Autonomous visible data in search of with massive language fashions – Google Analysis Weblog
There was nice progress in direction of adapting massive language fashions (LLMs) to accommodate multimodal inputs for duties together with image captioning, visual question answering (VQA), and open vocabulary recognition. Regardless of such achievements, present state-of-the-art visible language fashions (VLMs) carry out inadequately on visible data in search of datasets, akin to Infoseek and OK-VQA, the place exterior information is required to reply the questions.
 |
| Examples of visible data in search of queries the place exterior information is required to reply the query. Pictures are taken from the OK-VQA dataset. |
In “AVIS: Autonomous Visual Information Seeking with Large Language Models”, we introduce a novel technique that achieves state-of-the-art outcomes on visible data in search of duties. Our technique integrates LLMs with three varieties of instruments: (i) laptop imaginative and prescient instruments for extracting visible data from photographs, (ii) an internet search software for retrieving open world information and info, and (iii) a picture search software to glean related data from metadata related to visually related photographs. AVIS employs an LLM-powered planner to decide on instruments and queries at every step. It additionally makes use of an LLM-powered reasoner to investigate software outputs and extract key data. A working reminiscence element retains data all through the method.
 |
| An instance of AVIS’s generated workflow for answering a difficult visible data in search of query. The enter picture is taken from the Infoseek dataset. |
Comparability to earlier work
Current research (e.g., Chameleon, ViperGPT and MM-ReAct) explored including instruments to LLMs for multimodal inputs. These methods observe a two-stage course of: planning (breaking down questions into structured applications or directions) and execution (utilizing instruments to assemble data). Regardless of success in fundamental duties, this strategy typically falters in complicated real-world situations.
There has additionally been a surge of curiosity in making use of LLMs as autonomous brokers (e.g., WebGPT and ReAct). These brokers work together with their atmosphere, adapt based mostly on real-time suggestions, and obtain objectives. Nevertheless, these strategies don’t prohibit the instruments that may be invoked at every stage, resulting in an immense search area. Consequently, even essentially the most superior LLMs at present can fall into infinite loops or propagate errors. AVIS tackles this by way of guided LLM use, influenced by human selections from a person examine.
Informing LLM choice making with a person examine
Most of the visible questions in datasets akin to Infoseek and OK-VQA pose a problem even for people, typically requiring the help of varied instruments and APIs. An instance query from the OK-VQA dataset is proven beneath. We carried out a person examine to know human decision-making when utilizing exterior instruments.
 |
| We carried out a person examine to know human decision-making when utilizing exterior instruments. Picture is taken from the OK-VQA dataset. |
The customers had been outfitted with an similar set of instruments as our technique, together with PALI, PaLM, and web search. They obtained enter photographs, questions, detected object crops, and buttons linked to picture search outcomes. These buttons supplied various details about the detected object crops, akin to information graph entities, related picture captions, associated product titles, and similar picture captions.
We report person actions and outputs and use it as a information for our system in two key methods. First, we assemble a transition graph (proven beneath) by analyzing the sequence of choices made by customers. This graph defines distinct states and restricts the obtainable set of actions at every state. For instance, at the beginning state, the system can take solely certainly one of these three actions: PALI caption, PALI VQA, or object detection. Second, we use the examples of human decision-making to information our planner and reasoner with related contextual cases to boost the efficiency and effectiveness of our system.
 |
| AVIS transition graph. |
Normal framework
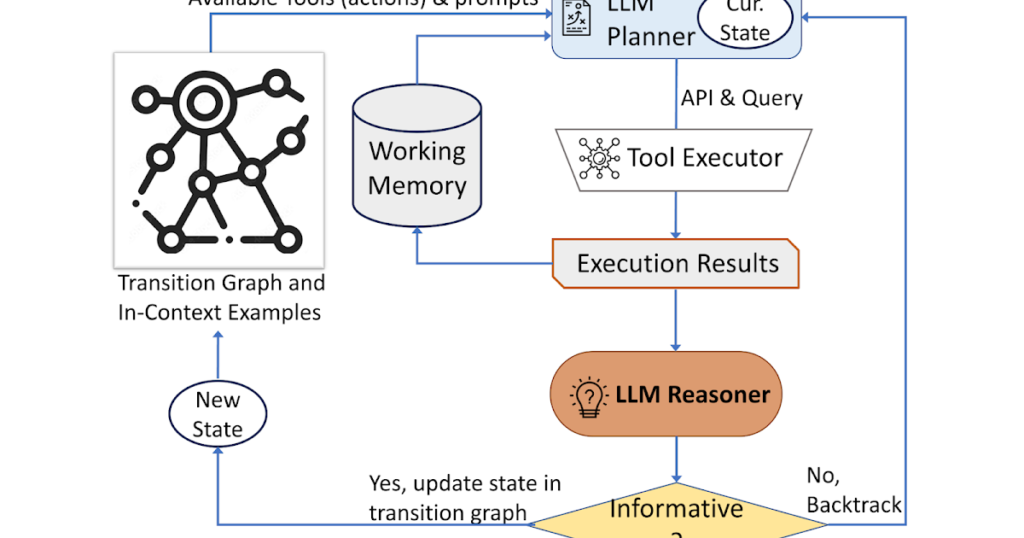
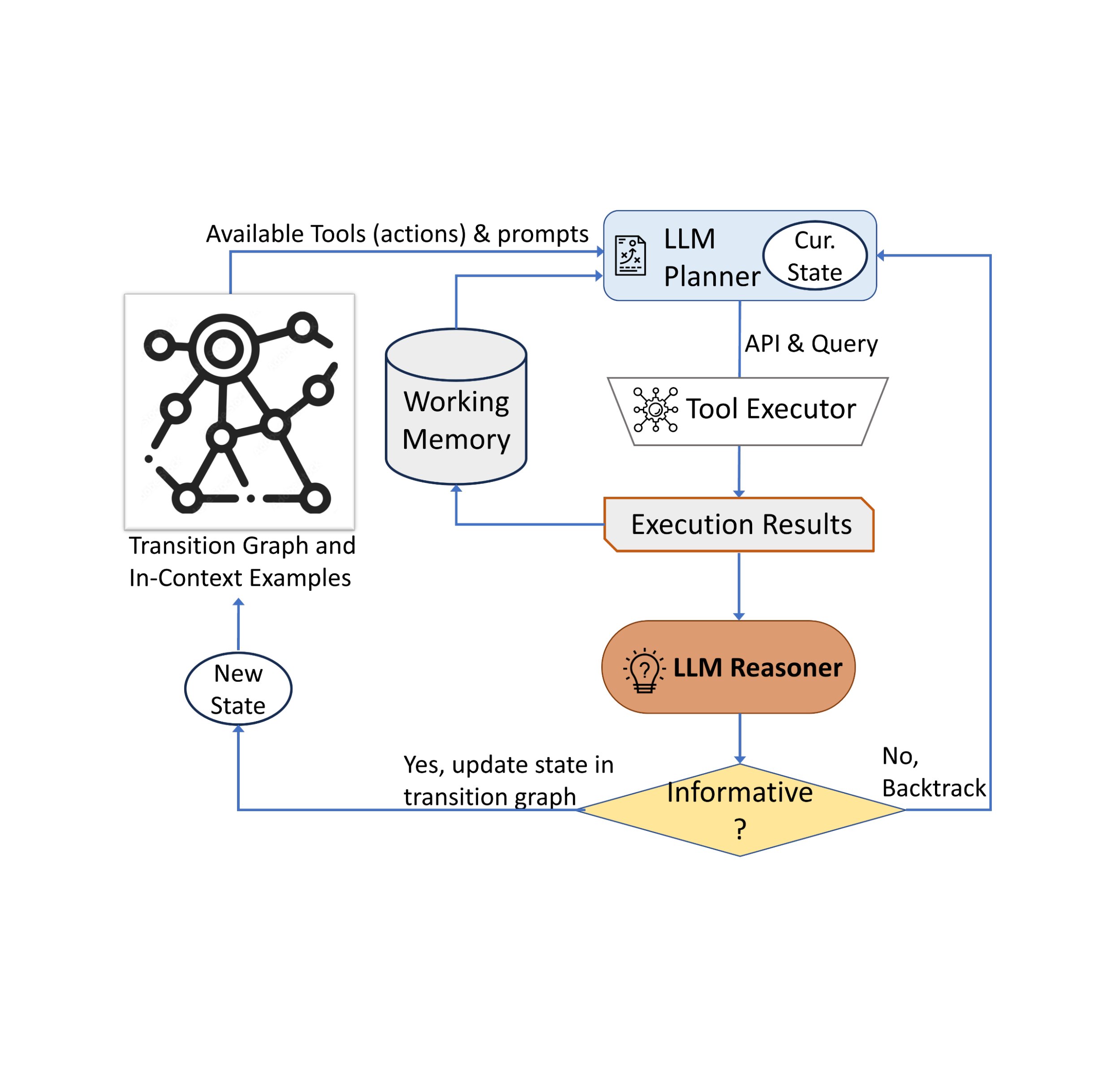
Our strategy employs a dynamic decision-making technique designed to reply to visible information-seeking queries. Our system has three main parts. First, we’ve got a planner to find out the following motion, together with the suitable API name and the question it must course of. Second, we’ve got a working reminiscence that retains details about the outcomes obtained from API executions. Final, we’ve got a reasoner, whose function is to course of the outputs from the API calls. It determines whether or not the obtained data is enough to provide the ultimate response, or if further knowledge retrieval is required.
The planner undertakes a collection of steps every time a choice is required concerning which software to make use of and what question to ship to it. Based mostly on the current state, the planner gives a variety of potential subsequent actions. The potential motion area could also be so massive that it makes the search area intractable. To deal with this challenge, the planner refers back to the transition graph to get rid of irrelevant actions. The planner additionally excludes the actions which have already been taken earlier than and are saved within the working reminiscence.
Subsequent, the planner collects a set of related in-context examples which can be assembled from the selections beforehand made by people throughout the person examine. With these examples and the working reminiscence that holds knowledge collected from previous software interactions, the planner formulates a immediate. The immediate is then despatched to the LLM, which returns a structured reply, figuring out the subsequent software to be activated and the question to be dispatched to it. This design permits the planner to be invoked a number of occasions all through the method, thereby facilitating dynamic decision-making that step by step results in answering the enter question.
We make use of a reasoner to investigate the output of the software execution, extract the helpful data and determine into which class the software output falls: informative, uninformative, or ultimate reply. Our technique makes use of the LLM with acceptable prompting and in-context examples to carry out the reasoning. If the reasoner concludes that it’s prepared to offer a solution, it’s going to output the ultimate response, thus concluding the duty. If it determines that the software output is uninformative, it’s going to revert again to the planner to pick one other motion based mostly on the present state. If it finds the software output to be helpful, it’s going to modify the state and switch management again to the planner to make a brand new choice on the new state.
 |
| AVIS employs a dynamic decision-making technique to reply to visible information-seeking queries. |
Outcomes
We consider AVIS on Infoseek and OK-VQA datasets. As proven beneath, even strong visual-language fashions, akin to OFA and PaLI, fail to yield excessive accuracy when fine-tuned on Infoseek. Our strategy (AVIS), with out fine-tuning, achieves 50.7% accuracy on the unseen entity cut up of this dataset.
 |
| AVIS visible query answering outcomes on Infoseek dataset. AVIS achieves greater accuracy compared to earlier baselines based mostly on PaLI, PaLM and OFA. |
Our outcomes on the OK-VQA dataset are proven beneath. AVIS with few-shot in-context examples achieves an accuracy of 60.2%, greater than a lot of the earlier works. AVIS achieves decrease however comparable accuracy compared to the PALI mannequin fine-tuned on OK-VQA. This distinction, in comparison with Infoseek the place AVIS outperforms fine-tuned PALI, is because of the truth that most question-answer examples in OK-VQA depend on widespread sense information fairly than on fine-grained information. Subsequently, PaLI is ready to encode such generic information within the mannequin parameters and doesn’t require exterior information.
 |
| Visible query answering outcomes on A-OKVQA. AVIS achieves greater accuracy compared to earlier works that use few-shot or zero-shot studying, together with Flamingo, PaLI and ViperGPT. AVIS additionally achieves greater accuracy than a lot of the earlier works which can be fine-tuned on OK-VQA dataset, together with REVEAL, ReVIVE, KAT and KRISP, and achieves outcomes which can be near the fine-tuned PaLI mannequin. |
Conclusion
We current a novel strategy that equips LLMs with the flexibility to make use of a wide range of instruments for answering knowledge-intensive visible questions. Our methodology, anchored in human decision-making knowledge collected from a person examine, employs a structured framework that makes use of an LLM-powered planner to dynamically determine on software choice and question formation. An LLM-powered reasoner is tasked with processing and extracting key data from the output of the chosen software. Our technique iteratively employs the planner and reasoner to leverage completely different instruments till all mandatory data required to reply the visible query is amassed.
Acknowledgements
This analysis was carried out by Ziniu Hu, Ahmet Iscen, Chen Solar, Kai-Wei Chang, Yizhou Solar, David A. Ross, Cordelia Schmid and Alireza Fathi.



