An Accessible Derivation of Linear Regression | by William Caicedo-Torres, PhD | Aug, 2023
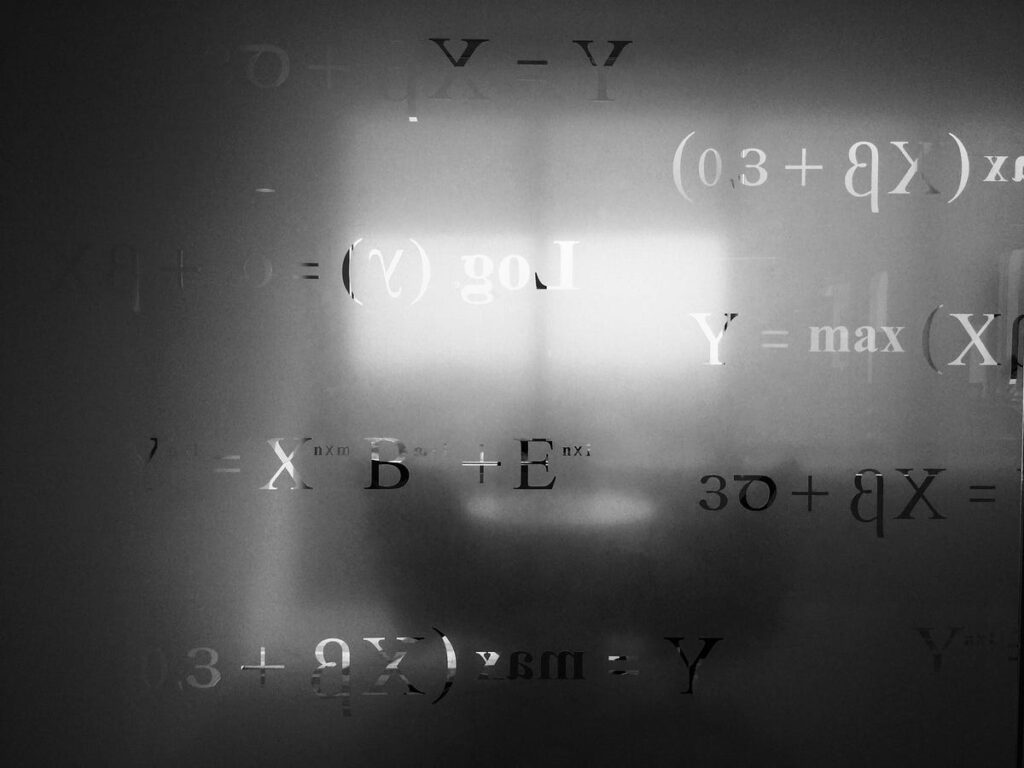
The mathematics behind the mannequin, from additive assumptions to pseudoinverse matrices
Technical disclaimer: It’s attainable to derive a mannequin with out normality assumptions. We’ll go down this route as a result of it’s simple sufficient to know and by assuming normality of the mannequin’s output, we are able to purpose concerning the uncertainty of our predictions.
This put up is meant for people who find themselves already conscious of what linear regression is (and perhaps have used it a couple of times) and desire a extra principled understanding of the maths behind it.
Some background in primary chance (chance distributions, joint chance, mutually unique occasions), linear algebra, and stats might be required to benefit from what follows. With out additional ado, right here we go:
The machine studying world is filled with superb connections: the exponential household, regularization and prior beliefs, KNN and SVMs, Most Probability and Data Idea — it’s all related! (I really like Dark). This time we’ll focus on the right way to derive one other one of many members of the exponential household: the Linear Regression mannequin, and within the course of we’ll see that the Imply Squared Error loss is theoretically properly motivated. As with every regression mannequin, we’ll be capable to use it to foretell numerical, steady targets. It’s a easy but highly effective mannequin that occurs to be one of many workhorses of statistical inference and experimental design. Nevertheless we might be involved solely with its utilization as a predictive device. No pesky inference (and God forbid, causal) stuff right here.
Alright, allow us to start. We need to predict one thing based mostly on one thing else. We’ll name the predicted factor y and the one thing else x. As a concrete instance, I supply the next toy scenario: You’re a credit score analyst working in a financial institution and also you’re desirous about routinely discovering out the appropriate credit score restrict for a financial institution buyer. You additionally occur to have a dataset pertaining to previous shoppers and what credit score restrict (the predicted factor) was authorised for them, along with a few of their options resembling demographic information, previous credit score efficiency, earnings, and many others. (the one thing else).
So we’ve a fantastic concept and write down a mannequin that explains the credit score restrict when it comes to these options obtainable to you, with the mannequin’s important assumption being that every function contributes one thing to the noticed output in an additive method. Because the credit score stuff was only a motivating (and contrived) instance, let’s return to our pure math world of spherical cows, with our mannequin turning into one thing like this:

We nonetheless have the anticipated stuff (y) and the one thing else we use to foretell it (x). We concede that some kind of noise is unavoidable (be it by advantage of imperfect measuring or our personal blindness) and the perfect we are able to do is to imagine that the mannequin behind the information we observe is stochastic. The consequence of that is that we’d see barely totally different outputs for a similar enter, so as an alternative of neat level estimates we’re “caught” with a chance distribution over the outputs (y) conditioned on the inputs (x):

Each knowledge level in y is changed by somewhat bell curve, whose imply lies within the noticed values of y, and has some variance which we don’t care about in the mean time. Then our little mannequin will take the place of the distribution imply.
Assuming all these bell curves are literally regular distributions and their means (knowledge factors in y) are unbiased from one another, the (joint) chance of observing the dataset is

Logarithms and a few algebra to the rescue:

Logarithms are cool, aren’t they? Logs rework multiplication into sum, division into subtraction, and powers into multiplication. Fairly helpful from each algebraic and numerical standpoints. Eliminating fixed stuff, which is irrelevant on this case, we arrive to the next most probability downside:

Effectively, that’s the identical as

The expression we’re about to reduce is one thing very near the well-known Imply Sq. Error loss. In actual fact, for optimization functions they’re equal.
So what now? This minimization downside will be solved precisely utilizing derivatives. We’ll reap the benefits of the truth that the loss is quadratic, which implies convex, which implies one international minima; permitting us to take its by-product, set it to zero and clear up for theta. Doing this we’ll discover the worth of the parameters theta that makes the by-product of the loss zero. And why? as a result of it’s exactly on the level the place the by-product is zero, that the loss is at its minimal.
To make all the things considerably easier, let’s categorical the loss in vector notation:

Right here, X is an NxM matrix representing our complete dataset of N examples and M options and y is a vector containing the anticipated responses per coaching instance. Taking the by-product and setting it to zero we get

There you’ve it, the answer to the optimization downside we’ve solid our unique machine studying downside into. Should you go forward and plug these parameter values into your mannequin, you’ll have a educated ML mannequin able to be evaluated utilizing some holdout dataset (or perhaps by way of cross-validation).
Should you suppose that remaining expression seems an terrible lot like the answer of a linear system,

it’s as a result of it does. The additional stuff comes from the truth that for our downside to be equal to a vanilla linear system, we’d want an equal variety of options and coaching examples so we are able to invert X. Since that’s seldom the case we are able to solely hope for a “greatest match” answer — in some sense of greatest — resorting to the Moore-Penrose Pseudoinverse of X, which is a generalization of the nice ol’ inverse matrix. The related wikipedia entry makes for a enjoyable studying.




