessons over others unfairly given the context. For instance, the prediction of LLMs may be biased in direction of predicting essentially the most frequent label, or the label in direction of the top of the demonstration. We discover that, whereas theoretically extra versatile, non-linear boundaries (prototypical calibration) are usually prone to overfitting and will undergo from instability for difficult multi-class duties. Conversely, we discover that linear resolution boundaries may be extra sturdy and generalizable throughout duties. As well as, we discover that counting on further content-free inputs (e.g., “N/A” or random in-domain tokens) because the grounds for estimating the contextual bias is not all the time optimum and will even introduce further bias, relying on the duty kind.
Batch calibration
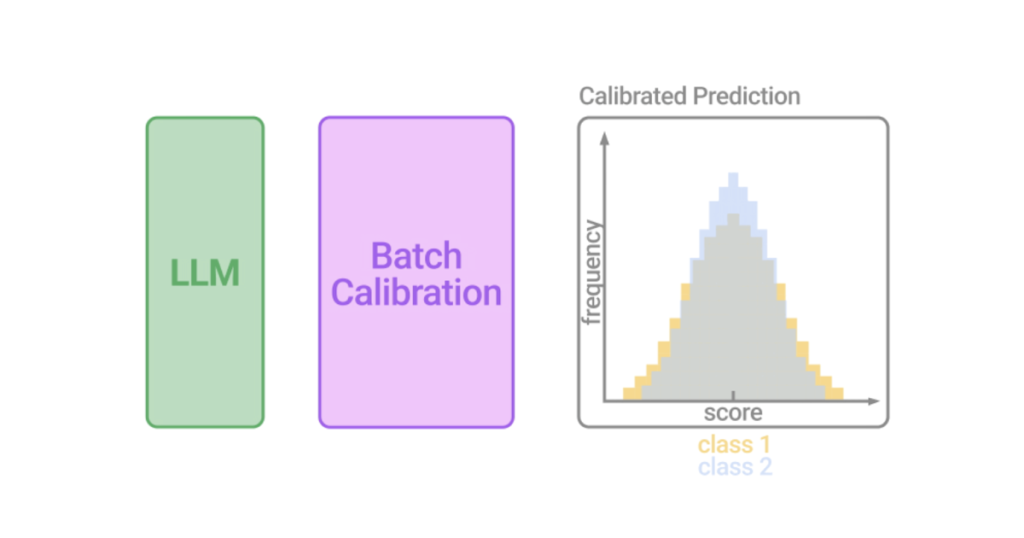
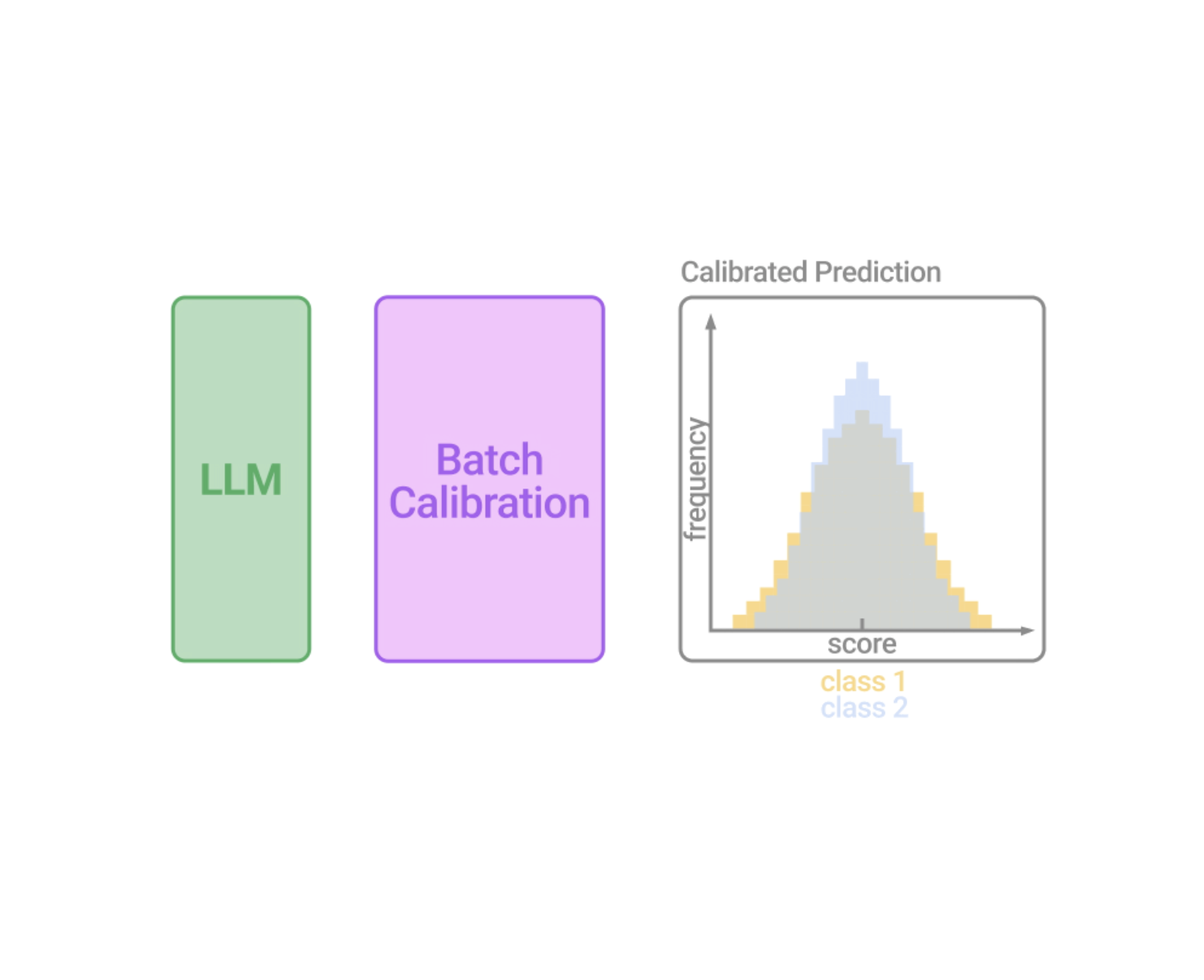
Impressed by the earlier discussions, we designed BC to be a zero-shot, inference-only and generalizable calibration approach with negligible computation value. We argue that essentially the most essential element for calibration is to precisely estimate the contextual bias. We, due to this fact, go for a linear resolution boundary for its robustness, and as an alternative of counting on content-free inputs, we suggest to estimate the contextual bias for every class from a batch in a content-based method by marginalizing the output rating over all samples inside the batch, which is equal to measuring the imply rating for every class (visualized beneath).
We then receive the calibrated chance by dividing the output chance over the contextual prior, which is equal to aligning the log-probability (LLM scores) distribution to the estimated imply of every class. It’s noteworthy that as a result of it requires no further inputs to estimate the bias, this BC process is zero-shot, solely entails unlabeled check samples, and incurs negligible computation prices. We might both compute the contextual bias as soon as all check samples are seen, or alternatively, in an on-the-fly method that dynamically processes the outputs. To take action, we might use a operating estimate of the contextual bias for BC, thereby permitting BC’s calibration time period to be estimated from a small variety of mini-batches that’s subsequently stabilized when extra mini-batches arrive.
 |
| Illustration of Batch Calibration (BC). Batches of demonstrations with in-context examples and check samples are handed into the LLM. Because of sources of implicit bias within the context, the rating distribution from the LLM turns into biased. BC is a modular and adaptable layer possibility appended to the output of the LLM that generates calibrated scores (visualized for illustration solely). |
Experiment design
For pure language duties, we conduct experiments on 13 extra numerous and difficult classification duties, together with the usual GLUE and SuperGLUE datasets. That is in distinction to earlier works that solely report on comparatively easy single-sentence classification duties.. For picture classification duties, we embrace SVHN, EuroSAT, and CLEVR. We conduct experiments primarily on the state-of-the-art PaLM 2 with measurement variants PaLM 2-S, PaLM 2-M, and PaLM 2-L. For VLMs, we report the outcomes on CLIP ViT-B/16.
Outcomes
Notably, BC persistently outperforms ICL, yielding a big efficiency enhancement of 8% and 6% on small and huge variants of PaLM 2, respectively. This exhibits that the BC implementation efficiently mitigates the contextual bias from the in-context examples and unleashes the total potential of LLM in environment friendly studying and fast adaptation to new duties. As well as, BC improves over the state-of-the-art prototypical calibration (PC) baseline by 6% on PaLM 2-S, and surpasses the aggressive contextual calibration (CC) baseline by one other 3% on common on PaLM 2-L. Particularly, BC is a generalizable and cheaper approach throughout all evaluated duties, delivering steady efficiency enchancment, whereas earlier baselines exhibit various levels of efficiency throughout duties.
We analyze the efficiency of BC by various the variety of ICL photographs from 0 to 4, and BC once more outperforms all baseline strategies. We additionally observe an general pattern for improved efficiency when extra photographs can be found, the place BC demonstrates the very best stability.
We additional visualize the choice boundaries of uncalibrated ICL after making use of current calibration strategies and the proposed BC. We present success and failure instances for every baseline methodology, whereas BC is persistently efficient.
 |
| Visualization of the choice boundaries of uncalibrated ICL, and after making use of current calibration strategies and the proposed BC in consultant binary classification duties of SST-2 (high row) and QNLI (backside row) on 1-shot PaLM 2-S. Every axis signifies the LLM rating on the outlined label. |
Robustness and ablation research
We analyze the robustness of BC with respect to frequent immediate engineering design selections that had been beforehand proven to considerably have an effect on LLM efficiency: selections and orders of in-context examples, the immediate template for ICL, and the label area. First, we discover that BC is extra sturdy to ICL selections and might principally obtain the identical efficiency with completely different ICL examples. Moreover, given a single set of ICL photographs, altering the order between every ICL instance has minimal impression on the BC efficiency. Moreover, we analyze the robustness of BC beneath 10 designs of immediate templates, the place BC exhibits constant enchancment over the ICL baseline. Subsequently, although BC improves efficiency, a well-designed template can additional improve the efficiency of BC. Lastly, we look at the robustness of BC to variations in label area designs (see appendix in our paper). Remarkably, even when using unconventional selections equivalent to emoji pairs as labels, resulting in dramatic oscillations of ICL efficiency, BC largely recovers efficiency. This remark demonstrates that BC will increase the robustness of LLM predictions beneath frequent immediate design selections and makes immediate engineering simpler.
 |
| Batch Calibration makes immediate engineering simpler whereas being data-efficient. Information are visualized as a normal box plot, which illustrates values for the median, first and third quartiles, and minimal and most. |
Furthermore, we examine the impression of batch measurement on the efficiency of BC. In distinction to PC, which additionally leverages an unlabeled estimate set, BC is remarkably extra pattern environment friendly, reaching a powerful efficiency with solely round 10 unlabeled samples, whereas PC requires greater than 500 unlabeled samples earlier than its efficiency stabilizes.
 |
| Batch Calibration makes immediate engineering simpler whereas being insensitive to the batch measurement. |
Conclusion
We first revisit earlier calibration strategies whereas addressing two essential analysis questions from an interpretation of resolution boundaries, revealing their failure instances and deficiencies. We then suggest Batch Calibration, a zero-shot and inference-only calibration approach. Whereas methodologically easy and straightforward to implement with negligible computation value, we present that BC scales from a language-only setup to the vision-language context, reaching state-of-the-art efficiency in each modalities. BC considerably improves the robustness of LLMs with respect to immediate designs, and we count on straightforward immediate engineering with BC.
Acknowledgements
This work was performed by Han Zhou, Xingchen Wan, Lev Proleev, Diana Mincu, Jilin Chen, Katherine Heller, Subhrajit Roy. We want to thank Mohammad Havaei and different colleagues at Google Analysis for his or her dialogue and suggestions.






