Meta AI Researchers Introduce RA-DIT: A New Synthetic Intelligence Method to Retrofitting Language Fashions with Enhanced Retrieval Capabilities for Information-Intensive Duties
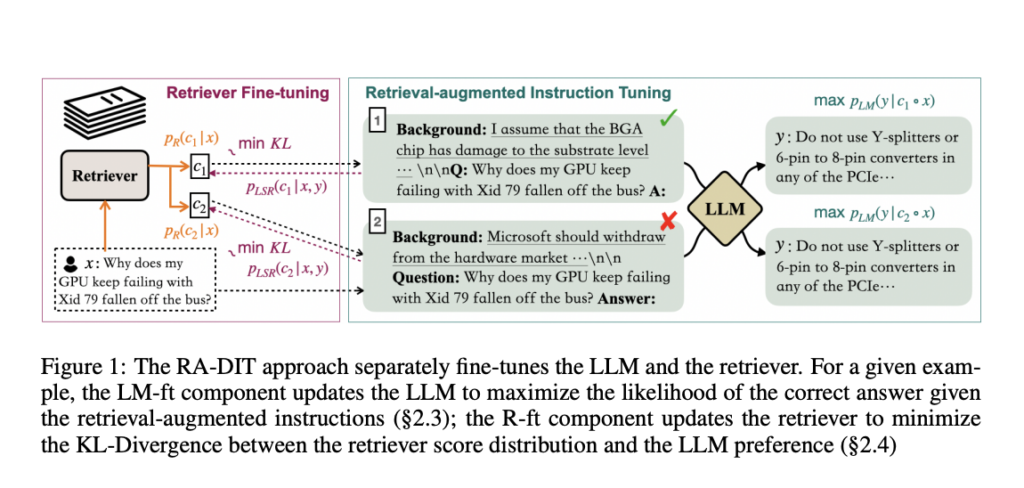
In addressing the restrictions of enormous language fashions (LLMs) when capturing much less widespread data and the excessive computational prices of intensive pre-training, Researchers from Meta introduce Retrieval-Augmented Twin Instruction Tuning (RA-DIT). RA-DIT is a light-weight fine-tuning methodology designed to equip any LLM with environment friendly retrieval capabilities. It operates via two distinct fine-tuning phases, every delivering substantial efficiency enhancements. By optimizing the LM’s use of retrieved data and the retriever’s content material relevance, RA-DIT presents a promising resolution to reinforce LLMs with retrieval capabilities.
RA-DIT gives a light-weight, two-stage fine-tuning technique for enhancing LLMs with retrieval capabilities. It optimizes LLMs to make use of retrieved data higher and refines retrievers to supply extra related outcomes most popular by the LLM. RA-DIT outperforms present retrieval-augmented fashions in knowledge-intensive zero and few-shot studying benchmarks, showcasing its superiority in incorporating exterior data into LLMs for improved efficiency.
Researchers launched RA-DIT for endowing LLMs with retrieval capabilities. RA-DIT includes two key fine-tuning phases: first, enhancing a pre-trained LLM’s utilization of retrieved data, and second, refining the retriever to supply extra contextually related outcomes most popular by the LLM. Their method employs the LLAMA language mannequin, pretrained on an in depth dataset, and makes use of a dual-encoder-based retriever structure initialized with the DRAGON mannequin. Moreover, their technique mentions utilizing parallel in-context retrieval augmentation for extra environment friendly computation of LLM predictions.
Their technique achieves notable efficiency enhancements, with RA-DIT 65B setting new benchmarks in knowledge-intensive zero-and few-shot studying duties, surpassing present in-context Retrieval-Augmented Language Fashions (RALMs) by a major margin. RA-DIT demonstrates the efficacy of light-weight instruction tuning in bettering RALMs’ efficiency, notably in situations requiring entry to in depth exterior data sources.
RA-DIT excels in knowledge-intensive zero-and few-shot studying benchmarks, surpassing present in-context Retrieval-Augmented Language Fashions (RALMs) by as much as +8.9% within the 0-shot setting and +1.4% within the 5-shot location on common. The highest-performing mannequin, RA-DIT 65B, showcases substantial enhancements in duties requiring data utilization and contextual consciousness. RA-DIT preserves parametric data and reasoning capabilities, outperforming base LLAMA fashions on 7 out of 8 commonsense reasoning analysis datasets. Ablation evaluation and parallel in-context retrieval augmentation additional spotlight RA-DIT’s effectiveness in enhancing retrieval-augmented language fashions, notably for in depth data entry.
In conclusion, their method introduces RA-DIT, which reinforces the efficiency of pre-trained language fashions with retrieval capabilities. RA-DIT achieves state-of-the-art leads to zero few-shot evaluations on knowledge-intensive benchmarks, surpassing untuned in-context Retrieval-Augmented Language Fashions and competing successfully with extensively pre-trained strategies. It considerably improves efficiency in duties requiring data utilization and contextual consciousness. RA-DIT 65B outperforms present fashions, demonstrating the effectiveness of light-weight instruction tuning for retrieval-augmented language fashions, particularly in situations involving huge exterior data sources.
Try the Paper. All Credit score For This Analysis Goes To the Researchers on This Challenge. Additionally, don’t neglect to hitch our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra.
If you like our work, you will love our newsletter..
Hiya, My identify is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Specific. I’m presently pursuing a twin diploma on the Indian Institute of Expertise, Kharagpur. I’m captivated with expertise and wish to create new merchandise that make a distinction.