Semantic picture seek for articles utilizing Amazon Rekognition, Amazon SageMaker basis fashions, and Amazon OpenSearch Service

Digital publishers are constantly on the lookout for methods to streamline and automate their media workflows in an effort to generate and publish new content material as quickly as they will.
Publishers can have repositories containing tens of millions of photographs and in an effort to get monetary savings, they want to have the ability to reuse these photographs throughout articles. Discovering the picture that greatest matches an article in repositories of this scale could be a time-consuming, repetitive, handbook activity that may be automated. It additionally depends on the pictures within the repository being tagged accurately, which may also be automated (for a buyer success story, consult with Aller Media Finds Success with KeyCore and AWS).
On this submit, we exhibit how you can use Amazon Rekognition, Amazon SageMaker JumpStart, and Amazon OpenSearch Service to unravel this enterprise downside. Amazon Rekognition makes it simple so as to add picture evaluation functionality to your purposes with none machine studying (ML) experience and comes with varied APIs to fulfil use instances corresponding to object detection, content material moderation, face detection and evaluation, and textual content and superstar recognition, which we use on this instance. SageMaker JumpStart is a low-code service that comes with pre-built options, instance notebooks, and lots of state-of-the-art, pre-trained fashions from publicly out there sources which might be simple to deploy with a single click on into your AWS account. These fashions have been packaged to be securely and simply deployable by way of Amazon SageMaker APIs. The brand new SageMaker JumpStart Basis Hub lets you simply deploy giant language fashions (LLM) and combine them together with your purposes. OpenSearch Service is a completely managed service that makes it easy to deploy, scale, and function OpenSearch. OpenSearch Service lets you retailer vectors and different knowledge sorts in an index, and affords wealthy performance that lets you seek for paperwork utilizing vectors and measuring the semantical relatedness, which we use on this submit.
The tip purpose of this submit is to indicate how we will floor a set of photographs which might be semantically just like some textual content, be that an article or television synopsis.
The next screenshot exhibits an instance of taking a mini article as your search enter, moderately than utilizing key phrases, and with the ability to floor semantically comparable photographs.
Overview of answer
The answer is split into two most important sections. First, you extract label and superstar metadata from the pictures, utilizing Amazon Rekognition. You then generate an embedding of the metadata utilizing a LLM. You retailer the superstar names, and the embedding of the metadata in OpenSearch Service. Within the second most important part, you have got an API to question your OpenSearch Service index for photographs utilizing OpenSearch’s clever search capabilities to search out photographs which might be semantically just like your textual content.
This answer makes use of our event-driven providers Amazon EventBridge, AWS Step Functions, and AWS Lambda to orchestrate the method of extracting metadata from the pictures utilizing Amazon Rekognition. Amazon Rekognition will carry out two API calls to extract labels and recognized celebrities from the picture.
Amazon Rekognition celebrity detection API, returns plenty of components within the response. For this submit, you utilize the next:
- Name, Id, and Urls – The superstar title, a novel Amazon Rekognition ID, and listing of URLs such because the superstar’s IMDb or Wikipedia hyperlink for additional data.
- MatchConfidence – A match confidence rating that can be utilized to regulate API habits. We suggest making use of an appropriate threshold to this rating in your software to decide on your most popular working level. For instance, by setting a threshold of 99%, you’ll be able to eradicate extra false positives however might miss some potential matches.
In your second API name, Amazon Rekognition label detection API, returns plenty of components within the response. You utilize the next:
- Name – The title of the detected label
- Confidence – The extent of confidence within the label assigned to a detected object
A key idea in semantic search is embeddings. A phrase embedding is a numerical illustration of a phrase or group of phrases, within the type of a vector. When you have got many vectors, you’ll be able to measure the space between them, and vectors that are shut in distance are semantically comparable. Subsequently, in case you generate an embedding of your whole photographs’ metadata, after which generate an embedding of your textual content, be that an article or television synopsis for instance, utilizing the identical mannequin, you’ll be able to then discover photographs that are semantically just like your given textual content.
There are numerous fashions out there inside SageMaker JumpStart to generate embeddings. For this answer, you utilize GPT-J 6B Embedding from Hugging Face. It produces high-quality embeddings and has one of many high efficiency metrics in line with Hugging Face’s evaluation results. Amazon Bedrock is another choice, nonetheless in preview, the place you possibly can select Amazon Titan Textual content Embeddings mannequin to generate the embeddings.
You utilize the GPT-J pre-trained mannequin from SageMaker JumpStart to create an embedding of the picture metadata and retailer this as a k-NN vector in your OpenSearch Service index, together with the superstar title in one other area.
The second a part of the answer is to return the highest 10 photographs to the consumer which might be semantically just like their textual content, be this an article or television synopsis, together with any celebrities if current. When selecting a picture to accompany an article, you need the picture to resonate with the pertinent factors from the article. SageMaker JumpStart hosts many summarization fashions which might take a protracted physique of textual content and cut back it to the details from the unique. For the summarization mannequin, you utilize the AI21 Labs Summarize mannequin. This mannequin offers high-quality recaps of stories articles and the supply textual content can comprise roughly 10,000 phrases, which permits the consumer to summarize the complete article in a single go.
To detect if the textual content incorporates any names, doubtlessly recognized celebrities, you utilize Amazon Comprehend which might extract key entities from a textual content string. You then filter by the Individual entity, which you utilize as an enter search parameter.
Then you definitely take the summarized article and generate an embedding to make use of as one other enter search parameter. It’s vital to notice that you just use the identical mannequin deployed on the identical infrastructure to generate the embedding of the article as you probably did for the pictures. You then use Exact k-NN with scoring script in an effort to search by two fields: superstar names and the vector that captured the semantic data of the article. Consult with this submit, Amazon OpenSearch Service’s vector database capabilities explained, on the scalability of Rating script and the way this method on giant indexes might result in excessive latencies.
Walkthrough
The next diagram illustrates the answer structure.
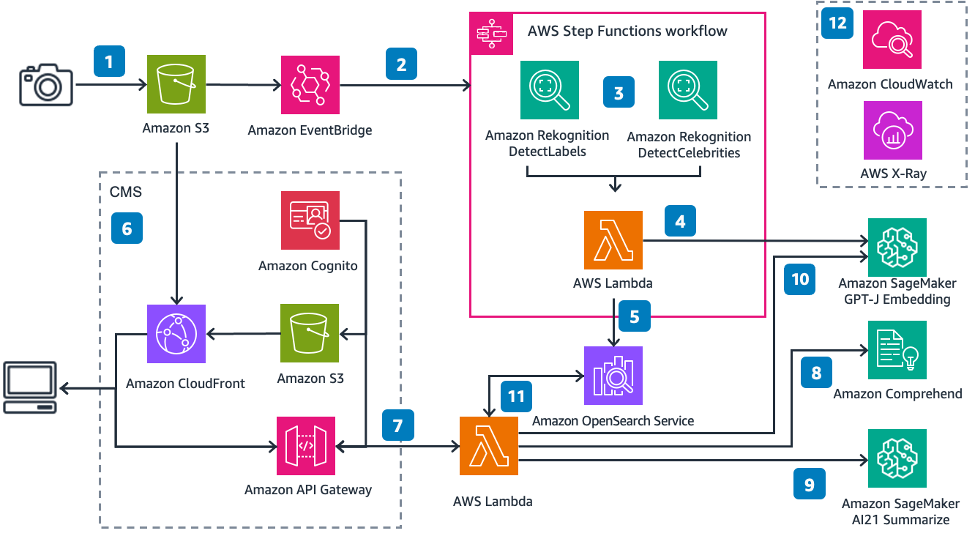
Following the numbered labels:
- You add a picture to an Amazon S3 bucket
- Amazon EventBridge listens to this occasion, after which triggers an AWS Step operate execution
- The Step Operate takes the picture enter, extracts the label and superstar metadata
- The AWS Lambda operate takes the picture metadata and generates an embedding
- The Lambda operate then inserts the superstar title (if current) and the embedding as a k-NN vector into an OpenSearch Service index
- Amazon S3 hosts a easy static web site, served by an Amazon CloudFront distribution. The front-end consumer interface (UI) lets you authenticate with the applying utilizing Amazon Cognito to seek for photographs
- You submit an article or some textual content by way of the UI
- One other Lambda operate calls Amazon Comprehend to detect any names within the textual content
- The operate then summarizes the textual content to get the pertinent factors from the article
- The operate generates an embedding of the summarized article
- The operate then searches OpenSearch Service picture index for any picture matching the superstar title and the k-nearest neighbors for the vector utilizing cosine similarity
- Amazon CloudWatch and AWS X-Ray offer you observability into the tip to finish workflow to provide you with a warning of any points.
Extract and retailer key picture metadata
The Amazon Rekognition DetectLabels and RecognizeCelebrities APIs provide the metadata out of your photographs—textual content labels you should utilize to type a sentence to generate an embedding from. The article offers you a textual content enter that you should utilize to generate an embedding.
Generate and retailer phrase embeddings
The next determine demonstrates plotting the vectors of our photographs in a 2-dimensional house, the place for visible assist, we have now categorized the embeddings by their main class.

You additionally generate an embedding of this newly written article, in an effort to search OpenSearch Service for the closest photographs to the article on this vector house. Utilizing the k-nearest neighbors (k-NN) algorithm, you outline what number of photographs to return in your outcomes.
Zoomed in to the previous determine, the vectors are ranked primarily based on their distance from the article after which return the Ok-nearest photographs, the place Ok is 10 on this instance.
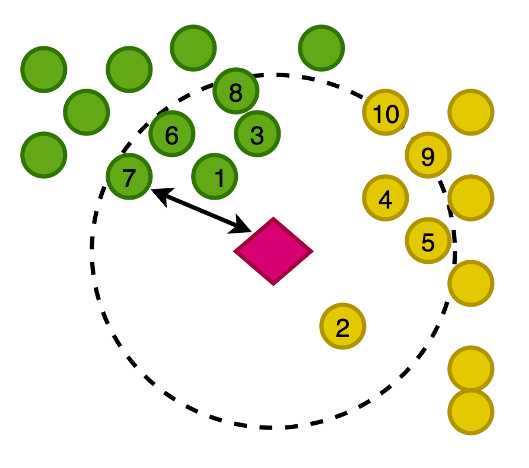
OpenSearch Service affords the aptitude to retailer giant vectors in an index, and likewise affords the performance to run queries in opposition to the index utilizing k-NN, such that you may question with a vector to return the k-nearest paperwork which have vectors in shut distance utilizing varied measurements. For this instance, we use cosine similarity.
Detect names within the article
You utilize Amazon Comprehend, an AI pure language processing (NLP) service, to extract key entities from the article. On this instance, you utilize Amazon Comprehend to extract entities and filter by the entity Individual, which returns any names that Amazon Comprehend can discover within the journalist story, with only a few strains of code:
On this instance, you add a picture to Amazon Simple Storage Service (Amazon S3), which triggers a workflow the place you might be extracting metadata from the picture together with labels and any celebrities. You then remodel that extracted metadata into an embedding and retailer all of this knowledge in OpenSearch Service.
Summarize the article and generate an embedding
Summarizing the article is a vital step to make it possible for the phrase embedding is capturing the pertinent factors of the article, and due to this fact returning photographs that resonate with the theme of the article.
AI21 Labs Summarize mannequin may be very easy to make use of with none immediate and only a few strains of code:
You then use the GPT-J mannequin to generate the embedding
You then search OpenSearch Service in your photographs
The next is an instance snippet of that question:
The structure incorporates a easy net app to signify a content material administration system (CMS).
For an instance article, we used the next enter:
“Werner Vogels liked travelling across the globe in his Toyota. We see his Toyota come up in lots of scenes as he drives to go and meet varied prospects of their dwelling cities.”
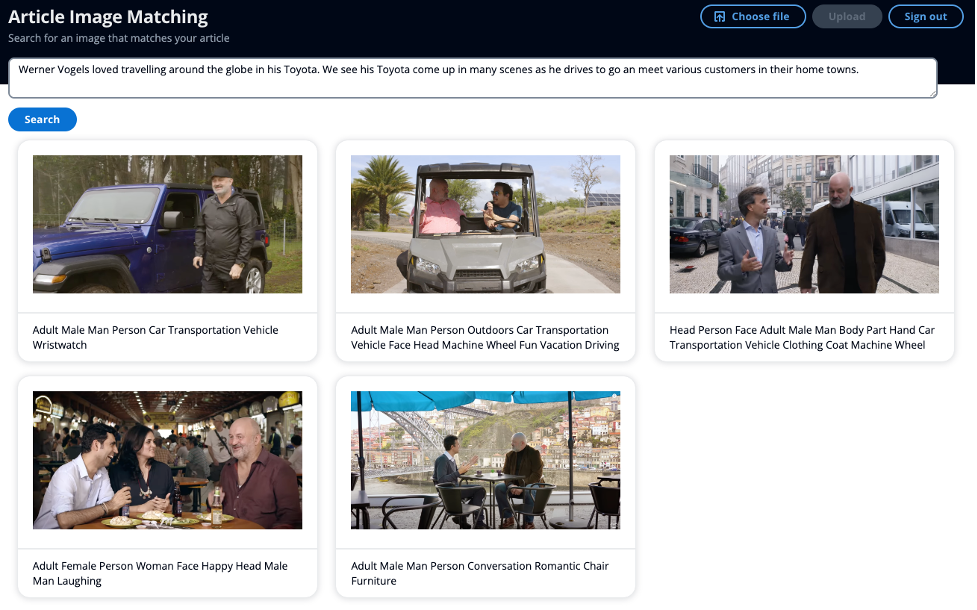
Not one of the photographs have any metadata with the phrase “Toyota,” however the semantics of the phrase “Toyota” are synonymous with automobiles and driving. Subsequently, with this instance, we will exhibit how we will transcend key phrase search and return photographs which might be semantically comparable. Within the above screenshot of the UI, the caption underneath the picture exhibits the metadata Amazon Rekognition extracted.
You would embody this answer in a larger workflow the place you utilize the metadata you already extracted out of your photographs to start out utilizing vector search together with different key phrases, corresponding to superstar names, to return the perfect resonating photographs and paperwork in your search question.
Conclusion
On this submit, we confirmed how you should utilize Amazon Rekognition, Amazon Comprehend, SageMaker, and OpenSearch Service to extract metadata out of your photographs after which use ML strategies to find them routinely utilizing superstar and semantic search. That is notably vital inside the publishing business, the place velocity issues in getting recent content material out rapidly and to a number of platforms.
For extra details about working with media property, consult with Media intelligence just got smarter with Media2Cloud 3.0.
Concerning the Writer
 Mark Watkins is a Options Architect inside the Media and Leisure workforce, supporting his prospects remedy many knowledge and ML issues. Away from skilled life, he loves spending time along with his household and watching his two little ones rising up.
Mark Watkins is a Options Architect inside the Media and Leisure workforce, supporting his prospects remedy many knowledge and ML issues. Away from skilled life, he loves spending time along with his household and watching his two little ones rising up.



