Construct an end-to-end MLOps pipeline for visible high quality inspection on the edge – Half 1
A profitable deployment of a machine studying (ML) mannequin in a manufacturing setting closely depends on an end-to-end ML pipeline. Though growing such a pipeline will be difficult, it turns into much more complicated when coping with an edge ML use case. Machine studying on the edge is an idea that brings the aptitude of working ML fashions regionally to edge units. With a purpose to deploy, monitor, and preserve these fashions on the edge, a sturdy MLOps pipeline is required. An MLOps pipeline permits to automate the total ML lifecycle from information labeling to mannequin coaching and deployment.
Implementing an MLOps pipeline on the edge introduces extra complexities that make the automation, integration, and upkeep processes tougher because of the elevated operational overhead concerned. Nevertheless, utilizing purpose-built providers like Amazon SageMaker and AWS IoT Greengrass permits you to considerably cut back this effort. On this collection, we stroll you thru the method of architecting and constructing an built-in end-to-end MLOps pipeline for a pc imaginative and prescient use case on the edge utilizing SageMaker, AWS IoT Greengrass, and the AWS Cloud Development Kit (AWS CDK).
This put up focuses on designing the general MLOps pipeline structure; Part 2 and Part 3 of this collection concentrate on the implementation of the person parts. Now we have supplied a pattern implementation within the accompanying GitHub repository so that you can attempt your self. In the event you’re simply getting began with MLOps on the edge on AWS, discuss with MLOps at the edge with Amazon SageMaker Edge Manager and AWS IoT Greengrass for an outline and reference structure.
Use case: Inspecting the standard of steel tags
As an ML engineer, it’s essential to grasp the enterprise case you’re engaged on. So earlier than we dive into the MLOps pipeline structure, let’s take a look at the pattern use case for this put up. Think about a manufacturing line of a producer that engraves steel tags to create custom-made baggage tags. The standard assurance course of is expensive as a result of the uncooked steel tags have to be inspected manually for defects like scratches. To make this course of extra environment friendly, we use ML to detect defective tags early within the course of. This helps keep away from expensive defects at later levels of the manufacturing course of. The mannequin ought to determine potential defects like scratches in near-real time and mark them. In manufacturing store flooring environments, you typically need to take care of no connectivity or constrained bandwidth and elevated latency. Due to this fact, we wish to implement an on-edge ML resolution for visible high quality inspection that may run inference regionally on the store flooring and reduce the necessities with regard to connectivity. To maintain our instance easy, we prepare a mannequin that marks detected scratches with bounding packing containers. The next picture is an instance of a tag from our dataset with three scratches marked.

Defining the pipeline structure
Now we have now gained readability into our use case and the precise ML drawback we intention to deal with, which revolves round object detection on the edge. Now it’s time to draft an structure for our MLOps pipeline. At this stage, we aren’t applied sciences or particular providers but, however somewhat the high-level parts of our pipeline. With a purpose to shortly retrain and deploy, we have to automate the entire end-to-end course of: from information labeling, to coaching, to inference. Nevertheless, there are a couple of challenges that make organising a pipeline for an edge case significantly exhausting:
- Constructing totally different components of this course of requires totally different talent units. As an example, information labeling and coaching has a powerful information science focus, edge deployment requires an Web of Issues (IoT) specialist, and automating the entire course of is normally carried out by somebody with a DevOps talent set.
- Relying in your group, this complete course of would possibly even be applied by a number of groups. For our use case, we’re working underneath the idea that separate groups are accountable for labeling, coaching, and deployment.
- Extra roles and talent units imply totally different necessities in relation to tooling and processes. As an example, information scientists would possibly wish to monitor and work with their acquainted pocket book setting. MLOps engineers wish to work utilizing infrastructure as code (IaC) instruments and is perhaps extra conversant in the AWS Management Console.
What does this imply for our pipeline structure?
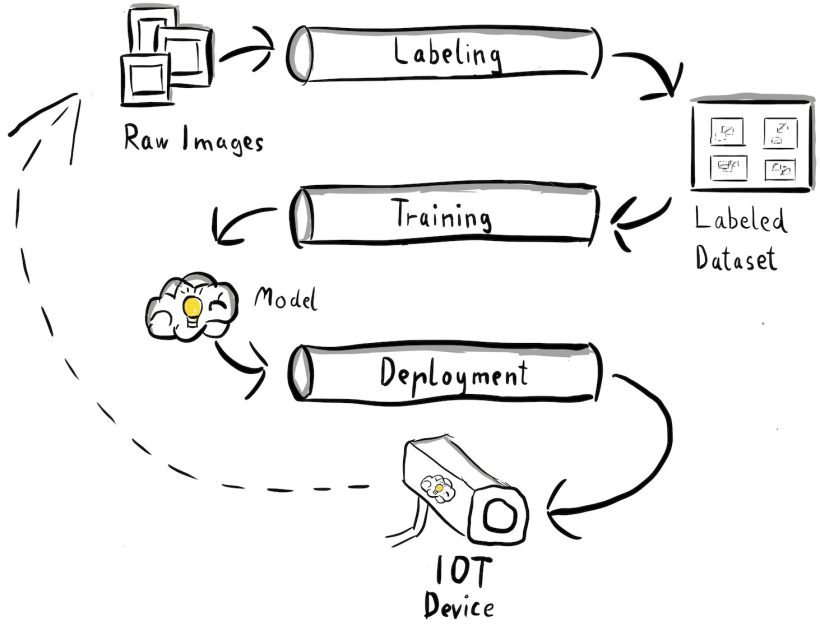
Firstly, it’s essential to obviously outline the foremost parts of the end-to-end system that permits totally different groups to work independently. Secondly, well-defined interfaces between groups should be outlined to reinforce collaboration effectivity. These interfaces assist reduce disruptions between groups, enabling them to change their inside processes as wanted so long as they adhere to the outlined interfaces. The next diagram illustrates what this might appear like for our pc imaginative and prescient pipeline.
Let’s look at the general structure of the MLOps pipeline intimately:
- The method begins with a group of uncooked photos of steel tags, that are captured utilizing an edge digicam system within the manufacturing setting to type an preliminary coaching dataset.
- The subsequent step includes labeling these photos and marking defects utilizing bounding packing containers. It’s important to model the labeled dataset, making certain traceability and accountability for the utilized coaching information.
- After we’ve got a labeled dataset, we will proceed with coaching, fine-tuning, evaluating, and versioning our mannequin.
- Once we’re pleased with our mannequin efficiency, we will deploy the mannequin to an edge system and run reside inferences on the edge.
- Whereas the mannequin operates in manufacturing, the sting digicam system generates helpful picture information containing beforehand unseen defects and edge circumstances. We will use this information to additional improve our mannequin’s efficiency. To perform this, we save photos for which the mannequin predicts with low confidence or makes misguided predictions. These photos are then added again to our uncooked dataset, initiating the whole course of once more.
It’s essential to notice that the uncooked picture information, labeled dataset, and skilled mannequin function well-defined interfaces between the distinct pipelines. MLOps engineers and information scientists have the pliability to decide on the applied sciences inside their pipelines so long as they constantly produce these artifacts. Most importantly, we’ve got established a closed suggestions loop. Defective or low-confidence predictions made in manufacturing can be utilized to usually increase our dataset and robotically retrain and improve the mannequin.
Goal structure
Now that the high-level structure is established, it’s time to go one degree deeper and take a look at how we may construct this with AWS providers. Notice that the structure proven on this put up assumes you wish to take full management of the entire information science course of. Nevertheless, if you happen to’re simply getting began with high quality inspection on the edge, we advocate Amazon Lookout for Vision. It offers a technique to prepare your personal high quality inspection mannequin with out having to construct, preserve, or perceive ML code. For extra info, discuss with Amazon Lookout for Vision now supports visual inspection of product defects at the edge.
Nevertheless, if you wish to take full management, the next diagram exhibits what an structure may appear like.
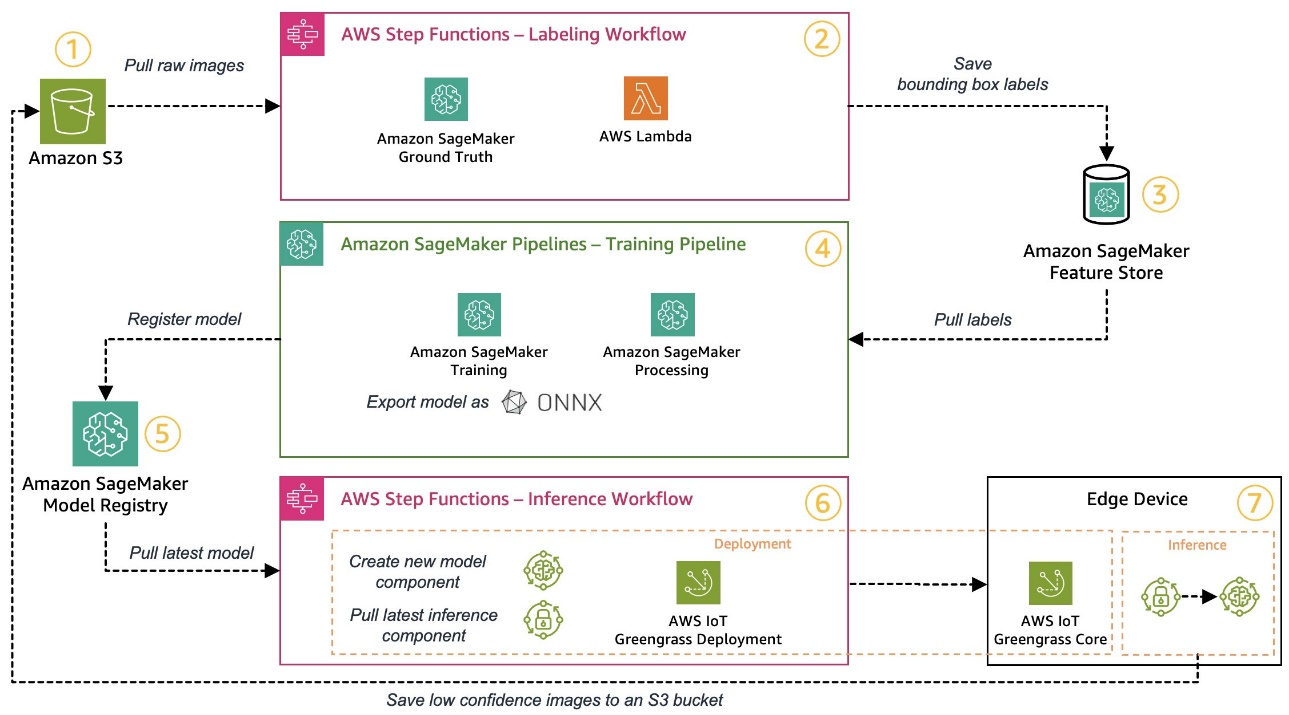
Much like earlier than, let’s stroll by way of the workflow step-by-step and determine which AWS providers go well with our necessities:
- Amazon Simple Storage Service (Amazon S3) is used to retailer uncooked picture information as a result of it offers us with a low-cost storage resolution.
- The labeling workflow is orchestrated utilizing AWS Step Functions, a serverless workflow engine that makes it simple to orchestrate the steps of the labeling workflow. As a part of this workflow, we use Amazon SageMaker Ground Truth to completely automate the labeling utilizing labeling jobs and managed human workforces. AWS Lambda is used to organize the information, begin the labeling jobs, and retailer the labels in Amazon SageMaker Feature Store.
- SageMaker Characteristic Retailer shops the labels. It permits us to centrally handle and share our options and offers us with built-in information versioning capabilities, which makes our pipeline extra sturdy.
- We orchestrate the mannequin constructing and coaching pipeline utilizing Amazon SageMaker Pipelines. It integrates with the opposite SageMaker options required through built-in steps. SageMaker Training jobs are used to automate the mannequin coaching, and SageMaker Processing jobs are used to organize the information and consider mannequin efficiency. On this instance, we’re utilizing the Ultralytics YOLOv8 Python package deal and mannequin structure to coach and export an object detection mannequin to the ONNX ML mannequin format for portability.
- If the efficiency is appropriate, the skilled mannequin is registered in Amazon SageMaker Model Registry with an incremental model quantity connected. It acts as our interface between the mannequin coaching and edge deployment steps. We additionally handle the approval state of fashions right here. Much like the opposite providers used, it’s totally managed, so we don’t need to maintain working our personal infrastructure.
- The sting deployment workflow is automated utilizing Step Features, just like the labeling workflow. We will use the API integrations of Step Features to simply name the assorted required AWS service APIs like AWS IoT Greengrass to create new mannequin parts and afterwards deploy the parts to the sting system.
- AWS IoT Greengrass is used as the sting system runtime setting. It manages the deployment lifecycle for our mannequin and inference parts on the edge. It permits us to simply deploy new variations of our mannequin and inference parts utilizing easy API calls. As well as, ML fashions on the edge normally don’t run in isolation; we will use the assorted AWS and community supplied parts of AWS IoT Greengrass to hook up with different providers.
The structure outlined resembles our high-level structure proven earlier than. Amazon S3, SageMaker Characteristic Retailer, and SageMaker Mannequin Registry act because the interfaces between the totally different pipelines. To attenuate the hassle to run and function the answer, we use managed and serverless providers wherever potential.
Merging into a sturdy CI/CD system
The information labeling, mannequin coaching, and edge deployment steps are core to our resolution. As such, any change associated to the underlying code or information in any of these components ought to set off a brand new run of the entire orchestration course of. To realize this, we have to combine this pipeline right into a CI/CD system that permits us to robotically deploy code and infrastructure adjustments from a versioned code repository into manufacturing. Much like the earlier structure, workforce autonomy is a crucial side right here. The next diagram exhibits what this might appear like utilizing AWS providers.
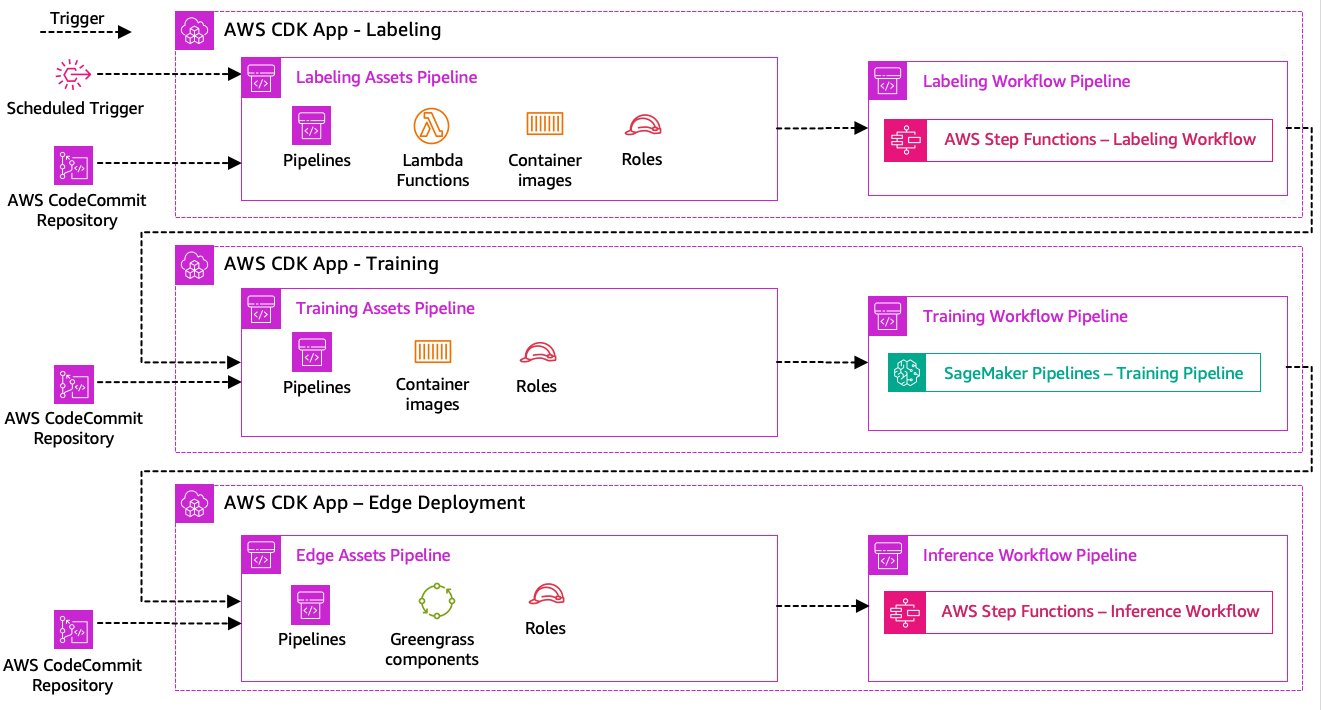
Let’s stroll by way of the CI/CD structure:
- AWS CodeCommit acts as our Git repository. For the sake of simplicity, in our supplied pattern, we separated the distinct components (labeling, mannequin coaching, edge deployment) through subfolders in a single git repository. In a real-world situation, every workforce would possibly use totally different repositories for every half.
- Infrastructure deployment is automated utilizing the AWS CDK and every half (labeling, coaching, and edge) will get its personal AWS CDK app to permit impartial deployments.
- The AWS CDK pipeline characteristic makes use of AWS CodePipeline to automate the infrastructure and code deployments.
- The AWS CDK deploys two code pipelines for every step: an asset pipeline and a workflow pipeline. We separated the workflow from the asset deployment to permit us to start out the workflows individually in case there aren’t any asset adjustments (for instance, when there are new photos accessible for coaching).
- The asset code pipeline deploys all infrastructure required for the workflow to run efficiently, corresponding to AWS Identity and Access Management (IAM) roles, Lambda features, and container photos used throughout coaching.
- The workflow code pipeline runs the precise labeling, coaching, or edge deployment workflow.
- Asset pipelines are robotically triggered on commit in addition to when a earlier workflow pipeline is full.
- The entire course of is triggered on a schedule utilizing an Amazon EventBridge rule for normal retraining.
With the CI/CD integration, the entire end-to-end chain is now totally automated. The pipeline is triggered every time code adjustments in our git repository in addition to on a schedule to accommodate for information adjustments.
Pondering forward
The answer structure described represents the essential parts to construct an end-to-end MLOps pipeline on the edge. Nevertheless, relying in your necessities, you would possibly take into consideration including extra performance. The next are some examples:
Conclusion
On this put up, we outlined our structure for constructing an end-to-end MLOps pipeline for visible high quality inspection on the edge utilizing AWS providers. This structure streamlines the whole course of, encompassing information labeling, mannequin improvement, and edge deployment, enabling us to swiftly and reliably prepare and implement new variations of the mannequin. With serverless and managed providers, we will direct our focus in direction of delivering enterprise worth somewhat than managing infrastructure.
In Part 2 of this collection, we’ll delve one degree deeper and take a look at the implementation of this structure in additional element, particularly labeling and mannequin constructing. If you wish to soar straight to the code, you’ll be able to try the accompanying GitHub repo.
Concerning the authors
 Michael Roth is a Senior Options Architect at AWS supporting Manufacturing prospects in Germany to resolve their enterprise challenges by way of AWS know-how. Apart from work and household he’s all for sports activities automobiles and enjoys Italian espresso.
Michael Roth is a Senior Options Architect at AWS supporting Manufacturing prospects in Germany to resolve their enterprise challenges by way of AWS know-how. Apart from work and household he’s all for sports activities automobiles and enjoys Italian espresso.
 Jörg Wöhrle is a Options Architect at AWS, working with manufacturing prospects in Germany. With a ardour for automation, Joerg has labored as a software program developer, DevOps engineer, and Website Reliability Engineer in his pre-AWS life. Past cloud, he’s an formidable runner and enjoys high quality time together with his household. So in case you have a DevOps problem or wish to go for a run: let him know.
Jörg Wöhrle is a Options Architect at AWS, working with manufacturing prospects in Germany. With a ardour for automation, Joerg has labored as a software program developer, DevOps engineer, and Website Reliability Engineer in his pre-AWS life. Past cloud, he’s an formidable runner and enjoys high quality time together with his household. So in case you have a DevOps problem or wish to go for a run: let him know.
 Johannes Langer is a Senior Options Architect at AWS, working with enterprise prospects in Germany. Johannes is keen about making use of machine studying to resolve actual enterprise issues. In his private life, Johannes enjoys engaged on residence enchancment initiatives and spending time outside together with his household.
Johannes Langer is a Senior Options Architect at AWS, working with enterprise prospects in Germany. Johannes is keen about making use of machine studying to resolve actual enterprise issues. In his private life, Johannes enjoys engaged on residence enchancment initiatives and spending time outside together with his household.





