Construct an end-to-end MLOps pipeline for visible high quality inspection on the edge – Half 2

In Part 1 of this collection, we drafted an structure for an end-to-end MLOps pipeline for a visible high quality inspection use case on the edge. It’s architected to automate the complete machine studying (ML) course of, from knowledge labeling to mannequin coaching and deployment on the edge. The concentrate on managed and serverless companies reduces the necessity to function infrastructure to your pipeline and permits you to get began rapidly.
On this put up, we delve deep into how the labeling and mannequin constructing and coaching components of the pipeline are carried out. When you’re notably within the edge deployment facet of the structure, you’ll be able to skip forward to Part 3. We additionally present an accompanying GitHub repo if you wish to deploy and do this your self.
Answer overview
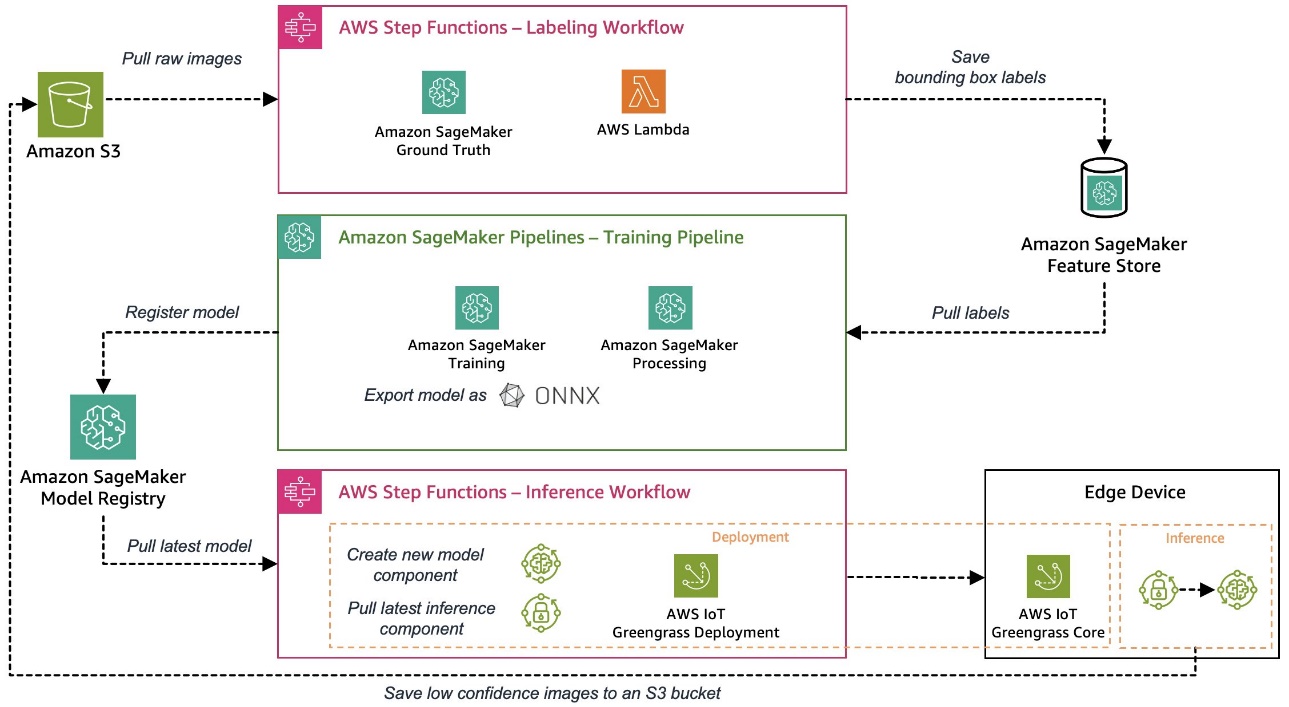
The pattern use case used for this collection is a visible high quality inspection answer that may detect defects on metallic tags, which might be deployed as a part of a producing course of. The next diagram reveals the high-level structure of the MLOps pipeline we outlined at first of this collection. When you haven’t learn it but, we suggest trying out Part 1.
Automating knowledge labeling
Knowledge labeling is an inherently labor-intensive activity that includes people (labelers) to label the information. Labeling for our use case means inspecting a picture and drawing bounding packing containers for every defect that’s seen. This may occasionally sound easy, however we have to maintain quite a lot of issues with a purpose to automate this:
- Present a device for labelers to attract bounding packing containers
- Handle a workforce of labelers
- Guarantee good label high quality
- Handle and model our knowledge and labels
- Orchestrate the entire course of
- Combine it into the CI/CD system
We are able to do all of this with AWS companies. To facilitate the labeling and handle our workforce, we use Amazon SageMaker Ground Truth, a knowledge labeling service that permits you to construct and handle your individual knowledge labeling workflows and workforce. You’ll be able to handle your individual non-public workforce of labelers, or use the ability of exterior labelers by way of Amazon Mechanical Turk or third-party suppliers.
On prime of that, the entire course of might be configured and managed by way of the AWS SDK, which is what we use to orchestrate our labeling workflow as a part of our CI/CD pipeline.
Labeling jobs are used to handle labeling workflows. SageMaker Floor Reality gives out-of-the-box templates for a lot of completely different labeling activity varieties, together with drawing bounding packing containers. For extra particulars on the best way to arrange a labeling job for bounding field duties, take a look at Streamlining data labeling for YOLO object detection in Amazon SageMaker Ground Truth. For our use case, we adapt the task template for bounding box tasks and use human annotators offered by Mechanical Turk to label our pictures by default. The next screenshot reveals what a labeler sees when engaged on a picture.

Let’s speak about label high quality subsequent. The standard of our labels will have an effect on the standard of our ML mannequin. When automating the picture labeling with an exterior human workforce like Mechanical Turk, it’s difficult to make sure a very good and constant label high quality because of the lack of area experience. Generally a non-public workforce of area specialists is required. In our pattern answer, nonetheless, we use Mechanical Turk to implement automated labeling of our pictures.
There are a lot of methods to make sure good label high quality. For extra details about greatest practices, confer with the AWS re:Invent 2019 speak, Build accurate training datasets with Amazon SageMaker Ground Truth. As a part of this pattern answer, we determined to concentrate on the next:
Lastly, we’d like to consider the best way to retailer our labels to allow them to be reused for coaching later and allow traceability of used mannequin coaching knowledge. The output of a SageMaker Ground Truth labeling job is a file in JSON-lines format containing the labels and extra metadata. We determined to make use of the offline store of Amazon SageMaker Feature Store to retailer our labels. In comparison with merely storing the labels on Amazon Simple Storage Service (Amazon S3), it gives us with just a few distinct benefits:
- It shops a whole historical past of function values, mixed with point-in-time queries. This enable us to simply model our dataset and guarantee traceability.
- As a central function retailer, it promotes reusability and visibility of our knowledge.
For an introduction to SageMaker Characteristic Retailer, confer with Getting started with Amazon SageMaker Feature Store. SageMaker Characteristic Retailer helps storing options in tabular format. In our instance, we retailer the next options for every labeled picture:
- The placement the place the picture is saved on Amazon S3
- Picture dimensions
- The bounding field coordinates and sophistication values
- A standing flag indicating whether or not the label has been accredited to be used in coaching
- The labeling job title used to create the label
The next screenshot reveals what a typical entry within the function retailer would possibly appear like.
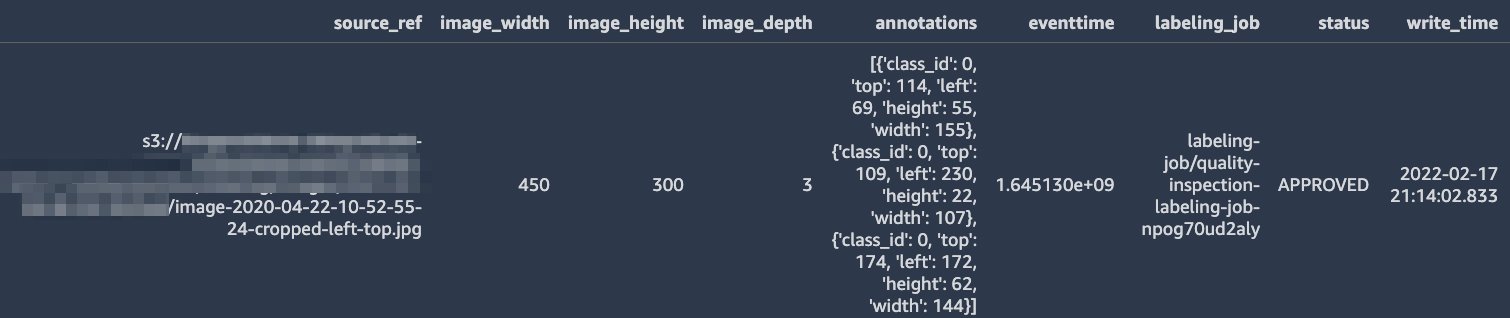
With this format, we will simply question the function retailer and work with acquainted instruments like Pandas to assemble a dataset for use for coaching later.
Orchestrating knowledge labeling
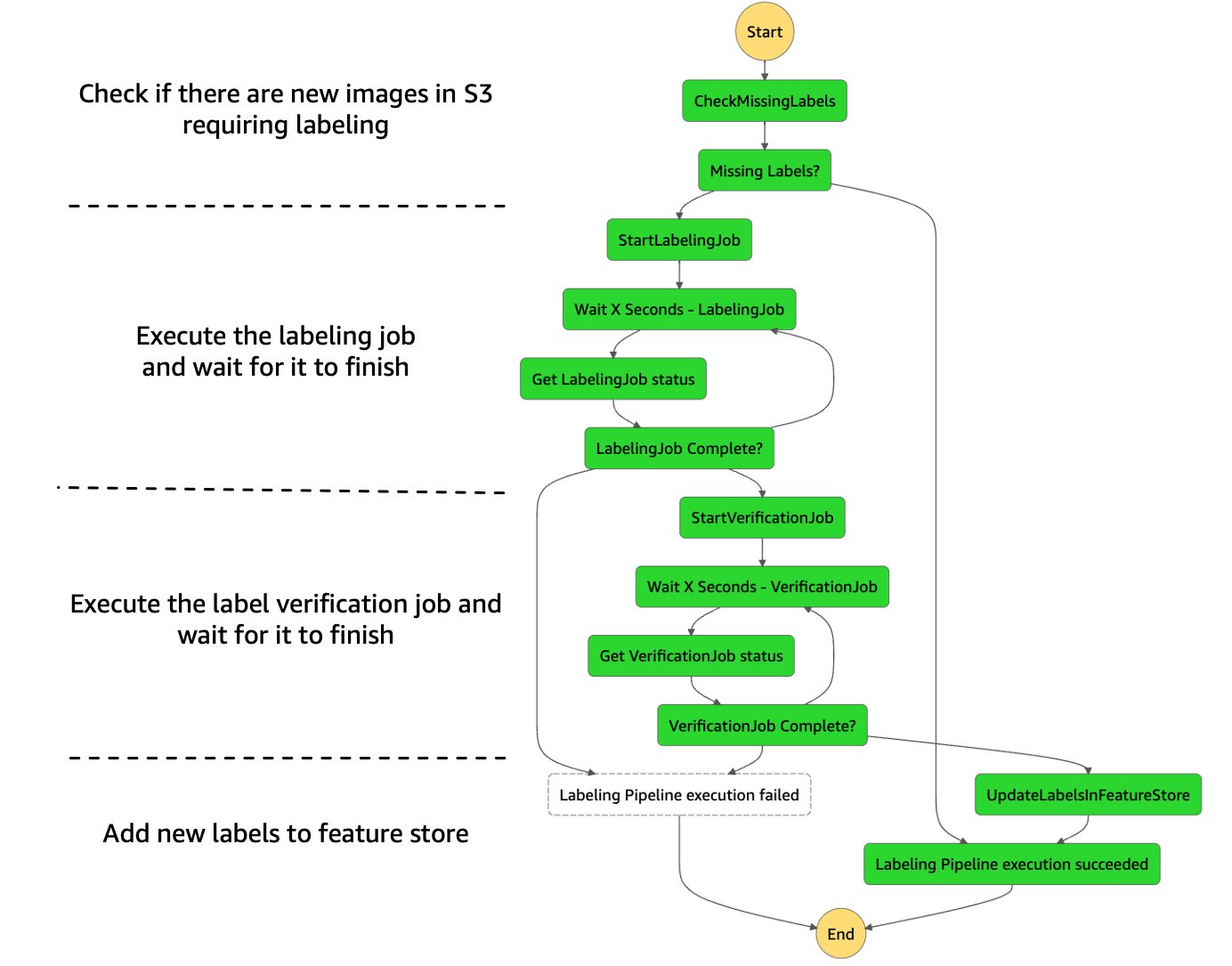
Lastly, it’s time to automate and orchestrate every of the steps of our labeling pipeline! For this we use AWS Step Functions, a serverless workflow service that gives us with API integrations to rapidly orchestrate and visualize the steps in our workflow. We additionally use a set of AWS Lambda capabilities for among the extra advanced steps, particularly the next:
- Verify if there are new pictures that require labeling in Amazon S3
- Put together the information within the required enter format and begin the labeling job
- Put together the information within the required enter format and begin the label verification job
- Write the ultimate set of labels to the function retailer
The next determine reveals what the total Step Features labeling state machine appears to be like like.
Labeling: Infrastructure deployment and integration into CI/CD
The ultimate step is to combine the Step Features workflow into our CI/CD system and be sure that we deploy the required infrastructure. To perform this activity, we use the AWS Cloud Development Kit (AWS CDK) to create the entire required infrastructure, just like the Lambda capabilities and Step Features workflow. With CDK Pipelines, a module of AWS CDK, we create a pipeline in AWS CodePipeline that deploys adjustments to our infrastructure and triggers a further pipeline to start out the Step Features workflow. The Step Functions integration in CodePipeline makes this activity very straightforward. We use Amazon EventBridge and CodePipeline Supply actions to ensure that the pipeline is triggered on a schedule in addition to when adjustments are pushed to git.
The next diagram reveals what the CI/CD structure for labeling appears to be like like intimately.

Recap automating knowledge labeling
We now have a working pipeline to mechanically create labels from unlabeled pictures of metallic tags utilizing SageMaker Floor Reality. The pictures are picked up from Amazon S3 and fed right into a SageMaker Floor Reality labeling job. After the photographs are labeled, we do a high quality test utilizing a label verification job. Lastly, the labels are saved in a function group in SageMaker Characteristic Retailer. If you wish to strive the working instance your self, take a look at the accompanying GitHub repository. Let’s take a look at the best way to automate mannequin constructing subsequent!
Automating mannequin constructing
Much like labeling, let’s have an in-depth take a look at our mannequin constructing pipeline. At a minimal, we have to orchestrate the next steps:
- Pull the most recent options from the function retailer
- Put together the information for mannequin coaching
- Practice the mannequin
- Consider mannequin efficiency
- Model and retailer the mannequin
- Approve the mannequin for deployment if efficiency is appropriate
The mannequin constructing course of is normally pushed by a knowledge scientist and is the result of a set of experiments accomplished utilizing notebooks or Python code. We are able to observe a easy three-step course of to transform an experiment to a completely automated MLOps pipeline:
- Convert present preprocessing, coaching, and analysis code to command line scripts.
- Create a SageMaker pipeline definition to orchestrate mannequin constructing. Use the scripts created in the first step as a part of the processing and coaching steps.
- Combine the pipeline into your CI/CD workflow.
This three-step course of is generic and can be utilized for any mannequin structure and ML framework of your selection. Let’s observe it and begin with Step 1 to create the next scripts:
- preprocess.py – This pulls labeled pictures from SageMaker Characteristic Retailer, splits the dataset, and transforms it into the required format for coaching our mannequin, in our case the enter format for YOLOv8
- train.py – This trains an Ultralytics YOLOv8 object detection model utilizing PyTorch to detect scratches on pictures of metallic tags
Orchestrating mannequin constructing
In Step 2, we bundle these scripts up into coaching and processing jobs and outline the ultimate SageMaker pipeline, which appears to be like like the next determine.

It consists of the next steps:
- A ProcessingStep to load the most recent options from SageMaker Characteristic Retailer; cut up the dataset into coaching, validation, and check units; and retailer the datasets as tarballs for coaching.
- A TrainingStep to coach the mannequin utilizing the coaching, validation, and check datasets and export the imply Common Precision (mAP) metric for the mannequin.
- A ConditionStep to guage if the mAP metric worth of the educated mannequin is above a configured threshold. In that case, a RegisterModel step is run that registers the educated mannequin within the SageMaker Mannequin Registry.
If you’re within the detailed pipeline code, take a look at the pipeline definition in our pattern repository.
Coaching: Infrastructure deployment and integration into CI/CD
Now it’s time for Step 3: integration into the CI/CD workflow. Our CI/CD pipeline follows the identical sample illustrated within the labeling part earlier than. We use the AWS CDK to deploy the required pipelines from CodePipeline. The one distinction is that we use Amazon SageMaker Pipelines as a substitute of Step Features. The SageMaker pipeline definition is constructed and triggered as a part of a CodeBuild motion in CodePipeline.

Conclusion
We now have a completely automated labeling and mannequin coaching workflow utilizing SageMaker. We began by creating command line scripts from the experiment code. Then we used SageMaker Pipelines to orchestrate every of the mannequin coaching workflow steps. The command line scripts have been built-in as a part of the coaching and processing steps. On the finish of the pipeline, the educated mannequin is versioned and registered in SageMaker Mannequin Registry.
Try Part 3 of this collection, the place we are going to take a better take a look at the ultimate step of our MLOps workflow. We are going to create the pipeline that compiles and deploys the mannequin to an edge machine utilizing AWS IoT Greengrass!
Concerning the authors
 Michael Roth is a Senior Options Architect at AWS supporting Manufacturing clients in Germany to resolve their enterprise challenges by AWS expertise. In addition to work and household he’s enthusiastic about sports activities automobiles and enjoys Italian espresso.
Michael Roth is a Senior Options Architect at AWS supporting Manufacturing clients in Germany to resolve their enterprise challenges by AWS expertise. In addition to work and household he’s enthusiastic about sports activities automobiles and enjoys Italian espresso.
 Jörg Wöhrle is a Options Architect at AWS, working with manufacturing clients in Germany. With a ardour for automation, Joerg has labored as a software program developer, DevOps engineer, and Web site Reliability Engineer in his pre-AWS life. Past cloud, he’s an formidable runner and enjoys high quality time along with his household. So if in case you have a DevOps problem or wish to go for a run: let him know.
Jörg Wöhrle is a Options Architect at AWS, working with manufacturing clients in Germany. With a ardour for automation, Joerg has labored as a software program developer, DevOps engineer, and Web site Reliability Engineer in his pre-AWS life. Past cloud, he’s an formidable runner and enjoys high quality time along with his household. So if in case you have a DevOps problem or wish to go for a run: let him know.
 Johannes Langer is a Senior Options Architect at AWS, working with enterprise clients in Germany. Johannes is captivated with making use of machine studying to resolve actual enterprise issues. In his private life, Johannes enjoys engaged on house enchancment initiatives and spending time open air along with his household.
Johannes Langer is a Senior Options Architect at AWS, working with enterprise clients in Germany. Johannes is captivated with making use of machine studying to resolve actual enterprise issues. In his private life, Johannes enjoys engaged on house enchancment initiatives and spending time open air along with his household.



