Speed up shopper success administration by e mail classification with Hugging Face on Amazon SageMaker

This can be a visitor publish from Scalable Capital, a number one FinTech in Europe that gives digital wealth administration and a brokerage platform with a buying and selling flat charge.
As a fast-growing firm, Scalable Capital’s objectives are to not solely construct an progressive, sturdy, and dependable infrastructure, however to additionally present the very best experiences for our purchasers, particularly with regards to shopper companies.
Scalable receives a whole bunch of e mail inquiries from our purchasers each day. By implementing a contemporary pure language processing (NLP) mannequin, the response course of has been formed way more effectively, and ready time for purchasers has been lowered tremendously. The machine studying (ML) mannequin classifies new incoming buyer requests as quickly as they arrive and redirects them to predefined queues, which permits our devoted shopper success brokers to deal with the contents of the emails in accordance with their abilities and supply acceptable responses.
On this publish, we reveal the technical advantages of utilizing Hugging Face transformers deployed with Amazon SageMaker, comparable to coaching and experimentation at scale, and elevated productiveness and cost-efficiency.
Drawback assertion
Scalable Capital is likely one of the quickest rising FinTechs in Europe. With the goal to democratize funding, the corporate gives its purchasers with easy accessibility to the monetary markets. Shoppers of Scalable can actively take part out there by the corporate’s brokerage buying and selling platform, or use Scalable Wealth Administration to put money into an clever and automatic vogue. In 2021, Scalable Capital skilled a tenfold improve of its shopper base, from tens of hundreds to a whole bunch of hundreds.
To offer our purchasers with a top-class (and constant) person expertise throughout merchandise and shopper service, the corporate was on the lookout for automated options to generate efficiencies for a scalable resolution whereas sustaining operational excellence. Scalable Capital’s knowledge science and shopper service groups recognized that one of many largest bottlenecks in servicing our purchasers was responding to e mail inquiries. Particularly, the bottleneck was the classification step, wherein staff needed to learn and label request texts each day. After the emails have been routed to their correct queues, the respective specialists rapidly engaged and resolved the instances.
To streamline this classification course of, the information science group at Scalable constructed and deployed a multitask NLP mannequin utilizing state-of-the-art transformer structure, based mostly on the pre-trained distilbert-base-german-cased mannequin printed by Hugging Face. distilbert-base-german-cased makes use of the knowledge distillation methodology to pretrain a smaller general-purpose language illustration mannequin than the unique BERT base mannequin. The distilled model achieves comparable efficiency to the unique model, whereas being smaller and quicker. To facilitate our ML lifecycle course of, we determined to undertake SageMaker to construct, deploy, serve, and monitor our fashions. Within the following part, we introduce our challenge structure design.
Resolution overview
Scalable Capital’s ML infrastructure consists of two AWS accounts: one as an surroundings for the event stage and the opposite one for the manufacturing stage.
The next diagram exhibits the workflow for our e mail classifier challenge, however can be generalized to different knowledge science initiatives.
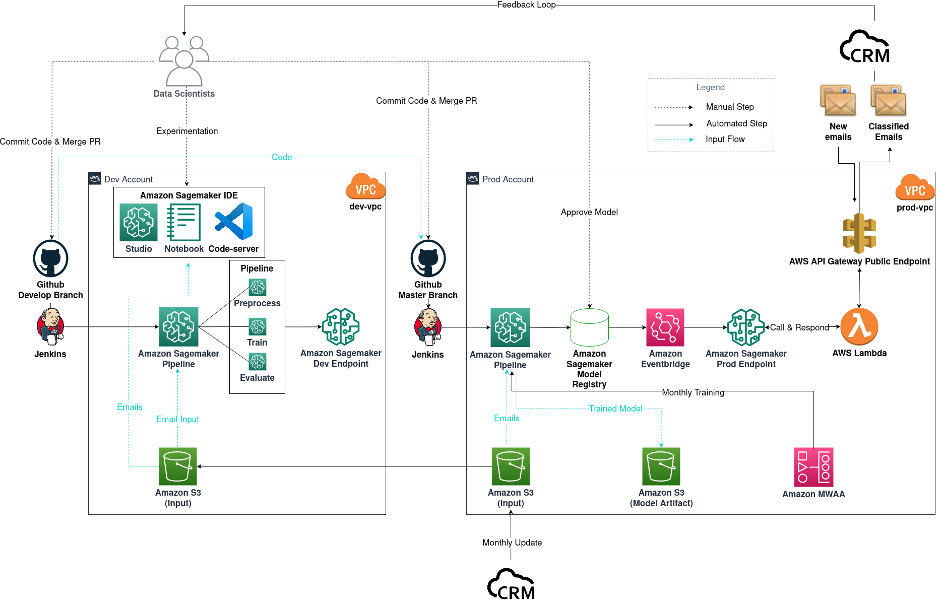
E-mail classification challenge diagram
The workflow consists of the next parts:
- Mannequin experimentation – Information scientists use Amazon SageMaker Studio to hold out the primary steps within the knowledge science lifecycle: exploratory knowledge evaluation (EDA), knowledge cleansing and preparation, and constructing prototype fashions. When the exploratory part is full, we flip to VSCode hosted by a SageMaker pocket book as our distant growth software to modularize and productionize our code base. To discover various kinds of fashions and mannequin configurations, and on the identical time to maintain monitor of our experimentations, we use SageMaker Coaching and SageMaker Experiments.
- Mannequin construct – After we determine on a mannequin for our manufacturing use case, on this case a multi-task distilbert-base-german-cased mannequin, fine-tuned from the pretrained mannequin from Hugging Face, we commit and push our code to Github develop department. The Github merge occasion triggers our Jenkins CI pipeline, which in flip begins a SageMaker Pipelines job with take a look at knowledge. This acts as a take a look at to be sure that codes are operating as anticipated. A take a look at endpoint is deployed for testing functions.
- Mannequin deployment – After ensuring that every little thing is operating as anticipated, knowledge scientists merge the develop department into the first department. This merge occasion now triggers a SageMaker Pipelines job utilizing manufacturing knowledge for coaching functions. Afterwards, mannequin artifacts are produced and saved in an output Amazon Simple Storage Service (Amazon S3) bucket, and a brand new mannequin model is logged within the SageMaker mannequin registry. Information scientists look at the efficiency of the brand new mannequin, then approve if it’s in step with expectations. The mannequin approval occasion is captured by Amazon EventBridge, which then deploys the mannequin to a SageMaker endpoint within the manufacturing surroundings.
- MLOps – As a result of the SageMaker endpoint is non-public and might’t be reached by companies exterior of the VPC, an AWS Lambda operate and Amazon API Gateway public endpoint are required to speak with CRM. Every time new emails arrive within the CRM inbox, CRM invokes the API Gateway public endpoint, which in flip triggers the Lambda operate to invoke the non-public SageMaker endpoint. The operate then relays the classification again to CRM by the API Gateway public endpoint. To observe the efficiency of our deployed mannequin, we implement a suggestions loop between CRM and the information scientists to maintain monitor of prediction metrics from the mannequin. On a month-to-month foundation, CRM updates the historic knowledge used for experimentation and mannequin coaching. We use Amazon Managed Workflows for Apache Airflow (Amazon MWAA) as a scheduler for our month-to-month retrain.
Within the following sections, we break down the information preparation, mannequin experimentation, and mannequin deployment steps in additional element.
Information preparation
Scalable Capital makes use of a CRM software for managing and storing e mail knowledge. Related e mail contents encompass topic, physique, and the custodian banks. There are three labels to assign to every e mail: which line of enterprise the e-mail is from, which queue is suitable, and the particular matter of the e-mail.
Earlier than we begin coaching any NLP fashions, we make sure that the enter knowledge is clear and the labels are assigned in accordance with expectation.
To retrieve clear inquiry contents from Scalable purchasers, we take away from uncooked e mail knowledge and further textual content and symbols, comparable to e mail signatures, impressums, quotes of earlier messages in e mail chains, CSS symbols, and so forth. In any other case, our future skilled fashions would possibly expertise degraded efficiency.
Labels for emails evolve over time as Scalable shopper service groups add new ones and refine or take away present ones to accommodate enterprise wants. To be sure that labels for coaching knowledge in addition to anticipated classifications for prediction are updated, the information science group works in shut collaboration with the shopper service group to make sure the correctness of the labels.
Mannequin experimentation
We begin our experiment with the available pre-trained distilbert-base-german-cased mannequin printed by Hugging Face. As a result of the pre-trained mannequin is a general-purpose language illustration mannequin, we are able to adapt the structure to carry out particular downstream duties—comparable to classification and query answering—by attaching acceptable heads to the neural community. In our use case, the downstream process we’re eager about is sequence classification. With out modifying the existing architecture, we determine to fine-tune three separate pre-trained fashions for every of our required classes. With the SageMaker Hugging Face Deep Learning Containers (DLCs), beginning and managing NLP experiments are made easy with Hugging Face containers and the SageMaker Experiments API.
The next is a code snippet of prepare.py:
The next code is the Hugging Face estimator:
To validate the fine-tuned fashions, we use the F1-score because of the imbalanced nature of our e mail dataset, but in addition to compute different metrics comparable to accuracy, precision, and recall. For the SageMaker Experiments API to register the coaching job’s metrics, we have to first log the metrics to the coaching job native console, that are picked up by Amazon CloudWatch. Then we outline the proper regex format to seize the CloudWatch logs. The metric definitions embody the identify of the metrics and regex validation for extracting the metrics from the coaching job:
As a part of the coaching iteration for the classifier mannequin, we use a confusion matrix and classification report to guage the outcome. The next determine exhibits the confusion matrix for line of enterprise prediction.
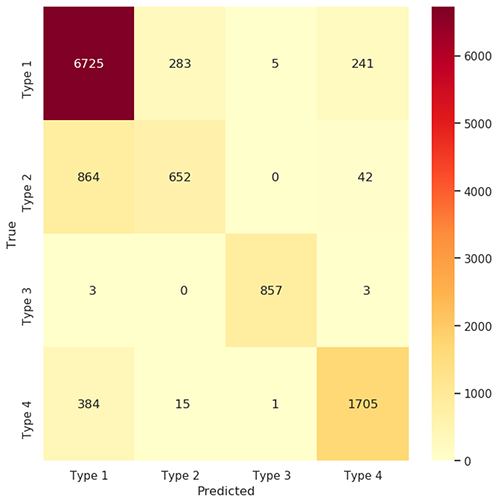
Confusion Matrix
The next screenshot exhibits an instance of the classification report for line of enterprise prediction.
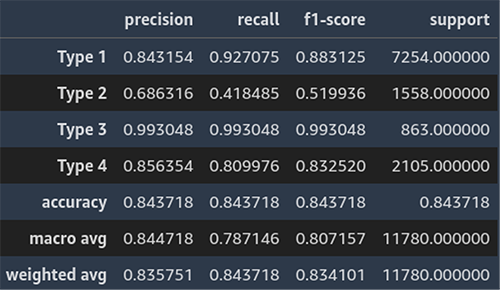
Classification Report
As a subsequent iteration of our experiment, we’ll reap the benefits of multi-task learning to enhance our mannequin. Multi-task studying is a type of coaching the place a mannequin learns to unravel a number of duties concurrently, as a result of the shared info amongst duties can enhance studying efficiencies. By attaching two extra classification heads to the unique distilbert structure, we are able to perform multi-task fine-tuning, which attains affordable metrics for our shopper service group.
Mannequin deployment
In our use case, the e-mail classifier is to be deployed to an endpoint, to which our CRM pipeline can ship a batch of unclassified emails and get again predictions. As a result of now we have different logics—comparable to enter knowledge cleansing and multi-task predictions—along with Hugging Face mannequin inference, we have to write a customized inference script that adheres to the SageMaker standard.
The next is a code snippet of inference.py:
When every little thing is up and prepared, we use SageMaker Pipelines to handle our coaching pipeline and connect it to our infrastructure to finish our MLOps setup.
To observe the efficiency of the deployed mannequin, we construct a suggestions loop to allow CRM to offer us with the standing of categorized emails when instances are closed. Based mostly on this info, we make changes to enhance the deployed mannequin.
Conclusion
On this publish, we shared how SageMaker facilitates the information science group at Scalable to handle the lifecycle of a knowledge science challenge effectively, specifically the e-mail classifier challenge. The lifecycle begins with the preliminary part of information evaluation and exploration with SageMaker Studio; strikes on to mannequin experimentation and deployment with SageMaker coaching, inference, and Hugging Face DLCs; and completes with a coaching pipeline with SageMaker Pipelines built-in with different AWS companies. Due to this infrastructure, we’re capable of iterate and deploy new fashions extra effectively, and are subsequently capable of enhance present processes inside Scalable in addition to our purchasers’ experiences.
To be taught extra about Hugging Face and SageMaker, check with the next assets:
Concerning the Authors
 Dr. Sandra Schmid is Head of Information Analytics at Scalable GmbH. She is answerable for data-driven approaches and use instances within the firm collectively along with her groups. Her key focus is discovering the very best mixture of machine studying and knowledge science fashions and enterprise objectives to be able to acquire as a lot enterprise worth and efficiencies out of information as attainable.
Dr. Sandra Schmid is Head of Information Analytics at Scalable GmbH. She is answerable for data-driven approaches and use instances within the firm collectively along with her groups. Her key focus is discovering the very best mixture of machine studying and knowledge science fashions and enterprise objectives to be able to acquire as a lot enterprise worth and efficiencies out of information as attainable.
 Huy Dang Information Scientist at Scalable GmbH. His obligations embody knowledge analytics, constructing and deploying machine studying fashions, in addition to growing and sustaining infrastructure for the information science group. In his spare time, he enjoys studying, mountaineering, mountaineering, and staying updated with the most recent machine studying developments.
Huy Dang Information Scientist at Scalable GmbH. His obligations embody knowledge analytics, constructing and deploying machine studying fashions, in addition to growing and sustaining infrastructure for the information science group. In his spare time, he enjoys studying, mountaineering, mountaineering, and staying updated with the most recent machine studying developments.
 Mia Chang is a ML Specialist Options Architect for Amazon Internet Companies. She works with prospects in EMEA and shares finest practices for operating AI/ML workloads on the cloud along with her background in utilized arithmetic, laptop science, and AI/ML. She focuses on NLP-specific workloads, and shares her expertise as a convention speaker and a e book creator. In her free time, she enjoys yoga, board video games, and brewing espresso.
Mia Chang is a ML Specialist Options Architect for Amazon Internet Companies. She works with prospects in EMEA and shares finest practices for operating AI/ML workloads on the cloud along with her background in utilized arithmetic, laptop science, and AI/ML. She focuses on NLP-specific workloads, and shares her expertise as a convention speaker and a e book creator. In her free time, she enjoys yoga, board video games, and brewing espresso.
 Moritz Guertler is an Account Government within the Digital Native Companies section at AWS. He focuses on prospects within the FinTech house and helps them in accelerating innovation by safe and scalable cloud infrastructure.
Moritz Guertler is an Account Government within the Digital Native Companies section at AWS. He focuses on prospects within the FinTech house and helps them in accelerating innovation by safe and scalable cloud infrastructure.





