World scale inverse reinforcement studying in Google Maps – Google Analysis Weblog
Routing in Google Maps stays one in all our most useful and often used options. Figuring out the perfect route from A to B requires making complicated trade-offs between elements together with the estimated time of arrival (ETA), tolls, directness, floor circumstances (e.g., paved, unpaved roads), and person preferences, which differ throughout transportation mode and native geography. Typically, probably the most pure visibility we have now into vacationers’ preferences is by analyzing real-world journey patterns.
Studying preferences from noticed sequential determination making habits is a basic utility of inverse reinforcement learning (IRL). Given a Markov decision process (MDP) — a formalization of the highway community — and a set of demonstration trajectories (the traveled routes), the aim of IRL is to recuperate the customers’ latent reward operate. Though past research has created more and more normal IRL options, these haven’t been efficiently scaled to world-sized MDPs. Scaling IRL algorithms is difficult as a result of they usually require fixing an RL subroutine at each replace step. At first look, even trying to suit a world-scale MDP into reminiscence to compute a single gradient step seems infeasible as a result of giant variety of highway segments and restricted excessive bandwidth reminiscence. When making use of IRL to routing, one wants to contemplate all affordable routes between every demonstration’s origin and vacation spot. This means that any try to interrupt the world-scale MDP into smaller elements can’t take into account elements smaller than a metropolitan space.
To this finish, in “Massively Scalable Inverse Reinforcement Learning in Google Maps“, we share the results of a multi-year collaboration amongst Google Analysis, Maps, and Google DeepMind to surpass this IRL scalability limitation. We revisit basic algorithms on this house, and introduce advances in graph compression and parallelization, together with a brand new IRL algorithm referred to as Receding Horizon Inverse Planning (RHIP) that gives fine-grained management over efficiency trade-offs. The ultimate RHIP coverage achieves a 16–24% relative enchancment in international route match price, i.e., the share of de-identified traveled routes that precisely match the urged route in Google Maps. To the perfect of our data, this represents the most important occasion of IRL in an actual world setting so far.
 |
| Google Maps enhancements in route match price relative to the present baseline, when utilizing the RHIP inverse reinforcement studying coverage. |
The advantages of IRL
A delicate however essential element in regards to the routing drawback is that it’s aim conditioned, that means that each vacation spot state induces a barely completely different MDP (particularly, the vacation spot is a terminal, zero-reward state). IRL approaches are nicely fitted to a lot of these issues as a result of the realized reward operate transfers throughout MDPs, and solely the vacation spot state is modified. That is in distinction to approaches that instantly be taught a coverage, which generally require an additional issue of S parameters, the place S is the variety of MDP states.
As soon as the reward operate is realized through IRL, we reap the benefits of a robust inference-time trick. First, we consider all the graph’s rewards as soon as in an offline batch setting. This computation is carried out completely on servers with out entry to particular person journeys, and operates solely over batches of highway segments within the graph. Then, we save the outcomes to an in-memory database and use a quick on-line graph search algorithm to seek out the very best reward path for routing requests between any origin and vacation spot. This circumvents the necessity to carry out on-line inference of a deeply parameterized mannequin or coverage, and vastly improves serving prices and latency.
 |
| Reward mannequin deployment utilizing batch inference and quick on-line planners. |
Receding Horizon Inverse Planning
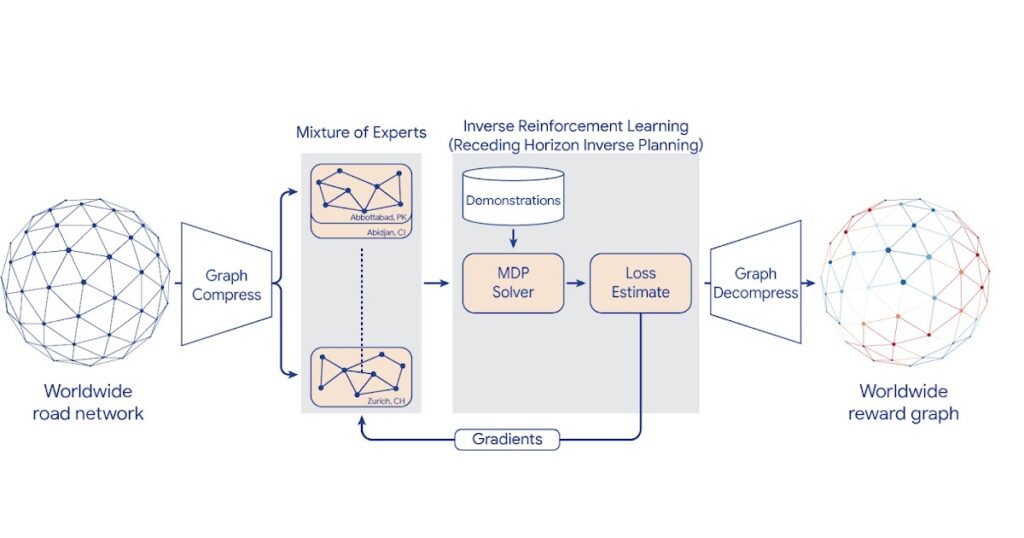
To scale IRL to the world MDP, we compress the graph and shard the worldwide MDP utilizing a sparse Mixture of Experts (MoE) based mostly on geographic areas. We then apply basic IRL algorithms to unravel the native MDPs, estimate the loss, and ship gradients again to the MoE. The worldwide reward graph is computed by decompressing the ultimate MoE reward mannequin. To supply extra management over efficiency traits, we introduce a brand new generalized IRL algorithm referred to as Receding Horizon Inverse Planning (RHIP).
 |
| IRL reward mannequin coaching utilizing MoE parallelization, graph compression, and RHIP. |
RHIP is impressed by individuals’s tendency to carry out in depth native planning (“What am I doing for the subsequent hour?”) and approximate long-term planning (“What is going to my life appear to be in 5 years?”). To reap the benefits of this perception, RHIP makes use of strong but costly stochastic insurance policies within the native area surrounding the demonstration path, and switches to cheaper deterministic planners past some horizon. Adjusting the horizon H permits controlling computational prices, and infrequently permits the invention of the efficiency candy spot. Curiously, RHIP generalizes many basic IRL algorithms and gives the novel perception that they are often considered alongside a stochastic vs. deterministic spectrum (particularly, for H=∞ it reduces to MaxEnt, for H=1 it reduces to BIRL, and for H=0 it reduces to MMP).
 |
| Given an illustration from so to sd, (1) RHIP follows a strong but costly stochastic coverage within the native area surrounding the demonstration (blue area). (2) Past some horizon H, RHIP switches to following a less expensive deterministic planner (purple traces). Adjusting the horizon permits fine-grained management over efficiency and computational prices. |
Routing wins
The RHIP coverage gives a 15.9% and 24.1% carry in international route match price for driving and two-wheelers (e.g., scooters, bikes, mopeds) relative to the well-tuned Maps baseline, respectively. We’re particularly enthusiastic about the advantages to extra sustainable transportation modes, the place elements past journey time play a considerable position. By tuning RHIP’s horizon H, we’re capable of obtain a coverage that’s each extra correct than all different IRL insurance policies and 70% quicker than MaxEnt.
Our 360M parameter reward mannequin gives intuitive wins for Google Maps customers in reside A/B experiments. Inspecting highway segments with a big absolute distinction between the realized rewards and the baseline rewards will help enhance sure Google Maps routes. For instance:
 |
| Nottingham, UK. The popular route (blue) was beforehand marked as personal property as a result of presence of a giant gate, which indicated to our methods that the highway could also be closed at occasions and wouldn’t be splendid for drivers. Consequently, Google Maps routed drivers by an extended, alternate detour as an alternative (purple). Nonetheless, as a result of real-world driving patterns confirmed that customers often take the popular route with out a problem (because the gate is sort of by no means closed), IRL now learns to route drivers alongside the popular route by putting a big optimistic reward on this highway phase. |
Conclusion
Rising efficiency through elevated scale – each when it comes to dataset dimension and mannequin complexity – has confirmed to be a persistent development in machine studying. Related good points for inverse reinforcement studying issues have traditionally remained elusive, largely as a result of challenges with dealing with virtually sized MDPs. By introducing scalability developments to basic IRL algorithms, we’re now capable of practice reward fashions on issues with lots of of thousands and thousands of states, demonstration trajectories, and mannequin parameters, respectively. To the perfect of our data, that is the most important occasion of IRL in a real-world setting so far. See the paper to be taught extra about this work.
Acknowledgements
This work is a collaboration throughout a number of groups at Google. Contributors to the venture embrace Matthew Abueg, Oliver Lange, Matt Deeds, Jason Dealer, Denali Molitor, Markus Wulfmeier, Shawn O’Banion, Ryan Epp, Renaud Hartert, Rui Music, Thomas Sharp, Rémi Robert, Zoltan Szego, Beth Luan, Brit Larabee and Agnieszka Madurska.
We’d additionally like to increase our because of Arno Eigenwillig, Jacob Moorman, Jonathan Spencer, Remi Munos, Michael Bloesch and Arun Ahuja for invaluable discussions and options.





