Understanding Classification Metrics: Your Information to Assessing Mannequin Accuracy


Picture by Writer
Analysis metrics are just like the measuring instruments we use to know how nicely a machine studying mannequin is doing its job. They assist us evaluate completely different fashions and determine which one works greatest for a selected process. On the earth of classification issues, there are some generally used metrics to see how good a mannequin is, and it is important to know which metric is correct for our particular downside. After we grasp the main points of every metric, it turns into simpler to determine which one matches the wants of our process.
On this article, we are going to discover the fundamental analysis metrics utilized in classification duties and study conditions the place one metric may be extra related than others.
Earlier than we dive deep into analysis metrics, it’s essential to know the fundamental terminology related to a classification downside.
Floor Fact Labels: These confer with the precise labels corresponding to every instance in our dataset. These are the idea of all analysis and predictions are in comparison with these values.
Predicted Labels: These are the category labels predicted utilizing the machine studying mannequin for every instance in our dataset. We evaluate such predictions to the bottom reality labels utilizing numerous analysis metrics to calculate if the mannequin may be taught the representations in our knowledge.
Now, allow us to solely take into account a binary classification downside for a better understanding. With solely two completely different courses in our dataset, evaluating floor reality labels with predicted labels may end up in one of many following 4 outcomes, as illustrated within the diagram.

Picture by Writer: Utilizing 1 to indicate a constructive label and 0 for a adverse label, the predictions can fall into one of many 4 classes.
True Positives: The mannequin predicts a constructive class label when the bottom reality can also be constructive. That is the required behaviour because the mannequin can efficiently predict a constructive label.
False Positives: The mannequin predicts a constructive class label when the bottom reality label is adverse. The mannequin falsely identifies a knowledge pattern as constructive.
False Negatives: The mannequin predicts a adverse class label for a constructive instance. The mannequin falsely identifies a knowledge pattern as adverse.
True Negatives: The required habits as nicely. The mannequin accurately identifies a adverse pattern, predicting 0 for a knowledge pattern having a floor reality label of 0.
Now, we are able to construct upon these phrases to know how widespread analysis metrics work.
That is the simplest but intuitive manner of assessing a mannequin’s efficiency for classification issues. It measures the proportion of complete labels that the mannequin accurately predicted.
Subsequently, accuracy might be computed as follows:
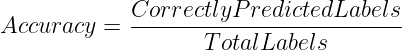
or
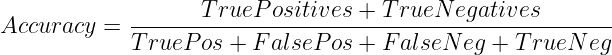
When to Use
Given its simplicity, accuracy is a extensively used metric. It gives start line for verifying if the mannequin can be taught nicely earlier than we use metrics particular to our downside area.
Accuracy is barely appropriate for balanced datasets the place all class labels are in related proportions. If that isn’t the case, and one class label considerably outnumbers the others, the mannequin should still obtain excessive accuracy by all the time predicting the bulk class. The accuracy metric equally penalizes the mistaken predictions for every class, making it unsuitable for imbalanced datasets.
- When Misclassification prices are equal
Accuracy is appropriate for instances the place False Positives or False Negatives are equally dangerous. For instance, for a sentiment evaluation downside, it’s equally dangerous if we classify a adverse textual content as constructive or a constructive textual content as adverse. For such situations, accuracy is an effective metric.
Precision focuses on guaranteeing we get all constructive predictions appropriate. It measures what fraction of the constructive predictions have been really constructive.
Mathematically, it’s represented as
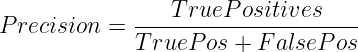
When to Use
- Excessive Value of False Positives
Contemplate a situation the place we’re coaching a mannequin to detect most cancers. It is going to be extra necessary for us that we don’t misclassify a affected person who doesn’t have most cancers i.e. False Optimistic. We need to be assured after we make a constructive prediction as wrongly classifying an individual as cancer-positive can result in pointless stress and bills. Subsequently, we extremely worth that we predict a constructive label solely when the precise label is constructive.
Contemplate one other situation the place we’re constructing a search engine matching consumer queries to a dataset. In such instances, we worth that the search outcomes match carefully to the consumer question. We don’t need to return any doc irrelevant to the consumer, i.e. False Optimistic. Subsequently, we solely predict constructive for paperwork that match carefully to the consumer question. We worth high quality over amount as we desire a small variety of carefully associated outcomes as an alternative of a excessive variety of outcomes which will or will not be related for the consumer. For such situations, we would like excessive precision.
Recall, also called Sensitivity, measures how nicely a mannequin can bear in mind the constructive labels within the dataset. It measures what fraction of the constructive labels in our dataset the mannequin predicts as constructive.
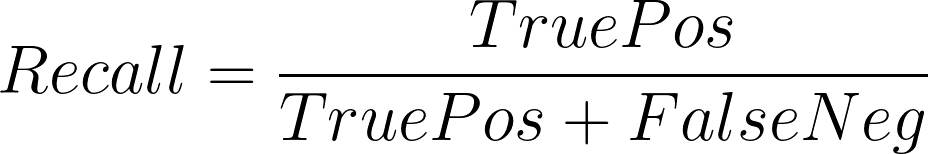
A better recall means the mannequin is healthier at remembering what knowledge samples have constructive labels.
When to Use
- Excessive Value of False Negatives
We use Recall when lacking a constructive label can have extreme penalties. Contemplate a situation the place we’re utilizing a Machine Studying mannequin to detect bank card fraud. In such instances, early detection of points is crucial. We don’t need to miss a fraudulent transaction as it may enhance losses. Therefore, we worth Recall over Precision, the place misclassification of a transaction as deceitful could also be straightforward to confirm and we are able to afford a number of false positives over false negatives.
It’s the harmonic imply of Precision and Recall. It penalizes fashions which have a major imbalance between both metric.
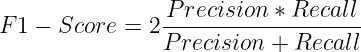
It’s extensively utilized in situations the place each precision and recall are necessary and permits for reaching a steadiness between each.
When to Use
Not like accuracy, the F1-Rating is appropriate for assessing imbalanced datasets as we’re evaluating efficiency based mostly on the mannequin’s capability to recall the minority class whereas sustaining a excessive precision general.
- Precision-Recall Commerce-off
Each metrics are reverse to one another. Empirically, enhancing one can usually result in degradation within the different. F1-Rating aids in balancing each metrics and is helpful in situations the place each Recall and Precision are equally essential. Taking each metrics into consideration for calculation, the F1-Rating is a extensively used metric for evaluating classification fashions.
We have discovered that completely different analysis metrics have particular jobs. Figuring out these metrics helps us select the best one for our process. In actual life, it is not nearly having good fashions; it is about having fashions that match our enterprise wants completely. So, choosing the right metric is like selecting the best instrument to verify our mannequin does nicely the place it issues most.
Nonetheless confused about which metric to make use of? Beginning with accuracy is an effective preliminary step. It gives a fundamental understanding of your mannequin’s efficiency. From there, you possibly can tailor your analysis based mostly in your particular necessities. Alternatively, take into account the F1-Rating, which serves as a flexible metric, putting a steadiness between precision and recall, making it appropriate for numerous situations. It may be your go-to instrument for complete classification analysis.
Muhammad Arham is a Deep Studying Engineer working in Laptop Imaginative and prescient and Pure Language Processing. He has labored on the deployment and optimizations of a number of generative AI functions that reached the worldwide prime charts at Vyro.AI. He’s taken with constructing and optimizing machine studying fashions for clever programs and believes in continuous enchancment.
Muhammad Arham is a Deep Studying Engineer working in Laptop Imaginative and prescient and Pure Language Processing. He has labored on the deployment and optimizations of a number of generative AI functions that reached the worldwide prime charts at Vyro.AI. He’s taken with constructing and optimizing machine studying fashions for clever programs and believes in continuous enchancment.





