Basis mannequin with adaptive computation and dynamic read-and-write – Google Analysis Weblog

Adaptive computation refers back to the potential of a machine studying system to regulate its habits in response to modifications within the surroundings. Whereas standard neural networks have a hard and fast operate and computation capability, i.e., they spend the identical variety of FLOPs for processing completely different inputs, a mannequin with adaptive and dynamic computation modulates the computational finances it dedicates to processing every enter, relying on the complexity of the enter.
Adaptive computation in neural networks is interesting for 2 key causes. First, the mechanism that introduces adaptivity supplies an inductive bias that may play a key function in fixing some difficult duties. As an example, enabling completely different numbers of computational steps for various inputs may be essential in fixing arithmetic issues that require modeling hierarchies of various depths. Second, it offers practitioners the power to tune the price of inference by way of better flexibility supplied by dynamic computation, as these fashions may be adjusted to spend extra FLOPs processing a brand new enter.
Neural networks may be made adaptive by utilizing completely different features or computation budgets for numerous inputs. A deep neural community may be considered a operate that outputs a outcome primarily based on each the enter and its parameters. To implement adaptive operate sorts, a subset of parameters are selectively activated primarily based on the enter, a course of known as conditional computation. Adaptivity primarily based on the operate kind has been explored in research on mixture-of-experts, the place the sparsely activated parameters for every enter pattern are decided by way of routing.
One other space of analysis in adaptive computation entails dynamic computation budgets. In contrast to in normal neural networks, reminiscent of T5, GPT-3, PaLM, and ViT, whose computation finances is fastened for various samples, recent research has demonstrated that adaptive computation budgets can enhance efficiency on duties the place transformers fall brief. Many of those works obtain adaptivity by utilizing dynamic depth to allocate the computation finances. For instance, the Adaptive Computation Time (ACT) algorithm was proposed to offer an adaptive computational finances for recurrent neural networks. The Universal Transformer extends the ACT algorithm to transformers by making the computation finances depending on the variety of transformer layers used for every enter instance or token. Current research, like PonderNet, comply with an analogous method whereas enhancing the dynamic halting mechanisms.
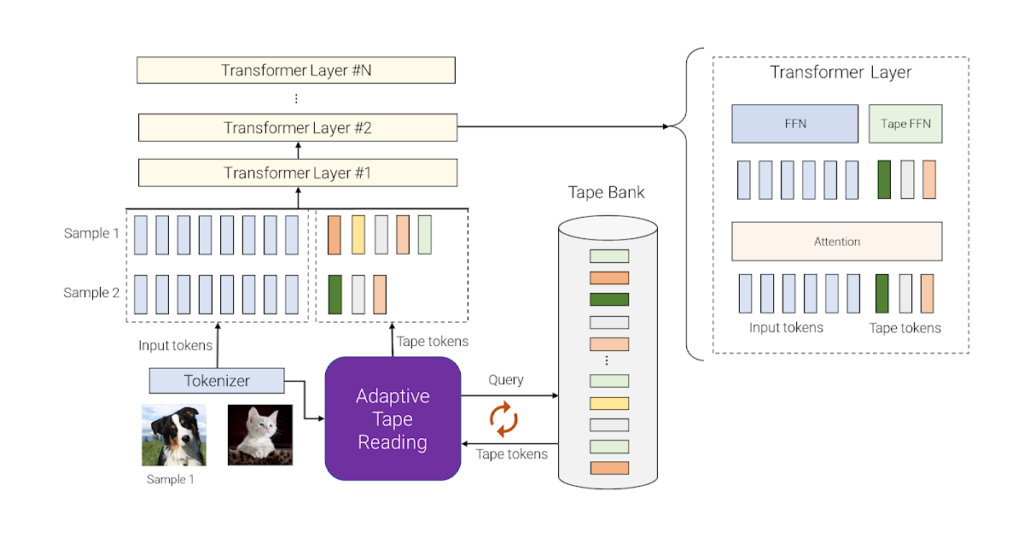
Within the paper “Adaptive Computation with Elastic Input Sequence”, we introduce a brand new mannequin that makes use of adaptive computation, referred to as AdaTape. This mannequin is a Transformer-based structure that makes use of a dynamic set of tokens to create elastic enter sequences, offering a singular perspective on adaptivity compared to earlier works. AdaTape makes use of an adaptive tape studying mechanism to find out a various variety of tape tokens which are added to every enter primarily based on enter’s complexity. AdaTape could be very easy to implement, supplies an efficient knob to extend the accuracy when wanted, however can be way more environment friendly in comparison with other adaptive baselines as a result of it instantly injects adaptivity into the enter sequence as an alternative of the mannequin depth. Lastly, Adatape gives higher efficiency on normal duties, like picture classification, in addition to algorithmic duties, whereas sustaining a good high quality and value tradeoff.
Adaptive computation transformer with elastic enter sequence
AdaTape makes use of each the adaptive operate sorts and a dynamic computation finances. Particularly, for a batch of enter sequences after tokenization (e.g., a linear projection of non-overlapping patches from a picture within the imaginative and prescient transformer), AdaTape makes use of a vector representing every enter to dynamically choose a variable-sized sequence of tape tokens.
AdaTape makes use of a financial institution of tokens, referred to as a “tape financial institution”, to retailer all of the candidate tape tokens that work together with the mannequin by way of the adaptive tape studying mechanism. We discover two completely different strategies for creating the tape financial institution: an input-driven financial institution and a learnable financial institution.
The final thought of the input-driven financial institution is to extract a financial institution of tokens from the enter whereas using a special method than the unique mannequin tokenizer for mapping the uncooked enter to a sequence of enter tokens. This permits dynamic, on-demand entry to data from the enter that’s obtained utilizing a special standpoint, e.g., a special picture decision or a special degree of abstraction.
In some instances, tokenization in a special degree of abstraction shouldn’t be doable, thus an input-driven tape financial institution shouldn’t be possible, reminiscent of when it is tough to additional cut up every node in a graph transformer. To deal with this situation, AdaTape gives a extra common method for producing the tape financial institution by utilizing a set of trainable vectors as tape tokens. This method is known as the learnable financial institution and may be seen as an embedding layer the place the mannequin can dynamically retrieve tokens primarily based on the complexity of the enter instance. The learnable financial institution allows AdaTape to generate a extra versatile tape financial institution, offering it with the power to dynamically modify its computation finances primarily based on the complexity of every enter instance, e.g., extra complicated examples retrieve extra tokens from the financial institution, which let the mannequin not solely use the information saved within the financial institution, but in addition spend extra FLOPs processing it, for the reason that enter is now bigger.
Lastly, the chosen tape tokens are appended to the unique enter and fed to the next transformer layers. For every transformer layer, the identical multi-head consideration is used throughout all enter and tape tokens. Nonetheless, two completely different feed-forward networks (FFN) are used: one for all tokens from the unique enter and the opposite for all tape tokens. We noticed barely higher high quality by utilizing separate feed-forward networks for enter and tape tokens.
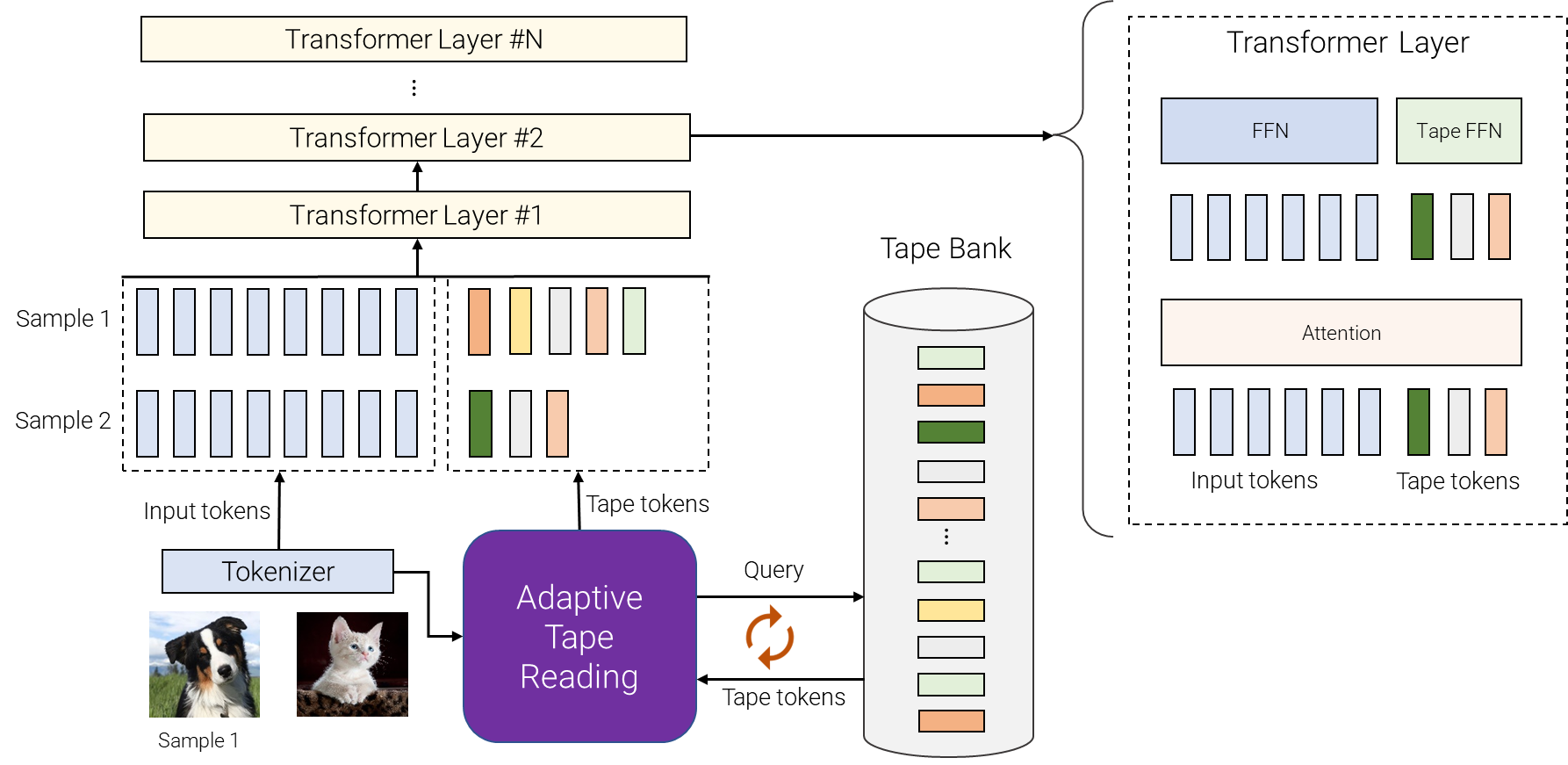 |
| An outline of AdaTape. For various samples, we decide a variable variety of completely different tokens from the tape financial institution. The tape financial institution may be pushed from enter, e.g., by extracting some additional fine-grained data or it may be a set of trainable vectors. Adaptive tape studying is used to recursively choose completely different sequences of tape tokens, with variable lengths, for various inputs. These tokens are then merely appended to inputs and fed to the transformer encoder. |
AdaTape supplies useful inductive bias
We consider AdaTape on parity, a really difficult activity for the usual Transformer, to review the impact of inductive biases in AdaTape. With the parity activity, given a sequence 1s, 0s, and -1s, the mannequin has to foretell the evenness or oddness of the variety of 1s within the sequence. Parity is the only non-counter-free or periodic regular language, however maybe surprisingly, the duty is unsolvable by the usual Transformer.
 |
| Analysis on the parity activity. The usual Transformer and Common Transformer had been unable to carry out this activity, each exhibiting efficiency on the degree of a random guessing baseline. |
Regardless of being evaluated on brief, easy sequences, each the usual Transformer and Common Transformers had been unable to carry out the parity activity as they’re unable to take care of a counter inside the mannequin. Nonetheless, AdaTape outperforms all baselines, because it incorporates a light-weight recurrence inside its enter choice mechanism, offering an inductive bias that allows the implicit upkeep of a counter, which isn’t doable in normal Transformers.
Analysis on picture classification
We additionally consider AdaTape on the picture classification activity. To take action, we skilled AdaTape on ImageNet-1K from scratch. The determine under exhibits the accuracy of AdaTape and the baseline strategies, together with A-ViT, and the Common Transformer ViT (UViT and U2T) versus their pace (measured as variety of photographs, processed by every code, per second). By way of high quality and value tradeoff, AdaTape performs a lot better than the choice adaptive transformer baselines. By way of effectivity, bigger AdaTape fashions (when it comes to parameter rely) are quicker than smaller baselines. Such outcomes are according to the discovering from previous work that exhibits that the adaptive mannequin depth architectures should not nicely suited for a lot of accelerators, just like the TPU.
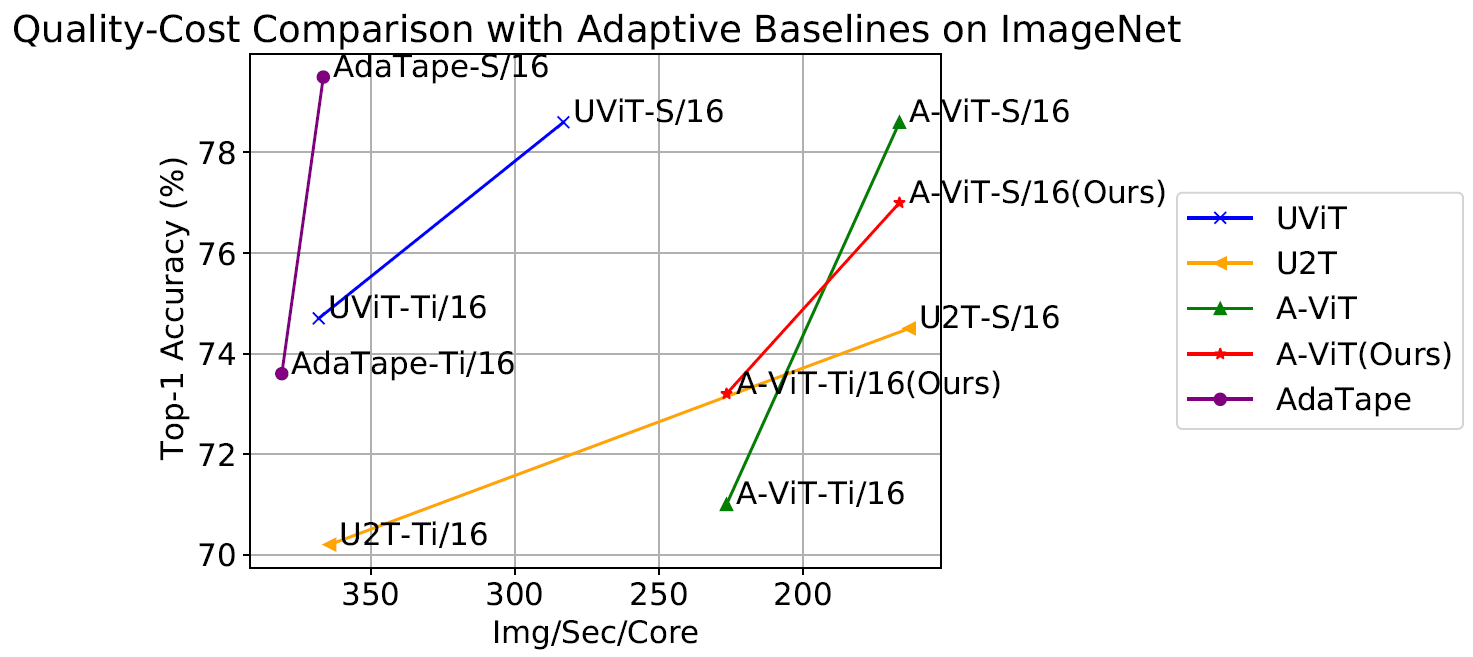 |
| We consider AdaTape by coaching on ImageNet from scratch. For A-ViT, we not solely report their outcomes from the paper but in addition re-implement A-ViT by coaching from scratch, i.e., A-ViT(Ours). |
A research of AdaTape’s habits
Along with its efficiency on the parity activity and ImageNet-1K, we additionally evaluated the token choice habits of AdaTape with an input-driven financial institution on the JFT-300M validation set. To raised perceive the mannequin’s habits, we visualized the token choice outcomes on the input-driven financial institution as heatmaps, the place lighter colours imply that place is extra continuously chosen. The heatmaps reveal that AdaTape extra continuously picks the central patches. This aligns with our prior information, as central patches are usually extra informative — particularly within the context of datasets with pure photographs, the place the principle object is in the course of the picture. This outcome highlights the intelligence of AdaTape, as it may well successfully determine and prioritize extra informative patches to enhance its efficiency.
 |
| We visualize the tape token choice heatmap of AdaTape-B/32 (left) and AdaTape-B/16 (proper). The warmer / lighter coloration means the patch at this place is extra continuously chosen. |
Conclusion
AdaTape is characterised by elastic sequence lengths generated by the adaptive tape studying mechanism. This additionally introduces a brand new inductive bias that allows AdaTape to have the potential to resolve duties which are difficult for each normal transformers and current adaptive transformers. By conducting complete experiments on picture recognition benchmarks, we show that AdaTape outperforms normal transformers and adaptive structure transformers when computation is held fixed.
Acknowledgments
One of many authors of this put up, Mostafa Dehghani, is now at Google DeepMind.





