Whisper fashions for automated speech recognition now obtainable in Amazon SageMaker JumpStart
As we speak, we’re excited to announce that the OpenAI Whisper basis mannequin is offered for purchasers utilizing Amazon SageMaker JumpStart. Whisper is a pre-trained mannequin for automated speech recognition (ASR) and speech translation. Educated on 680 thousand hours of labelled knowledge, Whisper fashions reveal a powerful capacity to generalize to many datasets and domains with out the necessity for fine-tuning. Sagemaker JumpStart is the machine studying (ML) hub of SageMaker that gives entry to basis fashions along with built-in algorithms and end-to-end answer templates that will help you rapidly get began with ML.
You may also do ASR utilizing Amazon Transcribe ,a fully-managed and repeatedly skilled automated speech recognition service.
On this put up, we present you tips on how to deploy the OpenAI Whisper mannequin and invoke the mannequin to transcribe and translate audio.
The OpenAI Whisper mannequin makes use of the huggingface-pytorch-inference container. As a SageMaker JumpStart mannequin hub buyer, you should use ASR with out having to take care of the mannequin script outdoors of the SageMaker SDK. SageMaker JumpStart fashions additionally enhance safety posture with endpoints that allow community isolation.
Basis fashions in SageMaker
SageMaker JumpStart gives entry to a variety of fashions from in style mannequin hubs together with Hugging Face, PyTorch Hub, and TensorFlow Hub, which you should use inside your ML improvement workflow in SageMaker. Latest advances in ML have given rise to a brand new class of fashions often known as basis fashions, that are sometimes skilled on billions of parameters and may be tailored to a large class of use circumstances, akin to textual content summarization, producing digital artwork, and language translation. As a result of these fashions are costly to coach, clients wish to use current pre-trained basis fashions and fine-tune them as wanted, moderately than prepare these fashions themselves. SageMaker gives a curated record of fashions that you could select from on the SageMaker console.
Now you can discover basis fashions from totally different mannequin suppliers inside SageMaker JumpStart, enabling you to get began with basis fashions rapidly. SageMaker JumpStart provides basis fashions based mostly on totally different duties or mannequin suppliers, and you may simply overview mannequin traits and utilization phrases. You may also strive these fashions utilizing a check UI widget. If you wish to use a basis mannequin at scale, you are able to do so with out leaving SageMaker by utilizing pre-built notebooks from mannequin suppliers. As a result of the fashions are hosted and deployed on AWS, you belief that your knowledge, whether or not used for evaluating or utilizing the mannequin at scale, gained’t be shared with third events.
OpenAI Whisper basis fashions
Whisper is a pre-trained mannequin for ASR and speech translation. Whisper was proposed within the paper Robust Speech Recognition via Large-Scale Weak Supervision by Alec Radford, and others, from OpenAI. The unique code may be discovered in this GitHub repository.
Whisper is a Transformer-based encoder-decoder mannequin, additionally known as a sequence-to-sequence mannequin. It was skilled on 680 thousand hours of labelled speech knowledge annotated utilizing large-scale weak supervision. Whisper fashions reveal a powerful capacity to generalize to many datasets and domains with out the necessity for fine-tuning.
The fashions had been skilled on both English-only knowledge or multilingual knowledge. The English-only fashions had been skilled on the duty of speech recognition. The multilingual fashions had been skilled on speech recognition and speech translation. For speech recognition, the mannequin predicts transcriptions within the identical language because the audio. For speech translation, the mannequin predicts transcriptions to a totally different language to the audio.
Whisper checkpoints are available in 5 configurations of various mannequin sizes. The smallest 4 are skilled on both English-only or multilingual knowledge. The most important checkpoints are multilingual solely. All ten of the pre-trained checkpoints can be found on the Hugging Face hub. The checkpoints are summarized within the following desk with hyperlinks to the fashions on the hub:
| Mannequin identify | Variety of parameters | Multilingual |
| whisper-tiny | 39 M | Yes |
| whisper-base | 74 M | Yes |
| whisper-small | 244 M | Yes |
| whisper-medium | 769 M | Yes |
| whisper-large | 1550 M | Yes |
| whisper-large-v2 | 1550 M | Yes |
Lets discover how you should use Whisper fashions in SageMaker JumpStart.
OpenAI Whisper basis fashions WER and latency comparability
The phrase error fee (WER) for various OpenAI Whisper fashions based mostly on the LibriSpeech test-clean is proven within the following desk. WER is a standard metric for the efficiency of a speech recognition or machine translation system. It measures the distinction between the reference textual content (the bottom fact or the right transcription) and the output of an ASR system when it comes to the variety of errors, together with substitutions, insertions, and deletions which might be wanted to remodel the ASR output into the reference textual content. These numbers have been taken from the Hugging Face web site.
| Mannequin | WER (p.c) |
| whisper-tiny | 7.54 |
| whisper-base | 5.08 |
| whisper-small | 3.43 |
| whisper-medium | 2.9 |
| whisper-large | 3 |
| whisper-large-v2 | 3 |
For this weblog, we took the beneath audio file and in contrast the latency of speech recognition throughout totally different whisper fashions. Latency is the period of time from the second {that a} person sends a request till the time that your utility signifies that the request has been accomplished. The numbers within the following desk symbolize the typical latency for a complete of 100 requests utilizing the identical audio file with the mannequin hosted on the ml.g5.2xlarge occasion.
| Mannequin | Common latency(s) | Mannequin output |
| whisper-tiny | 0.43 | We live in very thrilling instances with machine lighting. The pace of ML mannequin improvement will actually really enhance. However you gained’t get to that finish state that we gained within the subsequent coming years. Except we really make these fashions extra accessible to all people. |
| whisper-base | 0.49 | We live in very thrilling instances with machine studying. The pace of ML mannequin improvement will actually really enhance. However you gained’t get to that finish state that we gained within the subsequent coming years. Except we really make these fashions extra accessible to all people. |
| whisper-small | 0.84 | We live in very thrilling instances with machine studying. The pace of ML mannequin improvement will actually really enhance. However you gained’t get to that finish state that we would like within the subsequent coming years until we really make these fashions extra accessible to all people. |
| whisper-medium | 1.5 | We live in very thrilling instances with machine studying. The pace of ML mannequin improvement will actually really enhance. However you gained’t get to that finish state that we would like within the subsequent coming years until we really make these fashions extra accessible to all people. |
| whisper-large | 1.96 | We live in very thrilling instances with machine studying. The pace of ML mannequin improvement will actually really enhance. However you gained’t get to that finish state that we would like within the subsequent coming years until we really make these fashions extra accessible to all people. |
| whisper-large-v2 | 1.98 | We live in very thrilling instances with machine studying. The pace of ML mannequin improvement will actually really enhance. However you gained’t get to that finish state that we would like within the subsequent coming years until we really make these fashions extra accessible to all people. |
Answer walkthrough
You may deploy Whisper fashions utilizing the Amazon SageMaker console or utilizing an Amazon SageMaker Pocket book. On this put up, we reveal tips on how to deploy the Whisper API utilizing the SageMaker Studio console or a SageMaker Pocket book after which use the deployed mannequin for speech recognition and language translation. The code used on this put up may be present in this GitHub notebook.
Let’s develop every step intimately.
Deploy Whisper from the console
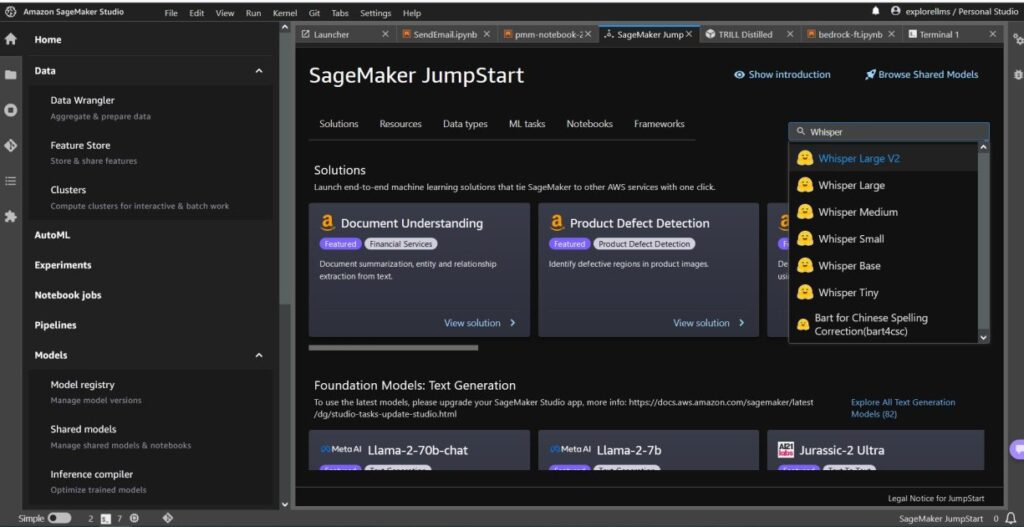
- To get began with SageMaker JumpStart, open the Amazon SageMaker Studio console and go to the launch web page of SageMaker JumpStart and choose Get Began with JumpStart.
- To decide on a Whisper mannequin, you’ll be able to both use the tabs on the high or use the search field on the high proper as proven within the following screenshot. For this instance, use the search field on the highest proper and enter
Whisper, after which choose the suitable Whisper mannequin from the dropdown menu.
- After you choose the Whisper mannequin, you should use the console to deploy the mannequin. You may choose an occasion for deployment or use the default.

Deploy the inspiration mannequin from a Sagemaker Pocket book
The steps to first deploy after which use the deployed mannequin to resolve totally different duties are:
- Arrange
- Choose a mannequin
- Retrieve artifacts and deploy an endpoint
- Use deployed mannequin for ASR
- Use deployed mannequin for language translation
- Clear up the endpoint
Arrange
This pocket book was examined on an ml.t3.medium occasion in SageMaker Studio with the Python 3 (knowledge science) kernel and in an Amazon SageMaker Pocket book occasion with the conda_python3 kernel.
Choose a pre-trained mannequin
Arrange a SageMaker Session utilizing Boto3, after which choose the mannequin ID that you simply wish to deploy.
Retrieve artifacts and deploy an endpoint
Utilizing SageMaker, you’ll be able to carry out inference on the pre-trained mannequin, even with out fine-tuning it first on a brand new dataset. To host the pre-trained mannequin, create an occasion of sagemaker.model.Model and deploy it. The next code makes use of the default occasion ml.g5.2xlarge for the inference endpoint of a whisper-large-v2 mannequin. You may deploy the mannequin on different occasion varieties by passing instance_type within the JumpStartModel class. The deployment may take jiffy.
Automated speech recognition
Subsequent, you learn the pattern audio file, sample1.wav, from a SageMaker Jumpstart public Amazon Simple Storage Service (Amazon S3) location and move it to the predictor for speech recognition. You may exchange this pattern file with every other pattern audio file however be sure the .wav file is sampled at 16 kHz as a result of is required by the automated speech recognition fashions. The enter audio file should be lower than 30 seconds.
This mannequin helps many parameters when performing inference. They embody:
max_length: The mannequin generates textual content till the output size. If specified, it should be a optimistic integer.- language and activity: Specify the output language and activity right here. The mannequin helps the duty of transcription or translation.
max_new_tokens: The utmost numbers of tokens to generate.num_return_sequences: The variety of output sequences returned. If specified, it should be a optimistic integer.num_beams: The variety of beams used within the grasping search. If specified, it should be integer larger than or equal tonum_return_sequences.no_repeat_ngram_size: The mannequin ensures {that a} sequence of phrases ofno_repeat_ngram_sizeisn’t repeated within the output sequence. If specified, it should be a optimistic integer larger than 1.- temperature: This controls the randomness within the output. Larger temperature leads to an output sequence with low-probability phrases and decrease temperature leads to an output sequence with high-probability phrases. If temperature approaches 0, it leads to grasping decoding. If specified, it should be a optimistic float.
early_stopping: IfTrue, textual content technology is completed when all beam hypotheses attain the top of sentence token. If specified, it should be boolean.do_sample: IfTrue, pattern the subsequent phrase for the probability. If specified, it should be boolean.top_k: In every step of textual content technology, pattern from solely thetop_kmost certainly phrases. If specified, it should be a optimistic integer.top_p: In every step of textual content technology, pattern from the smallest potential set of phrases with cumulative chancetop_p. If specified, it should be a float between 0 and 1.
You may specify any subset of the previous parameters when invoking an endpoint. Subsequent, we present you an instance of tips on how to invoke an endpoint with these arguments.
Language translation
To showcase language translation utilizing Whisper fashions, use the next audio file in French and translate it to English. The file should be sampled at 16 kHz (as required by the ASR fashions), so be sure to resample recordsdata if required and ensure your samples don’t exceed 30 seconds.
- Obtain the
sample_french1.wavfrom SageMaker JumpStart from the general public S3 location so it may be handed in payload for translation by the Whisper mannequin.
- Set the duty parameter as
translateand language asFrenchto power the Whisper mannequin to carry out speech translation. - Use predictor to foretell the interpretation of the language. When you obtain shopper error (error 413), verify the payload measurement to the endpoint. Payloads for SageMaker invoke endpoint requests are restricted to about 5 MB.
- The textual content output translated to English from the French audio file follows:
Clear up
After you’ve examined the endpoint, delete the SageMaker inference endpoint and delete the mannequin to keep away from incurring fees.
Conclusion
On this put up, we confirmed you tips on how to check and use OpenAI Whisper fashions to construct attention-grabbing functions utilizing Amazon SageMaker. Check out the inspiration mannequin in SageMaker at this time and tell us your suggestions!
This steerage is for informational functions solely. You must nonetheless carry out your individual unbiased evaluation and take measures to make sure that you adjust to your individual particular high quality management practices and requirements, and the native guidelines, legal guidelines, laws, licenses and phrases of use that apply to you, your content material, and the third-party mannequin referenced on this steerage. AWS has no management or authority over the third-party mannequin referenced on this steerage and doesn’t make any representations or warranties that the third-party mannequin is safe, virus-free, operational, or appropriate together with your manufacturing atmosphere and requirements. AWS doesn’t make any representations, warranties, or ensures that any info on this steerage will end in a specific final result or consequence.
Concerning the authors
 Hemant Singh is an Utilized Scientist with expertise in Amazon SageMaker JumpStart. He received his masters from Courant Institute of Mathematical Sciences and B.Tech from IIT Delhi. He has expertise in engaged on a various vary of machine studying issues inside the area of pure language processing, laptop imaginative and prescient, and time collection evaluation.
Hemant Singh is an Utilized Scientist with expertise in Amazon SageMaker JumpStart. He received his masters from Courant Institute of Mathematical Sciences and B.Tech from IIT Delhi. He has expertise in engaged on a various vary of machine studying issues inside the area of pure language processing, laptop imaginative and prescient, and time collection evaluation.
 Rachna Chadha is a Principal Answer Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that moral and accountable use of AI can enhance society in future and convey economical and social prosperity. In her spare time, Rachna likes spending time together with her household, mountain climbing and listening to music.
Rachna Chadha is a Principal Answer Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that moral and accountable use of AI can enhance society in future and convey economical and social prosperity. In her spare time, Rachna likes spending time together with her household, mountain climbing and listening to music.
 Dr. Ashish Khetan is a Senior Utilized Scientist with Amazon SageMaker built-in algorithms and helps develop machine studying algorithms. He received his PhD from College of Illinois Urbana-Champaign. He’s an lively researcher in machine studying and statistical inference, and has printed many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
Dr. Ashish Khetan is a Senior Utilized Scientist with Amazon SageMaker built-in algorithms and helps develop machine studying algorithms. He received his PhD from College of Illinois Urbana-Champaign. He’s an lively researcher in machine studying and statistical inference, and has printed many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.





