Optimize generative AI workloads for environmental sustainability
The adoption of generative AI is quickly increasing, reaching an ever-growing variety of industries and customers worldwide. With the rising complexity and scale of generative AI fashions, it’s essential to work in direction of minimizing their environmental impression. This entails a continuous effort focused on energy reduction and efficiency by reaching the utmost profit from the sources provisioned and minimizing the full sources required.
So as to add to our guidance for optimizing deep learning workloads for sustainability on AWS, this submit supplies suggestions which can be particular to generative AI workloads. Specifically, we offer sensible greatest practices for various customization eventualities, together with coaching fashions from scratch, fine-tuning with further information utilizing full or parameter-efficient methods, Retrieval Augmented Technology (RAG), and immediate engineering. Though this submit primarily focuses on giant language fashions (LLM), we consider a lot of the suggestions may be prolonged to different basis fashions.
Generative AI downside framing
When framing your generative AI downside, think about the next:
- Align your use of generative AI together with your sustainability targets – When scoping your venture, make sure you take sustainability into consideration:
- What are the trade-offs between a generative AI answer and a much less resource-intensive conventional strategy?
- How can your generative AI venture assist sustainable innovation?
- Use power that has low carbon-intensity – When rules and authorized points enable, practice and deploy your mannequin on one of many 19 AWS Regions where the electricity consumed in 2022 was attributable to 100% renewable energy and Areas the place the grid has a broadcast carbon depth that’s decrease than different areas (or Areas). For extra element, check with How to select a Region for your workload based on sustainability goals. When choosing a Area, attempt to reduce information motion throughout networks: practice your fashions near your information and deploy your fashions near your customers.
- Use managed providers – Relying in your experience and particular use case, weigh the choices between choosing Amazon Bedrock, a serverless, absolutely managed service that gives entry to a various vary of basis fashions by way of an API, or deploying your fashions on a completely managed infrastructure through the use of Amazon SageMaker. Utilizing a managed service helps you operate more efficiently by shifting the accountability of sustaining excessive utilization and sustainability optimization of the deployed {hardware} to AWS.
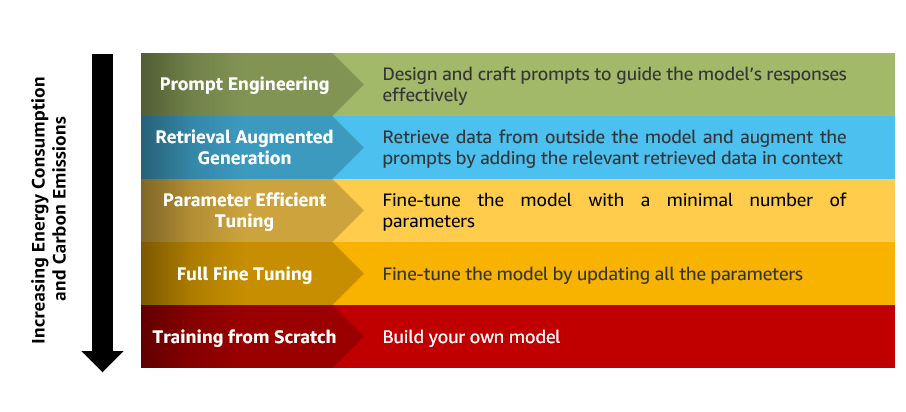
- Outline the appropriate customization technique – There are a number of methods to boost the capacities of your mannequin, starting from immediate engineering to full fine-tuning. Select essentially the most appropriate technique based mostly in your particular wants whereas additionally contemplating the variations in sources required for every. As an example, fine-tuning would possibly obtain larger accuracy than immediate engineering however consumes extra sources and power within the coaching section. Make trade-offs: by choosing a customization strategy that prioritizes acceptable efficiency over optimum efficiency, reductions within the sources utilized by your fashions may be achieved. The next determine summarizes the environmental impression of LLMs customization methods.

Mannequin customization
On this part, we share greatest practices for mannequin customization.
Base mannequin choice
Deciding on the suitable base mannequin is a essential step in customizing generative AI workloads and can assist cut back the necessity for intensive fine-tuning and related useful resource utilization. Take into account the next components:
- Consider capabilities and limitations – Use the playgrounds of Amazon SageMaker JumpStart or Amazon Bedrock to simply check the potential of LLMs and assess their core limitations.
- Cut back the necessity for personalization – Ensure to assemble data through the use of public sources similar to open LLMs leaderboards, holistic evaluation benchmarks, or model cards to match totally different LLMs and perceive the particular domains, duties, and languages for which they’ve been pre-trained on. Relying in your use case, think about domain-specific or multilingual fashions to cut back the necessity for extra customization.
- Begin with a small mannequin measurement and small context window – Giant mannequin sizes and context home windows (the variety of tokens that may slot in a single immediate) can supply extra efficiency and capabilities, however in addition they require extra power and sources for inference. Take into account out there variations of fashions with smaller sizes and context home windows earlier than scaling as much as bigger fashions. Specialised smaller fashions have their capability targeting a selected goal activity. On these duties, specialised fashions can behave qualitatively equally to bigger fashions (for instance, GPT3.5, which has 175 billion parameters) whereas requiring fewer sources for coaching and inference. Examples of such fashions embody Alpaca (7 billion parameters) or the utilization of T5 variants for multi-step math reasoning (11 billion parameters or more).
Immediate engineering
Efficient prompt engineering can improve the efficiency and effectivity of generative AI fashions. By fastidiously crafting prompts, you possibly can information the mannequin’s conduct, lowering pointless iterations and useful resource necessities. Take into account the next pointers:
- Hold prompts concise and keep away from pointless particulars – Longer prompts result in a better variety of tokens. As tokens improve in quantity, the mannequin consumes extra reminiscence and computational sources. Take into account incorporating zero-shot or few-shot studying to allow the mannequin to adapt shortly by studying from only a few examples.
- Experiment with totally different prompts progressively – Refine the prompts based mostly on the specified output till you obtain the specified outcomes. Relying in your activity, explore advanced techniques similar to self-consistency, Generated Knowledge Prompting, ReAct Prompting, or Automatic Prompt Engineer to additional improve the mannequin’s capabilities.
- Use reproducible prompts – With templates similar to LangChain prompt templates, it can save you or load your prompts historical past as information. This enhances immediate experimentation monitoring, versioning, and reusability. When you recognize the prompts that produce the most effective solutions for every mannequin, you possibly can cut back the computational sources used for immediate iterations and redundant experiments throughout totally different tasks.
Retrieval Augmented Technology
Retrieval Augmented Technology (RAG) is a extremely efficient strategy for augmenting mannequin capabilities by retrieving and integrating pertinent exterior data from a predefined dataset. As a result of present LLMs are used as is, this technique avoids the power and sources wanted to coach the mannequin on new information or construct a brand new mannequin from scratch. Use instruments similar to Amazon Kendra or Amazon OpenSearch Service and LangChain to efficiently construct RAG-based solutions with Amazon Bedrock or SageMaker JumpStart.
Parameter-Environment friendly Fantastic-Tuning
Parameter-Environment friendly Fantastic-Tuning (PEFT) is a basic facet of sustainability in generative AI. It goals to realize efficiency akin to fine-tuning, utilizing fewer trainable parameters. By fine-tuning solely a small variety of mannequin parameters whereas freezing most parameters of the pre-trained LLMs, we are able to reduce computational resources and power consumption.
Use public libraries such because the Parameter-Efficient Fine-Tuning library to implement widespread PEFT methods similar to Low Rank Adaptation (LoRa), Prefix Tuning, Prompt Tuning, or P-Tuning. For instance, studies present the utilization of LoRa can cut back the variety of trainable parameters by 10,000 instances and the GPU reminiscence requirement by 3 instances, relying on the dimensions of your mannequin, with related or higher efficiency.
Fantastic-tuning
Fine-tune your complete pre-trained mannequin with the extra information. This strategy might obtain larger efficiency however is extra resource-intensive than PEFT. Use this technique when the out there information considerably differs from the pre-training information.
By choosing the appropriate fine-tuning strategy, you possibly can maximize the reuse of your mannequin and keep away from the useful resource utilization related to fine-tuning a number of fashions for every use case. For instance, if you happen to anticipate reusing the mannequin inside a selected area or enterprise unit in your group, you could choose domain adaptation. However, instruction-based fine-tuning is healthier fitted to normal use throughout a number of duties.
Mannequin coaching from scratch
In some instances, coaching an LLM mannequin from scratch could also be crucial. Nonetheless, this strategy may be computationally costly and energy-intensive. To make sure optimum coaching, think about the next greatest practices:
Mannequin inference and deployment
Take into account the next greatest practices for mannequin inference and deployment:
- Use deep studying containers for giant mannequin inference – You should utilize deep learning containers for large model inference on SageMaker and open-source frameworks similar to DeepSpeed, Hugging Face Accelerate, and FasterTransformer to implement techniques like weight pruning, distillation, compression, quantization, or compilation. These methods cut back mannequin measurement and optimize reminiscence utilization.
- Set applicable inference mannequin parameters – Throughout inference, you’ve got the pliability to regulate sure parameters that affect the mannequin’s output. Understanding and appropriately setting these parameters permits you to get hold of essentially the most related responses out of your fashions and reduce the variety of iterations of prompt-tuning. This finally leads to lowered reminiscence utilization and decrease power consumption. Key parameters to contemplate are
temperature,top_p,top_k, andmax_length. - Undertake an environment friendly inference infrastructure – You may deploy your fashions on an AWS Inferentia2 accelerator. Inf2 cases supply as much as 50% higher efficiency/watt over comparable Amazon Elastic Compute Cloud (Amazon EC2) cases as a result of the underlying AWS Inferentia2 accelerators are objective constructed to run deep studying fashions at scale. Because the most energy-efficient option on Amazon EC2 for deploying ultra-large models, Inf2 cases show you how to meet your sustainability targets when deploying the newest improvements in generative AI.
- Align inference Service Stage Settlement (SLA) with sustainability targets – Define SLAs that support your sustainability goals whereas assembly what you are promoting necessities. Outline SLAs to fulfill what you are promoting necessities, not exceed them. Make trade-offs that considerably cut back your sources utilization in alternate for acceptable decreases in service ranges:
Useful resource utilization monitoring and optimization
Implement an improvement process to trace the impression of your optimizations over time. The purpose of your enhancements is to make use of all of the sources you provision and full the identical work with the minimal sources attainable. To operationalize this course of, gather metrics concerning the utilization of your cloud sources. These metrics, combined with business metrics, can be utilized as proxy metrics for your carbon emissions.
To constantly monitor your surroundings, you need to use Amazon CloudWatch to observe system metrics like CPU, GPU, or reminiscence utilization. In case you are utilizing NVIDIA GPU, think about NVIDIA System Management Interface (nvidia-smi) to observe GPU utilization and efficiency state. For Trainium and AWS Inferentia accelerator, you need to use AWS Neuron Monitor to observe system metrics. Take into account additionally SageMaker Profiler, which supplies an in depth view into the AWS compute sources provisioned throughout coaching deep studying fashions on SageMaker. The next are some key metrics price monitoring:
CPUUtilization,GPUUtilization,GPUMemoryUtilization,MemoryUtilization, andDiskUtilizationin CloudWatchnvidia_smi.gpu_utilization,nvidia_smi.gpu_memory_utilization, andnvidia_smi.gpu_performance_statein nvidia-smi logs.vcpu_usage,memory_info, andneuroncore_utilizationin Neuron Monitor.
Conclusion
As generative AI fashions have gotten larger, it’s important to contemplate the environmental impression of our workloads.
On this submit, we offered steering for optimizing the compute, storage, and networking sources required to run your generative AI workloads on AWS whereas minimizing their environmental impression. As a result of the sector of generative AI is repeatedly progressing, staying up to date with the newest courses, analysis, and instruments can assist you discover new methods to optimize your workloads for sustainability.
In regards to the Authors
 Dr. Wafae Bakkali is a Information Scientist at AWS, based mostly in Paris, France. As a generative AI skilled, Wafae is pushed by the mission to empower clients in fixing their enterprise challenges by way of the utilization of generative AI methods, making certain they achieve this with most effectivity and sustainability.
Dr. Wafae Bakkali is a Information Scientist at AWS, based mostly in Paris, France. As a generative AI skilled, Wafae is pushed by the mission to empower clients in fixing their enterprise challenges by way of the utilization of generative AI methods, making certain they achieve this with most effectivity and sustainability.
 Benoit de Chateauvieux is a Startup Options Architect at AWS, based mostly in Montreal, Canada. As a former CTO, he enjoys serving to startups construct nice merchandise utilizing the cloud. He additionally helps clients in fixing their sustainability challenges by way of the cloud. Exterior of labor, you’ll discover Benoit in canoe-camping expeditions, paddling throughout Canadian rivers.
Benoit de Chateauvieux is a Startup Options Architect at AWS, based mostly in Montreal, Canada. As a former CTO, he enjoys serving to startups construct nice merchandise utilizing the cloud. He additionally helps clients in fixing their sustainability challenges by way of the cloud. Exterior of labor, you’ll discover Benoit in canoe-camping expeditions, paddling throughout Canadian rivers.





