Reinventing a cloud-native federated studying structure on AWS
Machine studying (ML), particularly deep studying, requires a considerable amount of knowledge for enhancing mannequin efficiency. Prospects typically want to coach a mannequin with knowledge from totally different areas, organizations, or AWS accounts. It’s difficult to centralize such knowledge for ML as a consequence of privateness necessities, excessive price of information switch, or operational complexity.
Federated learning (FL) is a distributed ML strategy that trains ML fashions on distributed datasets. The purpose of FL is to enhance the accuracy of ML fashions by utilizing extra knowledge, whereas preserving the privateness and the locality of distributed datasets. FL will increase the quantity of information accessible for coaching ML fashions, particularly knowledge related to uncommon and new occasions, leading to a extra common ML mannequin. Present companion open-source FL options on AWS embody FedML and NVIDIA FLARE. These open-source packages are deployed within the cloud by operating in digital machines, with out utilizing the cloud-native providers accessible on AWS.
On this weblog, you’ll study to construct a cloud-native FL structure on AWS. By utilizing infrastructure as code (IaC) instruments on AWS, you’ll be able to deploy FL architectures with ease. Additionally, a cloud-native structure takes full benefit of a wide range of AWS providers with confirmed safety and operational excellence, thereby simplifying the event of FL.
We first talk about totally different approaches and challenges of FL. We then display how you can construct a cloud-native FL structure on AWS. The pattern code to construct this structure is accessible on GitHub. We use the AWS Cloud Development Kit (AWS CDK) to deploy the structure with one-click deployment. The pattern code demos a state of affairs the place the server and all purchasers belong to the identical group (the identical AWS account), however their datasets can’t be centralized as a consequence of knowledge localization necessities. The pattern code helps horizontal and synchronous FL for coaching neural community fashions. The ML framework used at FL purchasers is TensorFlow.
Overview of federated studying
FL usually entails a central FL server and a gaggle of purchasers. Purchasers are compute nodes that carry out native coaching. In an FL coaching spherical, the central server first sends a typical international mannequin to a gaggle of purchasers. Purchasers prepare the worldwide mannequin with native knowledge, then present native fashions again to the server. The server aggregates the native fashions into a brand new international mannequin, then begins a brand new coaching spherical. There could also be tens of coaching rounds till the worldwide mannequin converges or till the variety of coaching rounds reaches a threshold. Due to this fact, FL exchanges ML fashions between the central FL server and purchasers, with out transferring coaching knowledge to a central location.
There are two main classes of FL relying on the shopper kind: cross-device and cross-silo. Cross-device FL trains a typical international fashions by retaining all of the coaching knowledge regionally on numerous gadgets, corresponding to cell phones or IoT gadgets, with restricted and unstable community connections. Due to this fact, the design of cross-device FL wants to think about frequent becoming a member of and dropout of FL purchasers.
Cross-silo FL trains a worldwide mannequin on datasets distributed at totally different organizations and geo-distributed knowledge facilities. These datasets are prohibited from transferring out of organizations and knowledge heart areas as a consequence of knowledge safety rules, operational challenges (corresponding to knowledge duplication and synchronization), or excessive prices. In distinction with cross-device FL, cross-silo FL assumes that organizations or knowledge facilities have dependable community connections, highly effective computing sources, and addressable datasets.
FL has been utilized to varied industries, corresponding to finance, healthcare, medicine, and telecommunications, the place privateness preservation is essential or knowledge localization is required. FL has been used to coach a worldwide mannequin for financial crime detection amongst a number of monetary establishments. The worldwide mannequin outperforms fashions educated with solely native datasets by 20%. In healthcare, FL has been used to predict mortality of hospitalized patients primarily based on digital well being information from a number of hospitals. The worldwide mannequin predicting mortality outperforms native fashions in any respect taking part hospitals. FL has additionally been used for brain tumor segmentation. The worldwide fashions for mind tumor segmentation carry out equally to the mannequin educated by accumulating distributed datasets at a central location. In telecommunications, FL might be utilized to edge computing, wi-fi spectrum administration, and 5G core networks.
There are numerous different methods to categorise FL:
- Horizontal or vertical – Relying on the partition of options in distributed datasets, FL might be categorized as horizontal or vertical. In horizontal FL, all distributed datasets have the identical set of options. In vertical FL, datasets have totally different teams of options, requiring extra communication patterns to align samples primarily based on overlapped options.
- Synchronous or asynchronous – Relying on the aggregation technique at an FL server, FL might be categorized as synchronous or asynchronous. A synchronous FL server aggregates native fashions from a specific set of purchasers into a worldwide mannequin. An asynchronous FL server instantly updates the worldwide mannequin after an area mannequin is obtained from a shopper, thereby lowering the ready time and enhancing coaching effectivity.
- Hub-and-spoke or peer-to-peer – The standard FL topology is hub-and-spoke, the place a central FL server coordinates a set of purchasers. One other FL topology is peer-to-peer with none centralized FL server, the place FL purchasers mixture info from neighboring purchasers to study a mannequin.
Challenges in FL
You’ll be able to deal with the next challenges utilizing algorithms operating at FL servers and purchasers in a typical FL structure:
- Information heterogeneity – FL purchasers’ native knowledge can differ (i.e., knowledge heterogeneity) as a consequence of specific geographic places, organizations, or time home windows. Information heterogeneity impacts the accuracy of worldwide fashions, resulting in extra coaching iterations and longer coaching time. Many options have been proposed to mitigate the impression of information heterogeneity, corresponding to optimization algorithms, partial data sharing among clients, and domain adaptation.
- Privateness preservation – Native and international fashions might leak non-public info by way of an adversarial assault. Many privateness preservation approaches have been proposed for FL. A secure aggregation strategy can be utilized to protect the privateness of native fashions exchanged between FL servers and purchasers. Local and global differential privacy approaches certain the privateness loss by including noise to native or international fashions, which offers a managed trade-off between privateness and mannequin accuracy. Relying on the privateness necessities, combos of various privateness preservation approaches can be utilized.
- Federated analytics – Federated analytics offers statistical measurements of distributed datasets with out violating privateness necessities. Federated analytics is necessary not just for knowledge evaluation throughout distributed datasets earlier than coaching, but additionally for mannequin monitoring at inference.
Regardless of these challenges of FL algorithms, it’s essential to construct a safe structure that gives end-to-end FL operations. One necessary problem to constructing such an structure is to allow the benefit of deployment. The structure should coordinate FL servers and purchasers for FL mannequin constructing, coaching, and deployment, together with steady integration and steady improvement (CI/CD) amongst purchasers, traceability, and authentication and entry management for FL servers and purchasers. These options are much like centralized ML operations (ML Ops), however are more difficult to implement as a result of extra events are concerned. The structure additionally must be versatile to implement totally different FL topologies and synchronous or asynchronous aggregation.
Answer overview
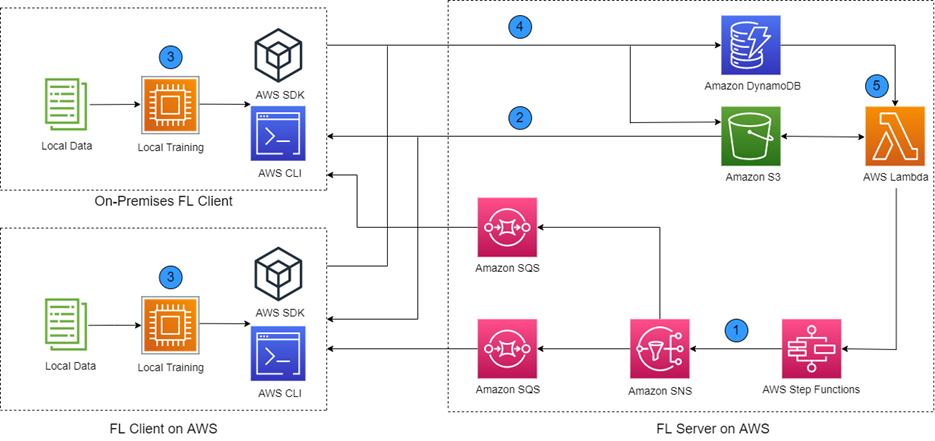
We suggest a cloud-native FL structure on AWS, as proven within the following diagram. The structure features a central FL server and two FL purchasers. In actuality, the variety of FL purchasers can attain tons of for cross-silo purchasers. The FL server should be on the AWS Cloud as a result of it consists of a set of microservices supplied on the cloud. The FL purchasers might be on AWS or on the shopper premises. The FL purchasers host their very own native dataset and have their very own IT and ML system for coaching ML fashions.
Throughout FL mannequin coaching, the FL server and a gaggle of purchasers trade ML fashions. That’s, the purchasers obtain a worldwide ML mannequin from the server, carry out native coaching, and add native fashions to the server. The server downloads native fashions, aggregates native fashions into a brand new international mannequin. This mannequin trade process is a single FL coaching spherical. The FL coaching spherical repeats till the worldwide mannequin reaches a given accuracy or the variety of coaching rounds attain a threshold.

Determine 1 – A cloud-native FL structure for mannequin coaching between a FL server and FL purchasers.
Conditions
To implement this answer, you want an AWS account to launch the providers for a central FL server and the 2 purchasers. On-premises FL purchasers want to put in the AWS Command Line Interface (AWS CLI), which permits entry to the AWS providers on the FL server, together with Amazon Simple Queue Service (Amazon SQS), Amazon Simple Storage Service (Amazon S3), and Amazon DynamoDB.
Federated studying steps
On this part, we stroll by way of the proposed structure in Determine 1. On the FL server, the AWS Step Functions state machine runs a workflow as proven in Determine 2, which executes Steps 0, 1, and 5 from Determine 1. The state machine initiates the AWS providers on the server (Step 0) and iterates FL coaching rounds. For every coaching spherical, the state machine sends out an Amazon Simple Notification Service (Amazon SNS) notification to the subject global_model_ready, together with a process token (Step 1). The state machine then pauses and waits for a callback with the duty token. There are SQS queues subscribing to the global_model_ready matter. Every SQS queue corresponds to an FL shopper and queues the notifications despatched from the server to the shopper.

Determine 2 – The workflow on the Step Features state machine.
Every shopper retains pulling messages from its assigned SQS queue. When a global_model_ready notification is obtained, the shopper downloads a worldwide mannequin from Amazon S3 (Step 2) and begins native coaching (Step 3). Native coaching generates an area mannequin. The shopper then uploads the native mannequin to Amazon S3 and writes the native mannequin info, together with the obtained process token, to the DynamoDB desk (Step 4).
We implement the FL mannequin registry utilizing Amazon S3 and DynamoDB. We use Amazon S3 to retailer the worldwide and native fashions. We use DynamoDB desk to retailer native mannequin info as a result of native mannequin info might be totally different between FL algorithms, which requires a versatile schema supported by a DynamoDB desk.
We additionally allow a DynamoDB stream to set off a Lambda operate, in order that each time a report is written into the DynamoDB desk (when a brand new native mannequin is obtained), a Lambda operate is triggered to examine if required native fashions are collected (Step 5). In that case, the Lambda operate runs the aggregation operate to mixture the native fashions into international fashions. The ensuing international mannequin is written to Amazon S3. The operate additionally sends a callback, together with the duty token retrieved from the DynamoDB desk, to the Step Features state machine. The state machine then determines if the FL coaching needs to be continued with a brand new coaching spherical or needs to be stopped primarily based on a situation, for instance, the variety of coaching rounds reaching a threshold.
Every FL shopper makes use of the next sample code to work together with the FL server. If you wish to customise the native coaching at your FL purchasers, the localTraining() operate might be modified so long as the returned values are local_model_name and local_model_info for importing to the FL server. You’ll be able to choose any ML framework for coaching native fashions at FL purchasers so long as all purchasers use the identical ML framework.
The Lambda operate for operating the aggregation operate on the server has the next sample code. If you wish to customise the aggregation algorithm, you could modify the fedAvg() operate and the output.
Benefits of being cloud-native
This structure is cloud-native and offers end-to-end transparency by utilizing AWS providers with confirmed safety and operational excellence. For instance, you’ll be able to have cross-account purchasers to imagine roles to entry the useful resource on the FL server. For on-premises purchasers, the AWS CLI and AWS SDK for Python (Boto3) at purchasers routinely present safe community connections between the FL server and purchasers. For purchasers on the AWS Cloud, you should utilize AWS PrivateLink and AWS providers with knowledge encryption in transit and at relaxation for knowledge safety. You need to use Amazon Cognito and AWS Identity and Access Management (IAM) for the authentication and entry management of FL servers and purchasers. For deploying the educated international mannequin, you should utilize ML Ops capabilities in Amazon SageMaker.
The cloud-native structure additionally allows integration with custom-made ML frameworks and federated studying algorithms and protocols. For instance, you’ll be able to choose a ML framework for coaching native fashions at FL purchasers and customise totally different aggregation algorithms as scripts operating in Lambda features on the server. Additionally, you’ll be able to modify the workflows in Step Features to accommodate totally different communication protocols between the server and purchasers.
One other benefit of the cloud-native structure is the benefit of deployment by utilizing IaC instruments supplied for the cloud. You need to use the AWS Cloud Development Kit (AWS CDK) and AWS CloudFormation for one-click deployment.
Conclusion
New privateness legal guidelines proceed to be applied worldwide, and know-how infrastructures are quickly increasing throughout a number of areas and lengthening to community edges. Federated studying helps cloud clients use distributed datasets to coach correct ML fashions in a privacy-preserving method. Federated studying additionally helps knowledge localization and doubtlessly saves prices, as a result of it doesn’t require giant quantities of uncooked knowledge to be moved or shared.
You can begin experimenting and constructing cloud-native federated studying architectures on your use instances. You’ll be able to customise the structure to help varied ML frameworks, corresponding to TensorFlow or PyTorch. You too can customise it to help totally different FL algorithms, together with asynchronous federated learning, aggregation algorithms, and differential privacy algorithms. You’ll be able to allow this structure with FL Ops functionalities utilizing ML Ops capabilities in Amazon SageMaker.
Concerning the Authors
 Qiong (Jo) Zhang, PhD, is a Senior Associate SA at AWS, specializing in AI/ML. Her present areas of curiosity embody federated studying, distributed coaching, and generative AI. She holds 30+ patents and has co-authored 100+ journal/convention papers. She can also be the recipient of the Greatest Paper Award at IEEE NetSoft 2016, IEEE ICC 2011, ONDM 2010, and IEEE GLOBECOM 2005.
Qiong (Jo) Zhang, PhD, is a Senior Associate SA at AWS, specializing in AI/ML. Her present areas of curiosity embody federated studying, distributed coaching, and generative AI. She holds 30+ patents and has co-authored 100+ journal/convention papers. She can also be the recipient of the Greatest Paper Award at IEEE NetSoft 2016, IEEE ICC 2011, ONDM 2010, and IEEE GLOBECOM 2005.
 Parker Newton is an utilized scientist in AWS Cryptography. He obtained his Ph.D. in cryptography from U.C. Riverside, specializing in lattice-based cryptography and the complexity of computational studying issues. He’s at the moment working at AWS in safe computation and privateness, designing cryptographic protocols to allow clients to securely run workloads within the cloud whereas preserving the privateness of their knowledge.
Parker Newton is an utilized scientist in AWS Cryptography. He obtained his Ph.D. in cryptography from U.C. Riverside, specializing in lattice-based cryptography and the complexity of computational studying issues. He’s at the moment working at AWS in safe computation and privateness, designing cryptographic protocols to allow clients to securely run workloads within the cloud whereas preserving the privateness of their knowledge.
 Olivia Choudhury, PhD, is a Senior Associate SA at AWS. She helps companions, within the Healthcare and Life Sciences area, design, develop, and scale state-of-the-art options leveraging AWS. She has a background in genomics, healthcare analytics, federated studying, and privacy-preserving machine studying. Outdoors of labor, she performs board video games, paints landscapes, and collects manga.
Olivia Choudhury, PhD, is a Senior Associate SA at AWS. She helps companions, within the Healthcare and Life Sciences area, design, develop, and scale state-of-the-art options leveraging AWS. She has a background in genomics, healthcare analytics, federated studying, and privacy-preserving machine studying. Outdoors of labor, she performs board video games, paints landscapes, and collects manga.
 Gang Fu is a Healthcare Answer Architect at AWS. He holds a PhD in Pharmaceutical Science from the College of Mississippi and has over ten years of know-how and biomedical analysis expertise. He’s enthusiastic about know-how and the impression it may possibly make on healthcare.
Gang Fu is a Healthcare Answer Architect at AWS. He holds a PhD in Pharmaceutical Science from the College of Mississippi and has over ten years of know-how and biomedical analysis expertise. He’s enthusiastic about know-how and the impression it may possibly make on healthcare.
 Kris is a famend chief in machine studying and generative AI, with a profession spanning Goldman Sachs, consulting for main banks, and profitable ventures like Foglight and SiteRock. He based Indigo Capital Administration and co-founded adaptiveARC, specializing in inexperienced vitality tech. Kris additionally helps non-profits aiding assault victims and deprived youth.
Kris is a famend chief in machine studying and generative AI, with a profession spanning Goldman Sachs, consulting for main banks, and profitable ventures like Foglight and SiteRock. He based Indigo Capital Administration and co-founded adaptiveARC, specializing in inexperienced vitality tech. Kris additionally helps non-profits aiding assault victims and deprived youth.
 Invoice Horne is a Normal Supervisor in AWS Cryptography. He leads the Cryptographic Computing Program, consisting of a group of utilized scientists and engineers who’re fixing buyer issues utilizing rising applied sciences like safe multiparty computation and homomorphic encryption. Previous to becoming a member of AWS in 2020 he was the VP and Normal Supervisor of Intertrust Safe Programs and was the Director of Safety Analysis at Hewlett-Packard Enterprise. He’s the writer of 60 peer reviewed publications within the areas of safety and machine studying, and holds 50 granted patents and 58 patents pending.
Invoice Horne is a Normal Supervisor in AWS Cryptography. He leads the Cryptographic Computing Program, consisting of a group of utilized scientists and engineers who’re fixing buyer issues utilizing rising applied sciences like safe multiparty computation and homomorphic encryption. Previous to becoming a member of AWS in 2020 he was the VP and Normal Supervisor of Intertrust Safe Programs and was the Director of Safety Analysis at Hewlett-Packard Enterprise. He’s the writer of 60 peer reviewed publications within the areas of safety and machine studying, and holds 50 granted patents and 58 patents pending.





