Outperforming bigger language fashions with much less coaching information and smaller mannequin sizes – Google Analysis Weblog

Giant language fashions (LLMs) have enabled a brand new data-efficient studying paradigm whereby they can be utilized to unravel unseen new duties through zero-shot or few-shot prompting. Nevertheless, LLMs are difficult to deploy for real-world purposes as a result of their sheer measurement. As an illustration, serving a single 175 billion LLM requires at the very least 350GB of GPU reminiscence utilizing specialized infrastructure, to not point out that right now’s state-of-the-art LLMs are composed of over 500 billion parameters. Such computational necessities are inaccessible for a lot of analysis groups, particularly for purposes that require low latency efficiency.
To avoid these deployment challenges, practitioners typically select to deploy smaller specialised fashions as an alternative. These smaller fashions are skilled utilizing one among two widespread paradigms: fine-tuning or distillation. High-quality-tuning updates a pre-trained smaller mannequin (e.g., BERT or T5) utilizing downstream manually-annotated information. Distillation trains the identical smaller fashions with labels generated by a bigger LLM. Sadly, to attain comparable efficiency to LLMs, fine-tuning strategies require human-generated labels, that are costly and tedious to acquire, whereas distillation requires giant quantities of unlabeled information, which can be laborious to gather.
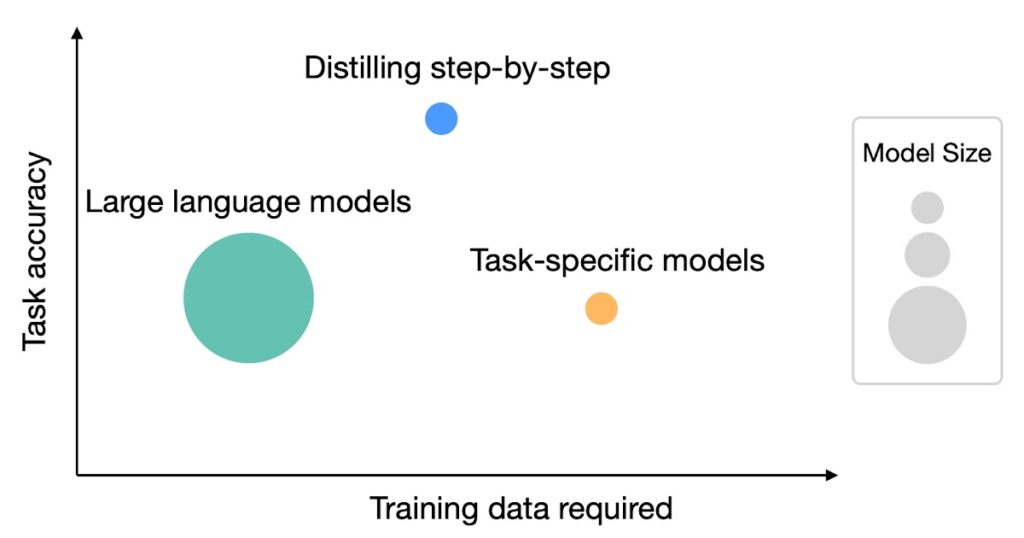
In “Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes”, offered at ACL2023, we got down to sort out this trade-off between mannequin measurement and coaching information assortment value. We introduce distilling step-by-step, a brand new easy mechanism that permits us to coach smaller task-specific fashions with a lot much less coaching information than required by customary fine-tuning or distillation approaches that outperform few-shot prompted LLMs’ efficiency. We show that the distilling step-by-step mechanism allows a 770M parameter T5 mannequin to outperform the few-shot prompted 540B PaLM mannequin utilizing solely 80% of examples in a benchmark dataset, which demonstrates a greater than 700x mannequin measurement discount with a lot much less coaching information required by customary approaches.
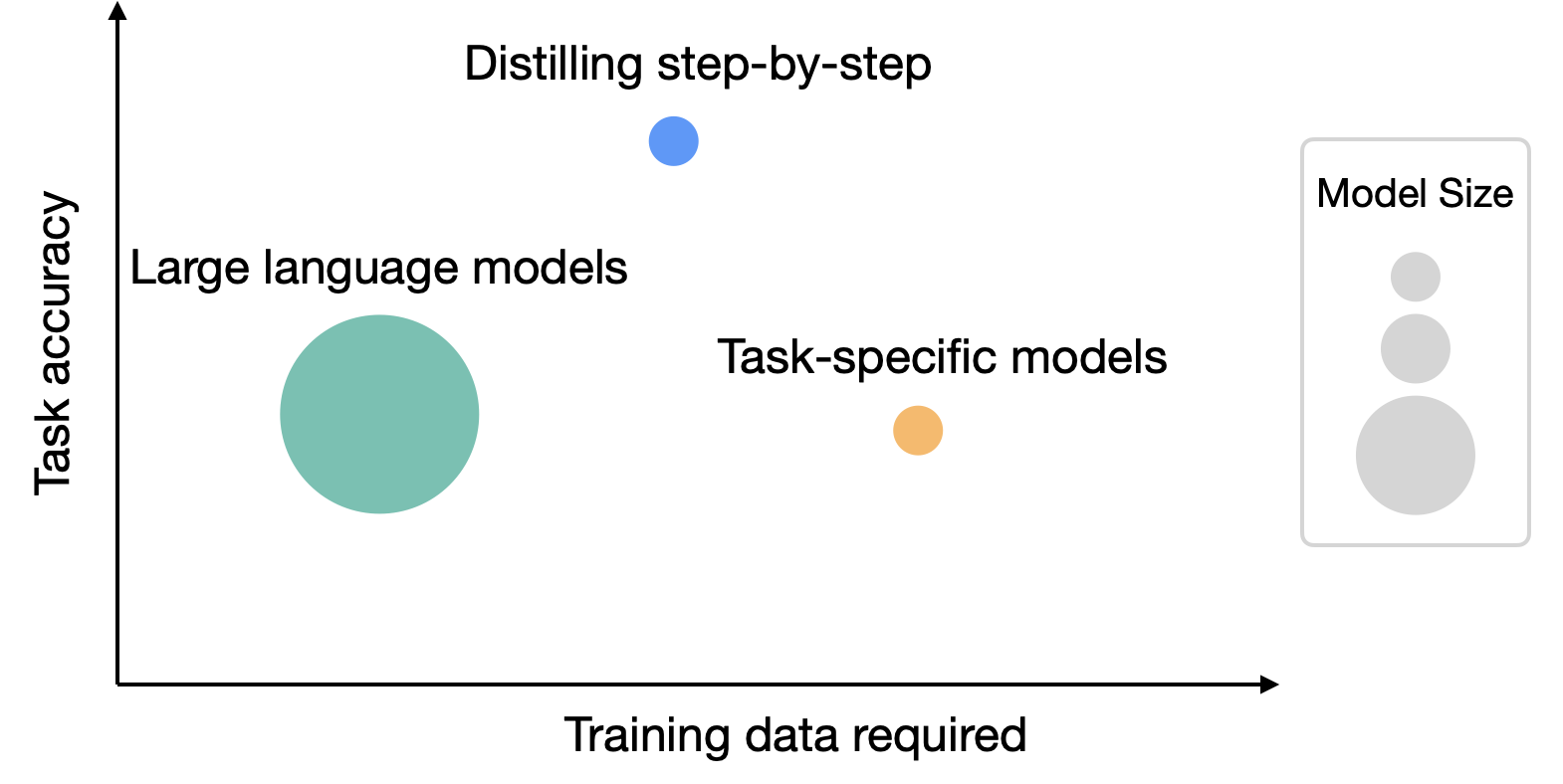 |
| Whereas LLMs supply robust zero and few-shot efficiency, they’re difficult to serve in observe. Then again, conventional methods of coaching small task-specific fashions require a considerable amount of coaching information. Distilling step-by-step offers a brand new paradigm that reduces each the deployed mannequin measurement in addition to the variety of information required for coaching. |
Distilling step-by-step
The important thing thought of distilling step-by-step is to extract informative pure language rationales (i.e., intermediate reasoning steps) from LLMs, which may in flip be used to coach small fashions in a extra data-efficient means. Particularly, pure language rationales clarify the connections between the enter questions and their corresponding outputs. For instance, when requested, “Jesse’s room is 11 ft lengthy and 15 ft broad. If she already has 16 sq. ft of carpet, how way more carpet does she must cowl the entire ground?”, an LLM may be prompted by the few-shot chain-of-thought (CoT) prompting method to supply intermediate rationales, comparable to, “Space = size * width. Jesse’s room has 11 * 15 sq. ft.” That higher explains the connection from the enter to the ultimate reply, “(11 * 15 ) – 16”. These rationales can include related job information, comparable to “Space = size * width”, that will initially require many information for small fashions to be taught. We make the most of these extracted rationales as extra, richer supervision to coach small fashions, along with the usual job labels.
 |
| Overview on distilling step-by-step: First, we make the most of CoT prompting to extract rationales from an LLM. We then use the generated rationales to coach small task-specific fashions inside a multi-task studying framework, the place we prepend job prefixes to the enter examples and practice the mannequin to output otherwise primarily based on the given job prefix. |
Distilling step-by-step consists of two important phases. Within the first stage, we leverage few-shot CoT prompting to extract rationales from LLMs. Particularly, given a job, we put together few-shot exemplars within the LLM enter immediate the place every instance consists of a triplet containing: (1) enter, (2) rationale, and (3) output. Given the immediate, an LLM is ready to mimic the triplet demonstration to generate the rationale for any new enter. As an illustration, in a commonsense question answering task, given the enter query “Sammy needed to go to the place the individuals are. The place would possibly he go? Reply Selections: (a) populated areas, (b) race monitor, (c) desert, (d) house, (e) roadblock”, distilling step-by-step offers the right reply to the query, “(a) populated areas”, paired with the rationale that gives higher connection from the query to the reply, “The reply should be a spot with lots of people. Of the above decisions, solely populated areas have lots of people.” By offering CoT examples paired with rationales within the immediate, the in-context learning ability permits LLMs to output corresponding rationales for future unseen inputs.
 |
| We use the few-shot CoT prompting, which incorporates each an instance rationale (highlighted in inexperienced) and a label (highlighted in blue), to elicit rationales from an LLM on new enter examples. The instance is from a commonsense query answering job. |
After the rationales are extracted, within the second stage, we incorporate the rationales in coaching small fashions by framing the coaching course of as a multi-task downside. Particularly, we practice the small mannequin with a novel rationale era job along with the usual label prediction task. The rationale era job allows the mannequin to be taught to generate the intermediate reasoning steps for the prediction, and guides the mannequin to higher predict the resultant label. We prepend task prefixes (i.e., [label] and [rationale] for label prediction and rationale era, respectively) to the enter examples for the mannequin to distinguish the 2 duties.
Experimental setup
Within the experiments, we contemplate a 540B PaLM mannequin because the LLM. For task-specific downstream fashions, we use T5 models. For CoT prompting, we use the original CoT prompts when obtainable and curate our personal examples for brand spanking new datasets. We conduct the experiments on 4 benchmark datasets throughout three completely different NLP duties: e-SNLI and ANLI for natural language inference; CQA for commonsense query answering; and SVAMP for arithmetic math word problems. We embrace two units of baseline strategies. For comparability to few-shot prompted LLMs, we evaluate to few-shot CoT prompting with a 540B PaLM mannequin. Within the paper, we additionally evaluate customary task-specific mannequin coaching to each standard fine-tuning and standard distillation. On this blogpost, we are going to give attention to the comparisons to straightforward fine-tuning for illustration functions.
Much less coaching information
In comparison with standard fine-tuning, the distilling step-by-step technique achieves higher efficiency utilizing a lot much less coaching information. As an illustration, on the e-SNLI dataset, we obtain higher efficiency than customary fine-tuning when utilizing solely 12.5% of the total dataset (proven within the higher left quadrant beneath). Equally, we obtain a dataset measurement discount of 75%, 25% and 20% on ANLI, CQA, and SVAMP.
 |
| Distilling step-by-step in comparison with customary fine-tuning utilizing 220M T5 fashions on various sizes of human-labeled datasets. On all datasets, distilling step-by-step is ready to outperform customary fine-tuning, skilled on the total dataset, through the use of a lot much less coaching examples. |
Smaller deployed mannequin measurement
In comparison with few-shot CoT prompted LLMs, distilling step-by-step achieves higher efficiency utilizing a lot smaller mannequin sizes. As an illustration, on the e-SNLI dataset, we obtain higher efficiency than 540B PaLM through the use of a 220M T5 mannequin. On ANLI, we obtain higher efficiency than 540B PaLM through the use of a 770M T5 mannequin, which is over 700X smaller. Be aware that on ANLI, the identical 770M T5 mannequin struggles to match PaLM’s efficiency utilizing customary fine-tuning.
 |
| We carry out distilling step-by-step and customary fine-tuning on various sizes of T5 fashions and evaluate their efficiency to LLM baselines, i.e., Few-shot CoT and PINTO Tuning. Distilling step-by-step is ready to outperform LLM baselines through the use of a lot smaller fashions, e.g., over 700× smaller fashions on ANLI. Commonplace fine-tuning fails to match LLM’s efficiency utilizing the identical mannequin measurement. |
Distilling step-by-step outperforms few-shot LLMs with smaller fashions utilizing much less information
Lastly, we discover the smallest mannequin sizes and the least quantity of information for distilling step-by-step to outperform PaLM’s few-shot efficiency. As an illustration, on ANLI, we surpass the efficiency of the 540B PaLM utilizing a 770M T5 mannequin. This smaller mannequin solely makes use of 80% of the total dataset. In the meantime, we observe that customary fine-tuning can’t meet up with PaLM’s efficiency even utilizing 100% of the total dataset. This implies that distilling step-by-step concurrently reduces the mannequin measurement in addition to the quantity of information required to outperform LLMs.
 |
| We present the minimal measurement of T5 fashions and the least quantity of human-labeled examples required for distilling step-by-step to outperform LLM’s few-shot CoT by a coarse-grained search. Distilling step-by-step is ready to outperform few-shot CoT utilizing not solely a lot smaller fashions, however it additionally achieves so with a lot much less coaching examples in comparison with customary fine-tuning. |
Conclusion
We suggest distilling step-by-step, a novel mechanism that extracts rationales from LLMs as informative supervision in coaching small, task-specific fashions. We present that distilling step-by-step reduces each the coaching dataset required to curate task-specific smaller fashions and the mannequin measurement required to attain, and even surpass, a few-shot prompted LLM’s efficiency. Total, distilling step-by-step presents a resource-efficient paradigm that tackles the trade-off between mannequin measurement and coaching information required.
Availability on Google Cloud Platform
Distilling step-by-step is on the market for personal preview on Vertex AI. In case you are taken with attempting it out, please contact vertex-llm-tuning-preview@google.com together with your Google Cloud Venture quantity and a abstract of your use case.
Acknowledgements
This analysis was carried out by Cheng-Yu Hsieh, Chun-Liang Li, Chih-Kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alexander Ratner, Ranjay Krishna, Chen-Yu Lee, and Tomas Pfister. Because of Xiang Zhang and Sergey Ioffe for his or her worthwhile suggestions.