Quick and cost-effective LLaMA 2 fine-tuning with AWS Trainium

Giant language fashions (LLMs) have captured the creativeness and a focus of builders, scientists, technologists, entrepreneurs, and executives throughout a number of industries. These fashions can be utilized for query answering, summarization, translation, and extra in purposes similar to conversational brokers for buyer help, content material creation for advertising, and coding assistants.
Not too long ago, Meta launched Llama 2 for each researchers and business entities, including to the listing of different LLMs, together with MosaicML MPT and Falcon. On this submit, we stroll by means of tips on how to fine-tune Llama 2 on AWS Trainium, a purpose-built accelerator for LLM coaching, to scale back coaching instances and prices. We overview the fine-tuning scripts offered by the AWS Neuron SDK (utilizing NeMo Megatron-LM), the varied configurations we used, and the throughput outcomes we noticed.
In regards to the Llama 2 mannequin
Much like the earlier Llama 1 mannequin and different fashions like GPT, Llama 2 makes use of the Transformer’s decoder-only structure. It is available in three sizes: 7 billion, 13 billion, and 70 billion parameters. In comparison with Llama 1, Llama 2 doubles context size from 2,000 to 4,000, and makes use of grouped-query consideration (just for 70B). Llama 2 pre-trained fashions are educated on 2 trillion tokens, and its fine-tuned fashions have been educated on over 1 million human annotations.
Distributed coaching of Llama 2
To accommodate Llama 2 with 2,000 and 4,000 sequence size, we applied the script utilizing NeMo Megatron for Trainium that helps information parallelism (DP), tensor parallelism (TP), and pipeline parallelism (PP). To be particular, with the brand new implementation of some options like untie phrase embedding, rotary embedding, RMSNorm, and Swiglu activation, we use the generic script of GPT Neuron Megatron-LM to help the Llama 2 coaching script.
Our high-level coaching process is as follows: for our coaching atmosphere, we use a multi-instance cluster managed by the SLURM system for distributed coaching and scheduling underneath the NeMo framework.
First, obtain the Llama 2 mannequin and coaching datasets and preprocess them utilizing the Llama 2 tokenizer. For instance, to make use of the RedPajama dataset, use the next command:
For detailed steerage of downloading fashions and the argument of the preprocessing script, consult with Download LlamaV2 dataset and tokenizer.
Subsequent, compile the mannequin:
After the mannequin is compiled, launch the coaching job with the next script that’s already optimized with the most effective configuration and hyperparameters for Llama 2 (included within the instance code):
Lastly, we monitor TensorBoard to maintain monitor of coaching progress:
For the whole instance code and scripts we talked about, consult with the Llama 7B tutorial and NeMo code within the Neuron SDK to stroll by means of extra detailed steps.
Fantastic-tuning experiments
We fine-tuned the 7B mannequin on the OSCAR (Open Tremendous-large Crawled ALMAnaCH coRpus) and QNLI (Query-answering NLI) datasets in a Neuron 2.12 atmosphere (PyTorch). For every 2,000 and 4,000 sequence size, we optimized some configurations, similar to batchsize and gradient_accumulation, for coaching effectivity. As a fine-tuning technique, we adopted full fine-tuning of all parameters (about 500 steps), which may be prolonged to pre-training with longer steps and bigger datasets (for instance, 1T RedPajama). Sequence parallelism will also be enabled to permit NeMo Megatron to efficiently fine-tune fashions with a bigger sequence size of 4,000. The next desk reveals the configuration and throughput outcomes of the Llama 7B fine-tuning experiment. The throughput scales nearly linearly because the variety of situations improve as much as 4.
| Distributed Library | Datasets | Sequence Size | Variety of Cases | Tensor Parallel | Information Parallel | Pipeline Parellel | World Batch measurement | Throughput (seq/s) |
| Neuron NeMo Megatron | OSCAR | 4096 | 1 | 8 | 4 | 1 | 256 | 3.7 |
| . | . | 4096 | 2 | 8 | 4 | 1 | 256 | 7.4 |
| . | . | 4096 | 4 | 8 | 4 | 1 | 256 | 14.6 |
| . | QNLI | 4096 | 4 | 8 | 4 | 1 | 256 | 14.1 |
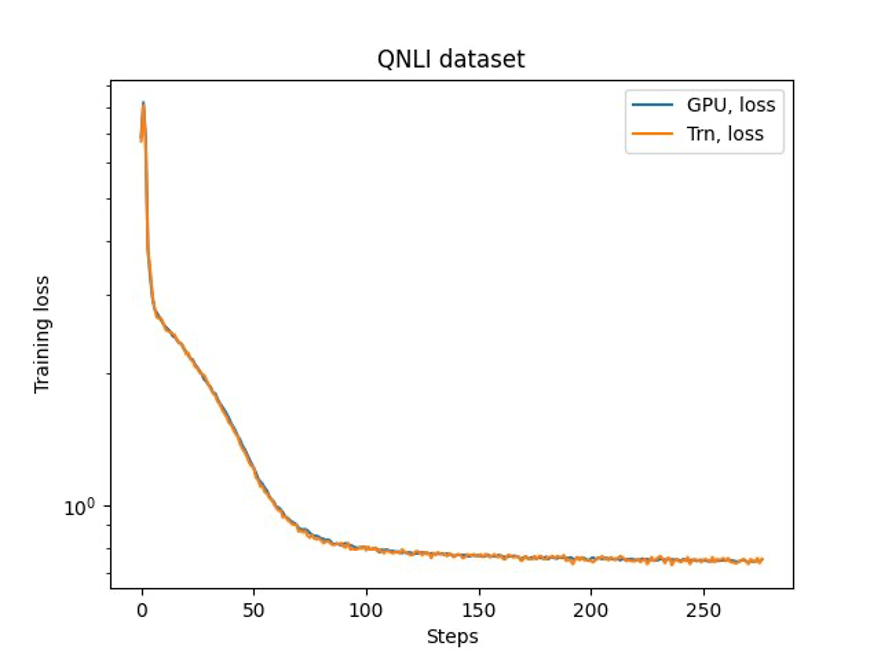
The final step is to confirm the accuracy with the bottom mannequin. We applied a reference script for GPU experiments and confirmed the coaching curves for GPU and Trainium matched as proven within the following determine. The determine illustrates loss curves over the variety of coaching steps on the QNLI dataset. Combined-precision was adopted for GPU (blue), and bf16 with default stochastic rounding for Trainium (orange).
Conclusion
On this submit, we confirmed that Trainium delivers excessive efficiency and cost-effective fine-tuning of Llama 2. For extra assets on utilizing Trainium for distributed pre-training and fine-tuning your generative AI fashions utilizing NeMo Megatron, consult with AWS Neuron Reference for NeMo Megatron.
In regards to the Authors
 Hao Zhou is a Analysis Scientist with Amazon SageMaker. Earlier than that, he labored on growing machine studying strategies for fraud detection for Amazon Fraud Detector. He’s enthusiastic about making use of machine studying, optimization, and generative AI strategies to numerous real-world issues. He holds a PhD in Electrical Engineering from Northwestern College.
Hao Zhou is a Analysis Scientist with Amazon SageMaker. Earlier than that, he labored on growing machine studying strategies for fraud detection for Amazon Fraud Detector. He’s enthusiastic about making use of machine studying, optimization, and generative AI strategies to numerous real-world issues. He holds a PhD in Electrical Engineering from Northwestern College.
 Karthick Gopalswamy is an Utilized Scientist with AWS. Earlier than AWS, he labored as a scientist in Uber and Walmart Labs with a significant give attention to blended integer optimization. At Uber, he centered on optimizing the general public transit community with on-demand SaaS merchandise and shared rides. At Walmart Labs, he labored on pricing and packing optimizations. Karthick has a PhD in Industrial and Methods Engineering with a minor in Operations Analysis from North Carolina State College. His analysis focuses on fashions and methodologies that mix operations analysis and machine studying.
Karthick Gopalswamy is an Utilized Scientist with AWS. Earlier than AWS, he labored as a scientist in Uber and Walmart Labs with a significant give attention to blended integer optimization. At Uber, he centered on optimizing the general public transit community with on-demand SaaS merchandise and shared rides. At Walmart Labs, he labored on pricing and packing optimizations. Karthick has a PhD in Industrial and Methods Engineering with a minor in Operations Analysis from North Carolina State College. His analysis focuses on fashions and methodologies that mix operations analysis and machine studying.
 Xin Huang is a Senior Utilized Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on growing scalable machine studying algorithms. His analysis pursuits are within the space of pure language processing, explainable deep studying on tabular information, and sturdy evaluation of non-parametric space-time clustering. He has revealed many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Collection A.
Xin Huang is a Senior Utilized Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on growing scalable machine studying algorithms. His analysis pursuits are within the space of pure language processing, explainable deep studying on tabular information, and sturdy evaluation of non-parametric space-time clustering. He has revealed many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Collection A.
 Youngsuk Park is a Sr. Utilized Scientist at AWS Annapurna Labs, engaged on growing and coaching basis fashions on AI accelerators. Previous to that, Dr. Park labored on R&D for Amazon Forecast in AWS AI Labs as a lead scientist. His analysis lies within the interaction between machine studying, foundational fashions, optimization, and reinforcement studying. He has revealed over 20 peer-reviewed papers in prime venues, together with ICLR, ICML, AISTATS, and KDD, with the service of organizing workshop and presenting tutorials within the space of time collection and LLM coaching. Earlier than becoming a member of AWS, he obtained a PhD in Electrical Engineering from Stanford College.
Youngsuk Park is a Sr. Utilized Scientist at AWS Annapurna Labs, engaged on growing and coaching basis fashions on AI accelerators. Previous to that, Dr. Park labored on R&D for Amazon Forecast in AWS AI Labs as a lead scientist. His analysis lies within the interaction between machine studying, foundational fashions, optimization, and reinforcement studying. He has revealed over 20 peer-reviewed papers in prime venues, together with ICLR, ICML, AISTATS, and KDD, with the service of organizing workshop and presenting tutorials within the space of time collection and LLM coaching. Earlier than becoming a member of AWS, he obtained a PhD in Electrical Engineering from Stanford College.
 Yida Wang is a principal scientist within the AWS AI workforce of Amazon. His analysis curiosity is in techniques, high-performance computing, and massive information analytics. He presently works on deep studying techniques, with a give attention to compiling and optimizing deep studying fashions for environment friendly coaching and inference, particularly large-scale basis fashions. The mission is to bridge the high-level fashions from numerous frameworks and low-level {hardware} platforms together with CPUs, GPUs, and AI accelerators, in order that completely different fashions can run in excessive efficiency on completely different units.
Yida Wang is a principal scientist within the AWS AI workforce of Amazon. His analysis curiosity is in techniques, high-performance computing, and massive information analytics. He presently works on deep studying techniques, with a give attention to compiling and optimizing deep studying fashions for environment friendly coaching and inference, particularly large-scale basis fashions. The mission is to bridge the high-level fashions from numerous frameworks and low-level {hardware} platforms together with CPUs, GPUs, and AI accelerators, in order that completely different fashions can run in excessive efficiency on completely different units.
 Jun (Luke) Huan is a Principal Scientist at AWS AI Labs. Dr. Huan works on AI and Information Science. He has revealed greater than 160 peer-reviewed papers in main conferences and journals and has graduated 11 PhD college students. He was a recipient of the NSF College Early Profession Improvement Award in 2009. Earlier than becoming a member of AWS, he labored at Baidu Analysis as a distinguished scientist and the pinnacle of Baidu Large Information Laboratory. He based StylingAI Inc., an AI start-up, and labored because the CEO and Chief Scientist in 2019–2021. Earlier than becoming a member of the business, he was the Charles E. and Mary Jane Spahr Professor within the EECS Division on the College of Kansas. From 2015–2018, he labored as a program director on the US NSF in control of its large information program.
Jun (Luke) Huan is a Principal Scientist at AWS AI Labs. Dr. Huan works on AI and Information Science. He has revealed greater than 160 peer-reviewed papers in main conferences and journals and has graduated 11 PhD college students. He was a recipient of the NSF College Early Profession Improvement Award in 2009. Earlier than becoming a member of AWS, he labored at Baidu Analysis as a distinguished scientist and the pinnacle of Baidu Large Information Laboratory. He based StylingAI Inc., an AI start-up, and labored because the CEO and Chief Scientist in 2019–2021. Earlier than becoming a member of the business, he was the Charles E. and Mary Jane Spahr Professor within the EECS Division on the College of Kansas. From 2015–2018, he labored as a program director on the US NSF in control of its large information program.
 Shruti Koparkar is a Senior Product Advertising and marketing Supervisor at AWS. She helps prospects discover, consider, and undertake Amazon EC2 accelerated computing infrastructure for his or her machine studying wants.
Shruti Koparkar is a Senior Product Advertising and marketing Supervisor at AWS. She helps prospects discover, consider, and undertake Amazon EC2 accelerated computing infrastructure for his or her machine studying wants.






