LLM Monitoring and Observability — A Abstract of Methods and Approaches for Accountable AI | by Josh Poduska | Sep, 2023
10 hours in the past
Supposed Viewers: Practitioners who need to be taught what approaches can be found and the way to get began implementing them, and leaders searching for to know the artwork of the attainable as they construct governance frameworks and technical roadmaps.
Seemingly in a single day each CEO to-do listing, job posting, and resume contains generative AI (genAI). And rightfully so. Purposes primarily based on basis fashions have already modified the way in which thousands and thousands work, be taught, write, design, code, journey, and store. Most, together with me, really feel that is simply the tip of the iceberg.
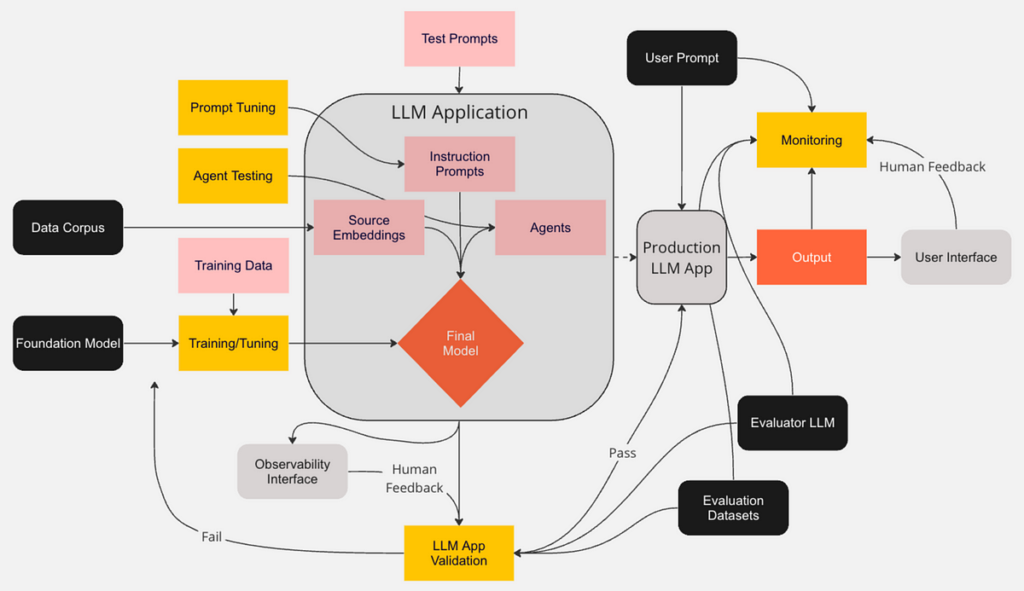
On this article, I summarize analysis carried out on current strategies for giant language mannequin (LLM) monitoring. I spent many hours studying documentation, watching movies, and studying blogs from software program distributors and open-source libraries specializing in LLM monitoring and observability. The result’s a sensible taxonomy for monitoring and observing LLMs. I hope you discover it helpful. Within the close to future, I plan to conduct a literature search of educational papers so as to add a forward-looking perspective.
Software program researched*: Aporia, Arize, Arthur, Censius, Databricks/MLFlow, Datadog, DeepChecks, Evidently, Fiddler, Galileo, Giskard, Honeycomb, Hugging Face, LangSmith, New Relic, OpenAI, Parea, Trubrics, Truera, Weights & Biases, Why Labs
- *This text presents a cumulative taxonomy with out grading or evaluating software program choices. Reach out to me for those who’d like to debate a selected software program lined in my analysis.
- Evaluating LLMs — How are LLMs evaluated and deemed prepared for manufacturing?
- Monitoring LLMs — What does it imply to trace an LLM and what elements should be included?
- Monitoring LLMs — How are LLMs monitored as soon as they’re in manufacturing?

The race is on to include LLMs in manufacturing workflows, however the technical group is scrambling to develop greatest practices to make sure these highly effective fashions behave as anticipated over time.
Evaluating a standard machine studying (ML) mannequin includes checking the accuracy of its output or predictions. That is normally measured by well-known metrics equivalent to Accuracy, RMSE, AUC, Precision, Recall, and so forth. Evaluating LLMs is much more difficult. A number of strategies are used at this time by information scientists.
(1) Classification and Regression Metrics
LLMs can produce numeric predictions or classification labels, by which case analysis is simple. It’s the identical as with conventional ML fashions. Whereas that is useful in some circumstances, we’re normally involved with evaluating LLMs that produce textual content.
(2) Standalone text-based Metrics
These metrics are helpful for evaluating textual content output from an LLM if you do not need a supply of floor reality. It’s as much as you to find out what is suitable primarily based on previous expertise, educational solutions, or evaluating scores of different fashions.
Perplexity is one instance. It measures the chance the mannequin would generate an enter textual content sequence and may be considered evaluating how nicely the mannequin discovered the textual content it was skilled on. Different examples embody Reading Level and Non-letter Characters.
A extra refined standalone strategy includes extracting embeddings from mannequin output and analyzing these embeddings for uncommon patterns. This may be finished manually by inspecting a graph of your embeddings in a 3D plot. Coloring or evaluating by key fields like gender, predicted class, or perplexity rating can reveal lurking issues together with your LLM utility and supply a measure of bias and explainability. A number of software program instruments exist that will let you visualize embeddings on this manner. They cluster the embeddings and map them into 3 dimensions. That is normally finished with HDBSCAN and UMAP, however some leverage a K-means-based approach.
Along with visible evaluation, an anomaly detection algorithm may be run throughout the embeddings to search for outliers.
(3) Analysis Datasets
A dataset with floor reality labels permits for the comparability of textual output to a baseline of permitted responses.
A widely known instance is the ROUGE metric. Within the case of language translation duties, ROUGE depends on a reference dataset whose solutions are in contrast in opposition to the LLM being evaluated. Relevance, accuracy, and a bunch of different metrics may be calculated in opposition to a reference dataset. Embeddings play a key position. Normal distance metrics like as J-S Distance, Hellinger Distance, KS Distance, and PSI examine your LLM output embeddings to the bottom reality embeddings.
Lastly, there are a variety of extensively accepted benchmark exams for LLMs. Stanford’s HELM page is a superb place to study them.
(4) Evaluator LLMs
At first look, you might assume it’s dishonest the system to make use of an LLM to guage an LLM, however many really feel that that is the perfect path ahead and studies have proven promise. It’s extremely doubtless that utilizing what I name Evaluator LLMs would be the predominant technique for LLM analysis within the close to future.
One extensively accepted instance is the Toxicity metric. It depends on an Evaluator LLM (Hugging Face recommends roberta-hate-speech-dynabench-r4) to find out in case your mannequin’s output is Poisonous. All of the metrics above underneath Analysis Datasets apply right here as we deal with the output of the Evaluator LLM because the reference.
In response to researchers at Arize, Evaluator LLMs needs to be configured to supply binary classification labels for the metrics they check. Numeric scores and rating, they explain, want extra work and are usually not as performant as binary labeling.
(5) Human Suggestions
With all of the emphasis on measurable metrics on this submit, software program documentation, and advertising and marketing materials, you shouldn’t overlook about guide human-based suggestions. That is normally thought of by information scientists and engineers within the early levels of constructing an LLM utility. LLM observability software program normally has an interface to help on this process. Along with early improvement suggestions, it’s a greatest apply to incorporate human suggestions within the ultimate analysis course of as nicely (and ongoing monitoring). Grabbing 50 to 100 enter prompts and manually analyzing the output can educate you a large number about your ultimate product.
Monitoring is the precursor to monitoring. In my analysis, I discovered sufficient nuance within the particulars of monitoring LLMs to warrant its personal part. The low-hanging fruit of monitoring includes capturing the variety of requests, response time, token utilization, prices, and error charges. Normal system monitoring instruments play a job right here alongside the extra LLM-specific choices (and people conventional monitoring firms have advertising and marketing groups which might be fast to assert LLM Observability and Monitoring primarily based on easy practical metric monitoring).
Deep insights are gained from capturing enter prompts and output responses for future evaluation. This sounds easy on the floor, nevertheless it’s not. The complexity comes from one thing I’ve glossed over up to now (and most information scientists do the identical when speaking or writing about LLMs). We’re not evaluating, monitoring, and monitoring an LLM. We’re coping with an utility; a conglomerate of a number of LLMs, pre-set instruction prompts, and brokers that work collectively to supply the output. Some LLM purposes are usually not that advanced, however many are, and the development is towards extra sophistication. In even barely refined LLM purposes it may be tough to nail down the ultimate immediate name. If we’re debugging, we’ll have to know the state of the decision at every step alongside the way in which and the sequence of these steps. Practitioners will need to leverage software program that helps with unpacking these complexities.
Whereas most LLMs and LLM purposes bear a minimum of some type of analysis, too few have carried out steady monitoring. We’ll break down the elements of monitoring that will help you construct a monitoring program that protects your customers and model.
(1) Practical Monitoring
To begin, the low-hanging fruit talked about within the Monitoring part above needs to be monitored on a steady foundation. This contains the variety of requests, response time, token utilization, prices, and error charges.
(2) Monitoring Prompts
Subsequent in your listing needs to be monitoring user-supplied prompts or inputs. Standalone metrics like Readability may very well be informative. Evaluator LLMs needs to be utilized to verify for Toxicity and the like. Embedding distances from the reference prompts are sensible metrics to incorporate. Even when your utility can deal with prompts which might be considerably totally different than what you anticipated, it would be best to know in case your clients’ interplay together with your utility is new or adjustments over time.
At this level, we have to introduce a brand new analysis class: adversarial makes an attempt or malicious immediate injections. This isn’t all the time accounted for within the preliminary analysis. Evaluating in opposition to reference units of recognized adversarial prompts can flag dangerous actors. Evaluator LLMs may also classify prompts as malicious or not.
(3) Monitoring Responses
There are a selection of helpful checks to implement when evaluating what your LLM utility is spitting out to what you count on. Contemplate relevance. Is your LLM responding with related content material or is it off within the weeds (hallucination)? Are you seeing a divergence out of your anticipated matters? How about sentiment? Is your LLM responding in the appropriate tone and is that this altering over time?
You most likely don’t want to observe all these metrics every day. Month-to-month or quarterly might be enough for some. However, Toxicity and dangerous output are all the time prime on the fear listing when deploying LLMs. These are examples of metrics that it would be best to observe on a extra common foundation. Do not forget that the embedding visualization strategies mentioned earlier could assist with root trigger evaluation.
Prompt leakage is an adversarial strategy we haven’t launched but. Immediate leakage happens when somebody methods your utility into divulging your saved prompts. You doubtless spent numerous time determining which pre-set immediate directions gave the perfect outcomes. That is delicate IP. Immediate leakage may be found by monitoring responses and evaluating them to your database of immediate directions. Embedding distance metrics work nicely.
In case you have analysis or reference datasets, you might need to periodically check your LLM utility in opposition to these and examine the outcomes of earlier exams. This may give you a way of accuracy over time and may warn you to float. For those who uncover points, some instruments that handle embeddings will let you export datasets of underperforming output so you’ll be able to fine-tune your LLM on these lessons of troublesome prompts.
(4) Alerting and Thresholds
Care needs to be taken to make sure that your thresholds and alerts don’t trigger too many false alarms. Multivariate drift detection and alerting will help. I’ve ideas on how to do that however will save these for an additional article. By the way, I didn’t see one point out of false alarm charges or greatest practices for thresholds in any of my analysis for this text. That’s a disgrace.
There are a number of good options associated to alerts that you could be need to embody in your must-have listing. Many monitoring programs present integration with data feeds like Slack and Pager Responsibility. Some monitoring programs enable computerized response blocking if the enter immediate triggers an alert. The identical characteristic can apply to screening the response for PII leakage, Toxicity, and different high quality metrics earlier than sending it to the consumer.
I’ll add another remark right here as I didn’t know the place else to place it. Customized metrics may be essential to your monitoring scheme. Your LLM utility could also be distinctive, or maybe a pointy information scientist in your workforce considered a metric that can add vital worth to your strategy. There’ll doubtless be advances on this house. You will have the pliability of customized metrics.
(5) The Monitoring UI
If a system has a monitoring functionality, it’s going to have a UI that reveals time-series graphs of metrics. That’s fairly commonplace. UIs begin to differentiate once they enable for drilling down into alert developments in a way that factors to some stage of root trigger evaluation. Others facilitate visualization of the embedding house primarily based on clusters and projections (I’d prefer to see, or conduct, a examine on the usefulness of those embedding visualizations within the wild).
Extra mature choices will group monitoring by customers, initiatives, and groups. They are going to have RBAC and work off the idea that every one customers are on a need-to-know foundation. Too usually anybody within the instrument can see everybody’s information, and that gained’t fly at a lot of at this time’s organizations.
One reason for the issue I highlighted relating to the tendency for alerts to yield an unacceptable false alarm charge is that the UI doesn’t facilitate a correct evaluation of alerts. It’s uncommon for software program programs to aim any type of optimization on this respect, however some do. Once more, there may be far more to say on this subject at a later level.
Leaders, there may be an excessive amount of at stake to not place LLM monitoring and observability close to the highest of your organizational initiatives. I don’t say this solely to forestall inflicting hurt to customers or shedding model popularity. These are clearly in your radar. What you won’t recognize is that your organization’s fast and sustainable adoption of AI may imply the distinction between success and failure, and a mature responsible AI framework with an in depth technical roadmap for monitoring and observing LLM purposes will present a basis to allow you to scale sooner, higher, and safer than the competitors.
Practitioners, the ideas launched on this article present an inventory of instruments, strategies, and metrics that needs to be included within the implementation of LLM observability and monitoring. You need to use this as a information to make sure that your monitoring system is as much as the duty. And you need to use this as a foundation for deeper examine into every idea we mentioned.
That is an thrilling new area. Leaders and practitioners who turn into well-versed in it will likely be positioned to assist their groups and firms succeed within the age of AI.
Concerning the writer:
Josh Poduska is an AI Chief, Strategist, and Advisor with over 20 years of expertise. He’s the previous Chief Discipline Knowledge Scientist at Domino Knowledge Lab and has managed groups and led information science technique at a number of firms. Josh has constructed and carried out information science options throughout a number of domains. He has a Bachelor’s in Arithmetic from UC Irvine and a Grasp’s in Utilized Statistics from Cornell College.



