Image tuning improves in-context studying in language fashions – Google Analysis Weblog

A key function of human intelligence is that people can be taught to carry out new duties by reasoning utilizing only some examples. Scaling up language fashions has unlocked a variety of latest purposes and paradigms in machine studying, together with the power to carry out difficult reasoning duties through in-context learning. Language fashions, nonetheless, are nonetheless delicate to the way in which that prompts are given, indicating that they aren’t reasoning in a sturdy method. As an illustration, language fashions typically require heavy immediate engineering or phrasing duties as directions, and so they exhibit surprising behaviors comparable to performance on tasks being unaffected even when shown incorrect labels.
In “Symbol tuning improves in-context learning in language models”, we suggest a easy fine-tuning process that we name image tuning, which may enhance in-context studying by emphasizing enter–label mappings. We experiment with image tuning throughout Flan-PaLM fashions and observe advantages throughout varied settings.
- Image tuning boosts efficiency on unseen in-context studying duties and is rather more sturdy to underspecified prompts, comparable to these with out directions or with out pure language labels.
- Image-tuned fashions are a lot stronger at algorithmic reasoning duties.
- Lastly, symbol-tuned fashions present massive enhancements in following flipped-labels introduced in-context, which means that they’re extra able to utilizing in-context data to override prior information.
 |
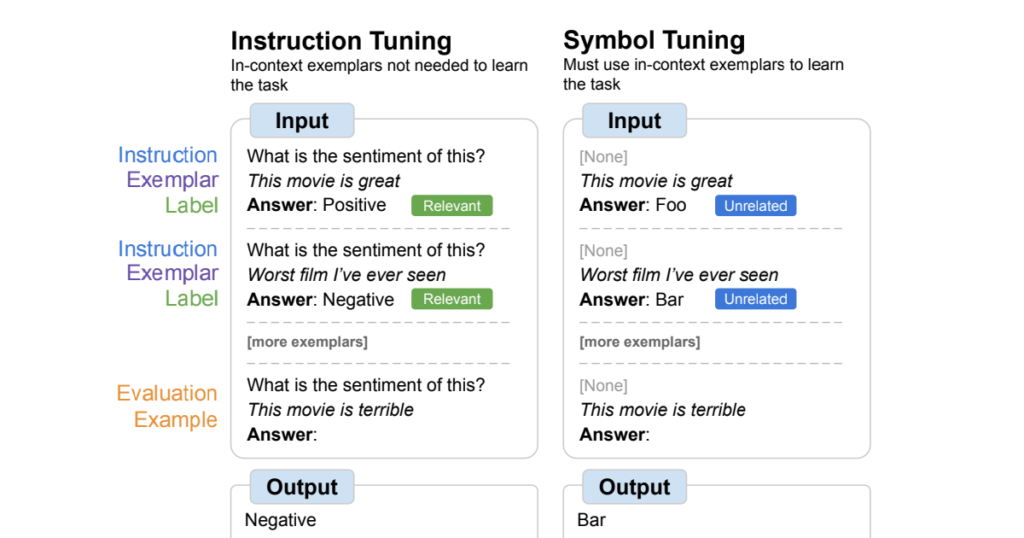
| An summary of image tuning, the place fashions are fine-tuned on duties the place pure language labels are changed with arbitrary symbols. Image tuning depends on the instinct that when instruction and related labels should not obtainable, fashions should use in-context examples to be taught the duty. |
Motivation
Instruction tuning is a typical fine-tuning technique that has been proven to enhance efficiency and permit fashions to raised comply with in-context examples. One shortcoming, nonetheless, is that fashions should not pressured to be taught to make use of the examples as a result of the duty is redundantly outlined within the analysis instance through directions and pure language labels. For instance, on the left within the determine above, though the examples might help the mannequin perceive the duty (sentiment evaluation), they aren’t strictly vital for the reason that mannequin may ignore the examples and simply learn the instruction that signifies what the duty is.
In image tuning, the mannequin is fine-tuned on examples the place the directions are eliminated and pure language labels are changed with semantically-unrelated labels (e.g., “Foo,” “Bar,” and so on.). On this setup, the duty is unclear with out wanting on the in-context examples. For instance, on the precise within the determine above, a number of in-context examples can be wanted to determine the duty. As a result of image tuning teaches the mannequin to cause over the in-context examples, symbol-tuned fashions ought to have higher efficiency on duties that require reasoning between in-context examples and their labels.
 |
| Datasets and process sorts used for image tuning. |
Image-tuning process
We chosen 22 publicly-available natural language processing (NLP) datasets that we use for our symbol-tuning process. These duties have been broadly used up to now, and we solely selected classification-type duties since our technique requires discrete labels. We then remap labels to a random label from a set of ~30K arbitrary labels chosen from one in all three classes: integers, character combos, and phrases.
For our experiments, we image tune Flan-PaLM, the instruction-tuned variants of PaLM. We use three totally different sizes of Flan-PaLM fashions: Flan-PaLM-8B, Flan-PaLM-62B, and Flan-PaLM-540B. We additionally examined Flan-cont-PaLM-62B (Flan-PaLM-62B at 1.3T tokens as an alternative of 780B tokens), which we abbreviate as 62B-c.
 |
| We use a set of ∼300K arbitrary symbols from three classes (integers, character combos, and phrases). ∼30K symbols are used throughout tuning and the remaining are held out for analysis. |
Experimental setup
We wish to consider a mannequin’s capacity to carry out unseen duties, so we can’t consider on duties utilized in image tuning (22 datasets) or used throughout instruction tuning (1.8K duties). Therefore, we select 11 NLP datasets that weren’t used throughout fine-tuning.
In-context studying
Within the symbol-tuning process, fashions should be taught to cause with in-context examples with the intention to efficiently carry out duties as a result of prompts are modified to make sure that duties can’t merely be discovered from related labels or directions. Image-tuned fashions ought to carry out higher in settings the place duties are unclear and require reasoning between in-context examples and their labels. To discover these settings, we outline 4 in-context studying settings that adjust the quantity of reasoning required between inputs and labels with the intention to be taught the duty (primarily based on the supply of directions/related labels)
 |
| Relying on the supply of directions and related pure language labels, fashions could must do various quantities of reasoning with in-context examples. When these options should not obtainable, fashions should cause with the given in-context examples to efficiently carry out the duty. |
Image tuning improves efficiency throughout all settings for fashions 62B and bigger, with small enhancements in settings with related pure language labels (+0.8% to +4.2%) and substantial enhancements in settings with out related pure language labels (+5.5% to +15.5%). Strikingly, when related labels are unavailable, symbol-tuned Flan-PaLM-8B outperforms FlanPaLM-62B, and symbol-tuned Flan-PaLM-62B outperforms Flan-PaLM-540B. This efficiency distinction means that image tuning can enable a lot smaller fashions to carry out in addition to massive fashions on these duties (successfully saving ∼10X inference compute).
 |
| Massive-enough symbol-tuned fashions are higher at in-context studying than baselines, particularly in settings the place related labels should not obtainable. Efficiency is proven as common mannequin accuracy (%) throughout eleven duties. |
Algorithmic reasoning
We additionally experiment on algorithmic reasoning duties from BIG-Bench. There are two essential teams of duties: 1) List functions — determine a change operate (e.g., take away the final component in a listing) between enter and output lists containing non-negative integers; and a pair of) simple turing concepts — cause with binary strings to be taught the idea that maps an enter to an output (e.g., swapping 0s and 1s in a string).
On the record operate and easy turing idea duties, image tuning ends in a mean efficiency enchancment of 18.2% and 15.3%, respectively. Moreover, Flan-cont-PaLM-62B with image tuning outperforms Flan-PaLM-540B on the record operate duties on common, which is equal to a ∼10x discount in inference compute. These enhancements counsel that image tuning strengthens the mannequin’s capacity to be taught in-context for unseen process sorts, as image tuning didn’t embody any algorithmic knowledge.
 |
| Image-tuned fashions obtain greater efficiency on record operate duties and easy turing idea duties. (A–E): classes of record features duties. (F): easy turing ideas process. |
Flipped labels
Within the flipped-label experiment, labels of in-context and analysis examples are flipped, which means that prior information and input-label mappings disagree (e.g., sentences containing optimistic sentiment labeled as “detrimental sentiment”), thereby permitting us to check whether or not fashions can override prior information. Previous work has proven that whereas pre-trained fashions (with out instruction tuning) can, to some extent, comply with flipped labels introduced in-context, instruction tuning degraded this capacity.
We see that there’s a comparable development throughout all mannequin sizes — symbol-tuned fashions are rather more able to following flipped labels than instruction-tuned fashions. We discovered that after image tuning, Flan-PaLM-8B sees a mean enchancment throughout all datasets of 26.5%, Flan-PaLM-62B sees an enchancment of 33.7%, and Flan-PaLM-540B sees an enchancment of 34.0%. Moreover, symbol-tuned fashions obtain comparable or higher than common efficiency as pre-training–solely fashions.
 |
| Image-tuned fashions are significantly better at following flipped labels introduced in-context than instruction-tuned fashions are. |
Conclusion
We introduced image tuning, a brand new technique of tuning fashions on duties the place pure language labels are remapped to arbitrary symbols. Image tuning relies off of the instinct that when fashions can’t use directions or related labels to find out a introduced process, it should achieve this by as an alternative studying from in-context examples. We tuned 4 language fashions utilizing our symbol-tuning process, using a tuning combination of twenty-two datasets and roughly 30K arbitrary symbols as labels.
We first confirmed that image tuning improves efficiency on unseen in-context studying duties, particularly when prompts don’t include directions or related labels. We additionally discovered that symbol-tuned fashions had been significantly better at algorithmic reasoning duties, regardless of the dearth of numerical or algorithmic knowledge within the symbol-tuning process. Lastly, in an in-context studying setting the place inputs have flipped labels, image tuning (for some datasets) restores the power to comply with flipped labels that was misplaced throughout instruction tuning.
Future work
By image tuning, we purpose to extend the diploma to which fashions can look at and be taught from enter–label mappings throughout in-context studying. We hope that our outcomes encourage additional work in the direction of bettering language fashions’ capacity to cause over symbols introduced in-context.
Acknowledgements
The authors of this submit at the moment are a part of Google DeepMind. This work was performed by Jerry Wei, Le Hou, Andrew Lampinen, Xiangning Chen, Da Huang, Yi Tay, Xinyun Chen, Yifeng Lu, Denny Zhou, Tengyu Ma, and Quoc V. Le. We wish to thank our colleagues at Google Analysis and Google DeepMind for his or her recommendation and useful discussions.






