Sturdy time collection forecasting with MLOps on Amazon SageMaker
On the planet of data-driven decision-making, time series forecasting is vital in enabling companies to make use of historic information patterns to anticipate future outcomes. Whether or not you might be working in asset danger administration, buying and selling, climate prediction, vitality demand forecasting, very important signal monitoring, or visitors evaluation, the flexibility to forecast precisely is essential for achievement.
In these purposes, time collection information can have heavy-tailed distributions, the place the tails signify excessive values. Correct forecasting in these areas is essential in figuring out how seemingly an excessive occasion is and whether or not to lift an alarm. Nonetheless, these outliers considerably impression the estimation of the bottom distribution, making strong forecasting difficult. Monetary establishments depend on strong fashions to foretell outliers equivalent to market crashes. In vitality, climate, and healthcare sectors, correct forecasts of rare however high-impact occasions equivalent to pure disasters and pandemics allow efficient planning and useful resource allocation. Neglecting tail habits can result in losses, missed alternatives, and compromised security. Prioritizing accuracy on the tails helps result in dependable and actionable forecasts. On this submit, we prepare a strong time collection forecasting mannequin able to capturing such excessive occasions utilizing Amazon SageMaker.
To successfully prepare this mannequin, we set up an MLOps infrastructure to streamline the mannequin growth course of by automating information preprocessing, characteristic engineering, hyperparameter tuning, and mannequin choice. This automation reduces human error, improves reproducibility, and accelerates the mannequin growth cycle. With a coaching pipeline, companies can effectively incorporate new information and adapt their fashions to evolving situations, which helps be sure that forecasts stay dependable and updated.
After the time collection forecasting mannequin is skilled, deploying it inside an endpoint grants real-time prediction capabilities. This empowers you to make well-informed and responsive choices primarily based on the latest information. Moreover, deploying the mannequin in an endpoint permits scalability, as a result of a number of customers and purposes can entry and make the most of the mannequin concurrently. By following these steps, companies can harness the facility of strong time collection forecasting to make knowledgeable choices and keep forward in a quickly altering surroundings.
Overview of answer
This answer showcases the coaching of a time collection forecasting mannequin, particularly designed to deal with outliers and variability in information utilizing a Temporal Convolutional Network (TCN) with a Spliced Binned Pareto (SBP) distribution. For extra details about a multimodal model of this answer, discuss with The science behind NFL Next Gen Stats’ new passing metric. To additional illustrate the effectiveness of the SBP distribution, we evaluate it with the identical TCN mannequin however utilizing a Gaussian distribution as an alternative.
This course of considerably advantages from the MLOps features of SageMaker, which streamline the information science workflow by harnessing the highly effective cloud infrastructure of AWS. In our answer, we use Amazon SageMaker Automatic Model Tuning for hyperparameter search, Amazon SageMaker Experiments for managing experiments, Amazon SageMaker Model Registry to handle mannequin variations, and Amazon SageMaker Pipelines to orchestrate the method. We then deploy our mannequin to a SageMaker endpoint to acquire real-time predictions.
The next diagram illustrates the structure of the coaching pipeline.

The next diagram illustrates the inference pipeline.

You’ll find the entire code within the GitHub repo. To implement the answer, run the cells in SBP_main.ipynb.
Click here to open the AWS console and follow along.
SageMaker pipeline
SageMaker Pipelines presents a user-friendly Python SDK to create built-in machine studying (ML) workflows. These workflows, represented as Directed Acyclic Graphs (DAGs), include steps with numerous varieties and dependencies. With SageMaker Pipelines, you’ll be able to streamline the end-to-end course of of coaching and evaluating fashions, enhancing effectivity and reproducibility in your ML workflows.
The coaching pipeline begins with producing an artificial dataset that’s break up into coaching, validation, and check units. The coaching set is used to coach two TCN fashions, one using Spliced Binned-Pareto distribution and the opposite using Gaussian distribution. Each fashions undergo hyperparameter tuning utilizing the validation set to optimize every mannequin. Afterward, an analysis towards the check set is performed to find out the mannequin with the bottom root imply squared error (RMSE). The mannequin with one of the best accuracy metric is uploaded to the mannequin registry.
The next diagram illustrates the pipeline steps.
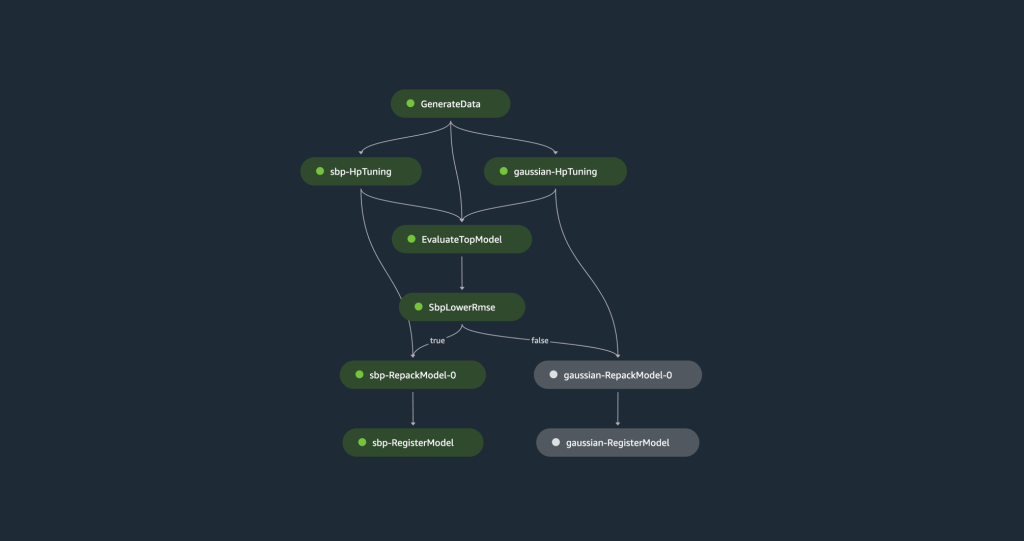
Let’s focus on the steps in additional element.
Knowledge technology
Step one in our pipeline generates an artificial dataset, which is characterised by a sinusoidal waveform and uneven heavy-tailed noise. The information was created utilizing quite a few parameters, equivalent to levels of freedom, a noise multiplier, and a scale parameter. These parts affect the form of the information distribution, modulate the random variability in our information, and alter the unfold of our information distribution, respectively.
This information processing job is completed utilizing a PyTorchProcessor, which runs PyTorch code (generate_data.py) inside a container managed by SageMaker. Knowledge and different related artifacts for debugging are positioned within the default Amazon Simple Storage Service (Amazon S3) bucket related to the SageMaker account. Logs for every step within the pipeline may be present in Amazon CloudWatch.
The next determine is a pattern of the information generated by the pipeline.
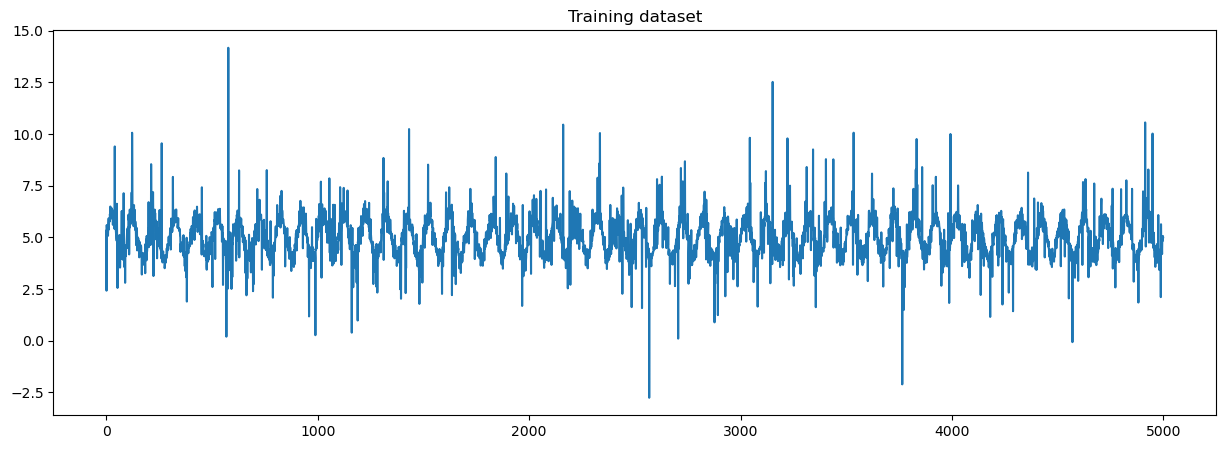
You’ll be able to exchange the enter with all kinds of time collection information, equivalent to symmetric, uneven, light-tailed, heavy-tailed, or multimodal distribution. The mannequin’s robustness permits it to be relevant to a broad vary of time collection issues, offered adequate observations can be found.
Mannequin coaching
After information technology, we prepare two TCNs: one utilizing SBP distribution and different utilizing Gaussian distribution. SBP distribution employs a discrete binned distribution as its predictive base, the place the true axis is split into discrete bins, and the mannequin predicts the chance of an commentary falling inside every bin. This technique permits the seize of asymmetries and a number of modes as a result of the likelihood of every bin is impartial. An instance of the binned distribution is proven within the following determine.
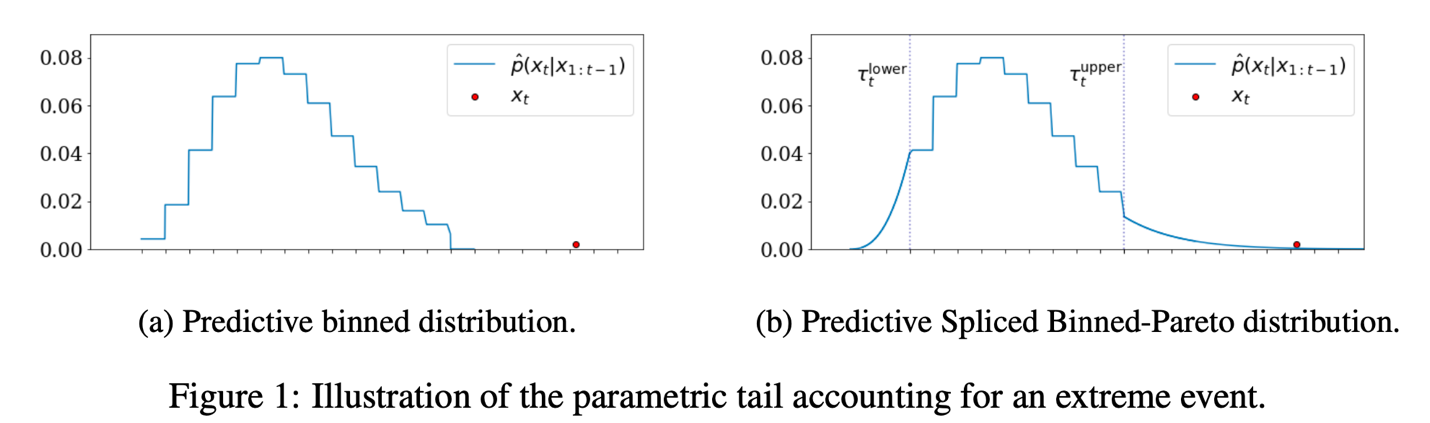
The predictive binned distribution on the left is strong to excessive occasions as a result of the log-likelihood just isn’t depending on the space between the expected imply and noticed level, differing from parametric distributions like Gaussian or Scholar’s t. Due to this fact, the intense occasion represented by the pink dot won’t bias the realized imply of the distribution. Nonetheless, the intense occasion can have zero likelihood. To seize excessive occasions, we type an SBP distribution by defining the decrease tail on the fifth quantile and the higher tail on the ninety fifth quantile, changing each tails with weighted Generalized Pareto Distributions (GPD), which may quantify the likeliness of the occasion. The TCN will output the parameters for the binned distribution base and GPD tails.
Hyperparameter search
For optimum output, we use automatic model tuning to seek out one of the best model of a mannequin by way of hyperparameter tuning. This step is built-in into SageMaker Pipelines and permits for the parallel run of a number of coaching jobs, using numerous strategies and predefined hyperparameter ranges. The result’s the choice of one of the best mannequin primarily based on the required mannequin metric, which is RMSE. In our pipeline, we particularly tune the educational charge and variety of coaching epochs to optimize our mannequin’s efficiency. With the hyperparameter tuning functionality in SageMaker, we enhance the chance that our mannequin achieves optimum accuracy and generalization for the given process.
Because of the artificial nature of our information, we’re protecting Context Size and Lead Time as static parameters. Context Size refers back to the variety of historic time steps inputted into the mannequin, and Lead Time represents the variety of time steps in our forecast horizon. For the pattern code, we’re solely tuning Studying Price and the variety of epochs to save lots of on time and price.
SBP-specific parameters are saved fixed primarily based on intensive testing by the authors on the unique paper throughout totally different datasets:
- Variety of Bins (100) – This parameter determines the variety of bins used to mannequin the bottom of the distribution. It’s saved at 100, which has confirmed to be best throughout a number of industries.
- Percentile Tail (0.05) – This denotes the scale of the generalized Pareto distributions on the tail. Just like the earlier parameter, this has been exhaustively examined and located to be best.
Experiments
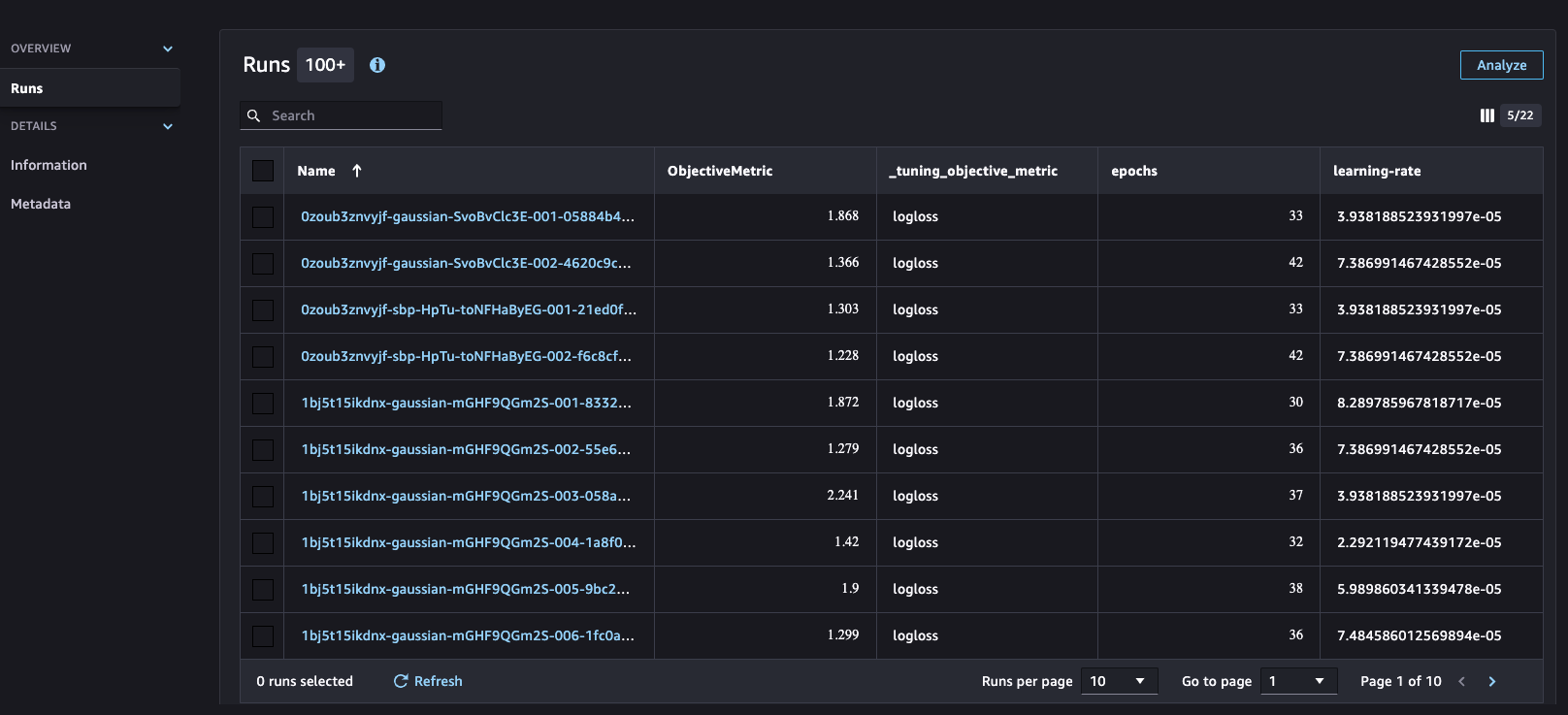
The hyperparameter course of is built-in with SageMaker Experiments, which helps arrange, analyze, and evaluate iterative ML experiments, offering insights and facilitating monitoring of the best-performing fashions. Machine studying is an iterative course of involving quite a few experiments encompassing information variations, algorithm selections, and hyperparameter tuning. These experiments serve to incrementally refine mannequin accuracy. Nonetheless, the big variety of coaching runs and mannequin iterations could make it difficult to establish the best-performing fashions and make significant comparisons between present and previous experiments. SageMaker Experiments addresses this by mechanically monitoring our hyperparameter tuning jobs and permitting us to realize additional particulars and perception into the tuning course of, as proven within the following screenshot.
Mannequin analysis
The fashions endure coaching and hyperparameter tuning, and are subsequently evaluated by way of the evaluate.py script. This step makes use of the check set, distinct from the hyperparameter tuning stage, to gauge the mannequin’s real-world accuracy. RMSE is used to evaluate the accuracy of the predictions.
For distribution comparability, we make use of a probability-probability (P-P) plot, which assesses the match between the precise vs. predicted distributions. The closeness of the factors to the diagonal signifies an ideal match. Our comparisons between SBP’s and Gaussian’s predicted distributions towards the precise distribution present that SBP’s predictions align extra carefully with the precise information.
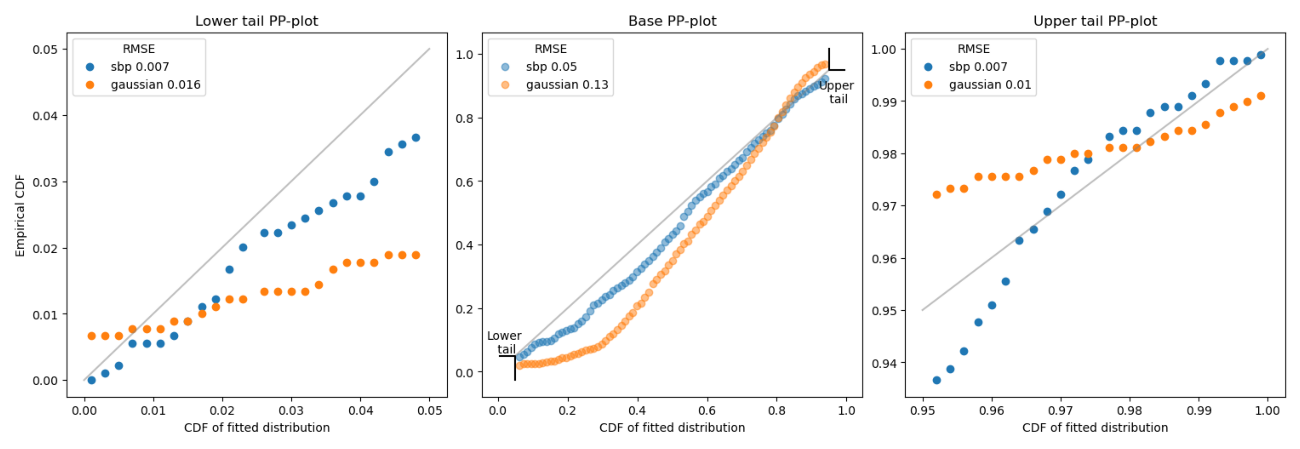
As we are able to observe, SBP has decrease RMSE on the bottom, decrease tail, and higher tail. The SBP distribution improved the accuracy of the Gaussian distribution by 61% on the bottom, 56% on the decrease tail, and 30% on the higher tail. General, the SBP distribution has considerably higher outcomes.
Mannequin choice
We use a situation step in SageMaker Pipelines to investigate mannequin analysis reviews, choosing the mannequin with the bottom RMSE for improved distribution accuracy. The chosen mannequin is transformed right into a SageMaker mannequin object, readying it for deployment. This includes making a mannequin package deal with essential parameters and packaging it right into a ModelStep.
Mannequin registry
The chosen mannequin is then uploaded to SageMaker Model Registry, which performs a vital function in managing fashions prepared for manufacturing. It shops fashions, organizes mannequin variations, captures important metadata and artifacts equivalent to container photographs, and governs the approval standing of every mannequin. By utilizing the registry, we are able to effectively deploy fashions to accessible SageMaker environments and set up a basis for steady integration and steady deployment (CI/CD) pipelines.
Inference
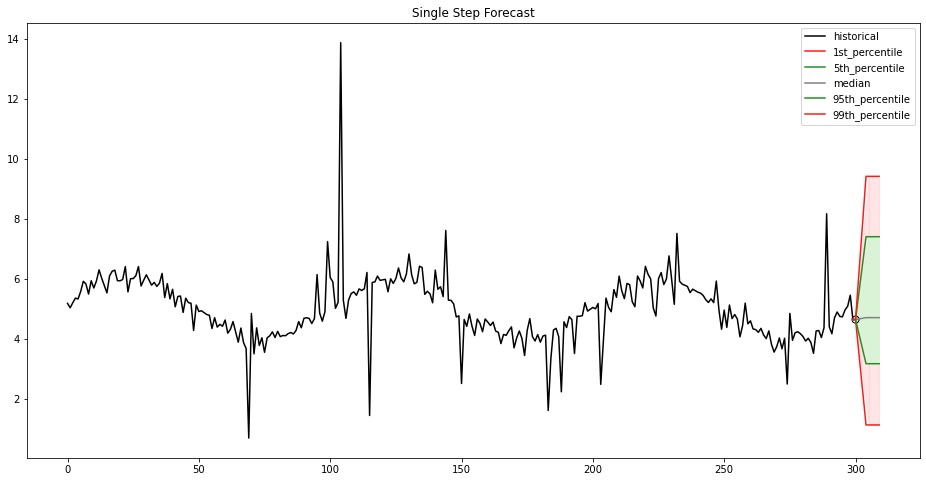
Upon completion of our coaching pipeline, our mannequin is then deployed utilizing SageMaker hosting services, which permits the creation of an inference endpoint for real-time predictions. This endpoint permits seamless integration with purposes and programs, offering on-demand entry to the mannequin’s predictive capabilities by way of a safe HTTPS interface. Actual-time predictions can be utilized in eventualities equivalent to inventory worth and vitality demand forecast. Our endpoint offers a single-step forecast for the offered time collection information, offered as percentiles and the median, as proven within the following determine and desk.
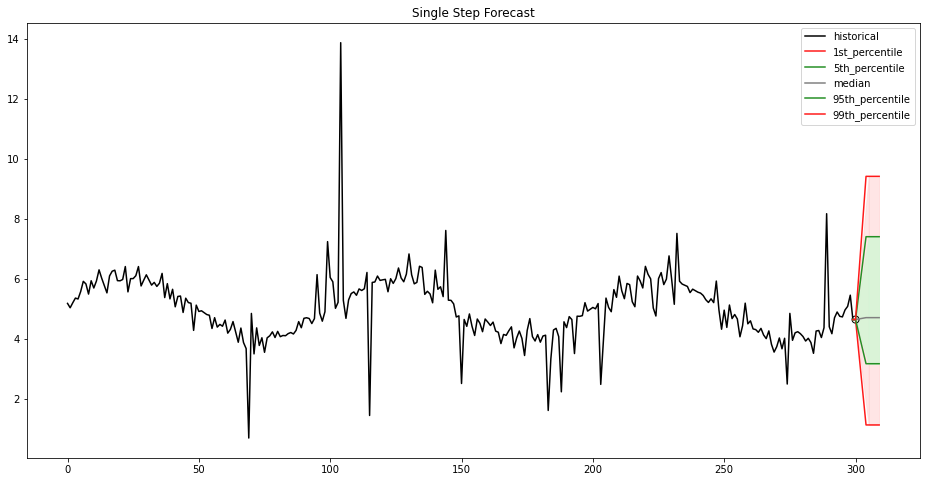
| 1st percentile | 5th percentile | Median | 95th percentile | 99th percentile |
| 1.12 | 3.16 | 4.70 | 7.40 | 9.41 |
Clear up
After you run this answer, be sure you clear up any pointless AWS assets to keep away from surprising prices. You’ll be able to clear up these assets utilizing the SageMaker Python SDK, which may be discovered on the finish of the pocket book. By deleting these assets, you forestall additional prices for assets you might be not utilizing.
Conclusion
Having an correct forecast can extremely impression a enterprise’s future planning and may also present options to quite a lot of issues in several industries. Our exploration of strong time collection forecasting with MLOps on SageMaker has demonstrated a way to acquire an correct forecast and the effectivity of a streamlined coaching pipeline.
Our mannequin, powered by a Temporal Convolutional Community with Spliced Binned Pareto distribution, has proven accuracy and flexibility to outliers by enhancing the RMSE by 61% on the bottom, 56% on the decrease tail, and 30% on the higher tail over the identical TCN with Gaussian distribution. These figures make it a dependable answer for real-world forecasting wants.
The pipeline demonstrates the worth of automating MLOps options. This could scale back guide human effort, allow reproducibility, and speed up mannequin deployment. SageMaker options equivalent to SageMaker Pipelines, computerized mannequin tuning, SageMaker Experiments, SageMaker Mannequin Registry, and endpoints make this potential.
Our answer employs a miniature TCN, optimizing only a few hyperparameters with a restricted variety of layers, that are adequate for successfully highlighting the mannequin’s efficiency. For extra advanced use instances, think about using PyTorch or different PyTorch-based libraries to assemble a extra personalized TCN that aligns along with your particular wants. Moreover, it could be useful to discover different SageMaker features to reinforce your pipeline’s performance additional. To completely automate the deployment course of, you should use the AWS Cloud Development Kit (AWS CDK) or AWS CloudFormation.
For extra data on time collection forecasting on AWS, discuss with the next:
Be at liberty to go away a remark with any ideas or questions!
Concerning the Authors
 Nick Biso is a Machine Studying Engineer at AWS Skilled Providers. He solves advanced organizational and technical challenges utilizing information science and engineering. As well as, he builds and deploys AI/ML fashions on the AWS Cloud. His ardour extends to his proclivity for journey and numerous cultural experiences.
Nick Biso is a Machine Studying Engineer at AWS Skilled Providers. He solves advanced organizational and technical challenges utilizing information science and engineering. As well as, he builds and deploys AI/ML fashions on the AWS Cloud. His ardour extends to his proclivity for journey and numerous cultural experiences.
 Alston Chan is a Software program Growth Engineer at Amazon Advertisements. He builds machine studying pipelines and advice programs for product suggestions on the Element Web page. Exterior of labor, he enjoys sport growth and mountaineering.
Alston Chan is a Software program Growth Engineer at Amazon Advertisements. He builds machine studying pipelines and advice programs for product suggestions on the Element Web page. Exterior of labor, he enjoys sport growth and mountaineering.
 Maria Masood makes a speciality of constructing information pipelines and information visualizations at AWS Commerce Platform. She has experience in Machine Studying, overlaying pure language processing, pc imaginative and prescient, and time-series evaluation. A sustainability fanatic at coronary heart, Maria enjoys gardening and taking part in along with her canine throughout her downtime.
Maria Masood makes a speciality of constructing information pipelines and information visualizations at AWS Commerce Platform. She has experience in Machine Studying, overlaying pure language processing, pc imaginative and prescient, and time-series evaluation. A sustainability fanatic at coronary heart, Maria enjoys gardening and taking part in along with her canine throughout her downtime.





