Construct and practice laptop imaginative and prescient fashions to detect automotive positions in pictures utilizing Amazon SageMaker and Amazon Rekognition
Laptop imaginative and prescient (CV) is likely one of the commonest functions of machine studying (ML) and deep studying. Use circumstances vary from self-driving vehicles, content material moderation on social media platforms, most cancers detection, and automatic defect detection. Amazon Rekognition is a totally managed service that may carry out CV duties like object detection, video section detection, content material moderation, and extra to extract insights from knowledge with out the necessity of any prior ML expertise. In some circumstances, a extra customized resolution may be wanted together with the service to unravel a really particular downside.
On this put up, we deal with areas the place CV may be utilized to make use of circumstances the place the pose of objects, their place, and orientation is necessary. One such use case could be customer-facing cellular functions the place a picture add is required. It may be for compliance causes or to supply a constant person expertise and enhance engagement. For instance, on on-line buying platforms, the angle at which merchandise are proven in pictures has an impact on the speed of shopping for this product. One such case is to detect the place of a automotive. We show how one can mix well-known ML options with postprocessing to deal with this downside on the AWS Cloud.
We use deep studying fashions to unravel this downside. Coaching ML algorithms for pose estimation requires lots of experience and customized coaching knowledge. Each necessities are laborious and dear to acquire. Subsequently, we current two choices: one which doesn’t require any ML experience and makes use of Amazon Rekognition, and one other that makes use of Amazon SageMaker to coach and deploy a customized ML mannequin. Within the first choice, we use Amazon Rekognition to detect the wheels of the automotive. We then infer the automotive orientation from the wheel positions utilizing a rule-based system. Within the second choice, we detect the wheels and different automotive elements utilizing the Detectron mannequin. These are once more used to deduce the automotive place with rule-based code. The second choice requires ML expertise however can also be extra customizable. It may be used for additional postprocessing on the picture, for instance, to crop out the entire automotive. Each of the choices may be educated on publicly obtainable datasets. Lastly, we present how one can combine this automotive pose detection resolution into your current net software utilizing companies like Amazon API Gateway and AWS Amplify.
Answer overview
The next diagram illustrates the answer structure.

The answer consists of a mock net software in Amplify the place a person can add a picture and invoke both the Amazon Rekognition mannequin or the customized Detectron mannequin to detect the place of the automotive. For every choice, we host an AWS Lambda perform behind an API Gateway that’s uncovered to our mock software. We configured our Lambda perform to run with both the Detectron mannequin educated in SageMaker or Amazon Rekognition.
Conditions
For this walkthrough, you need to have the next stipulations:
Create a serverless app utilizing Amazon Rekognition
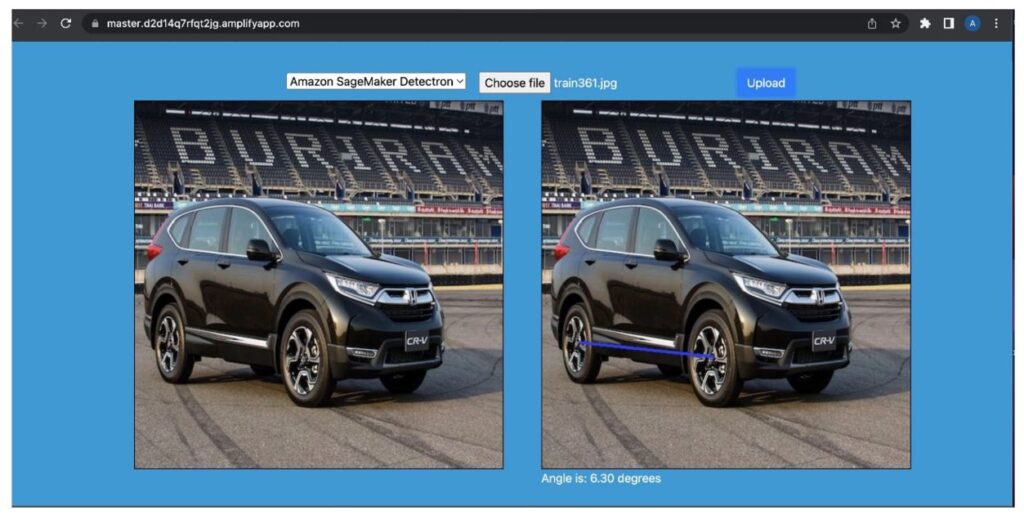
Our first choice demonstrates how one can detect automotive orientations in pictures utilizing Amazon Rekognition. The thought is to make use of Amazon Rekognition to detect the placement of the automotive and its wheels after which do postprocessing to derive the orientation of the automotive from this data. The entire resolution is deployed utilizing Lambda as proven within the Github repository. This folder accommodates two primary recordsdata: a Dockerfile that defines the Docker picture that can run in our Lambda perform, and the app.py file, which would be the primary entry level of the Lambda perform:
The Lambda perform expects an occasion that accommodates a header and physique, the place the physique ought to be the picture wanted to be labeled as base64 decoded object. Given the picture, the Amazon Rekognition detect_labels perform is invoked from the Lambda perform utilizing Boto3. The perform returns a number of labels for every object within the picture and bounding field particulars for the entire detected object labels as a part of the response, together with different data like confidence of the assigned label, the ancestor labels of the detected label, potential aliases for the label, and the classes the detected label belongs to. Primarily based on the labels returned by Amazon Rekognition, we run the perform label_image, which calculates the automotive angle from the detected wheels as follows:
Be aware that the applying requires that just one automotive is current within the picture and returns an error if that’s not the case. Nonetheless, the postprocessing may be tailored to supply extra granular orientation descriptions, cowl a number of vehicles, or calculate the orientation of extra complicated objects.
Enhance wheel detection
To additional enhance the accuracy of the wheel detection, you should utilize Amazon Rekognition Custom Labels. Much like fine-tuning utilizing SageMaker to coach and deploy a customized ML mannequin, you’ll be able to deliver your individual labeled knowledge in order that Amazon Rekognition can produce a customized picture evaluation mannequin for you in only a few hours. With Rekognition Customized Labels, you solely want a small set of coaching pictures which can be particular to your use case, on this case automotive pictures with particular angles, as a result of it makes use of the prevailing capabilities in Amazon Rekognition of being educated on tens of tens of millions of pictures throughout many classes. Rekognition Customized Labels may be built-in with only some clicks and small diversifications to the Lambda perform we use for the usual Amazon Rekognition resolution.
Prepare a mannequin utilizing a SageMaker coaching job
In our second choice, we practice a customized deep studying mannequin on SageMaker. We use the Detectron2 framework for the segmentation of automotive elements. These segments are then used to deduce the place of the automotive.
The Detectron2 framework is a library that gives state-of-the-art detection and segmentation algorithms. Detectron offers a wide range of Masks R-CNN fashions that have been educated on the well-known COCO (Frequent objects in Context) dataset. To construct our automotive objects detection mannequin, we use switch studying to fine-tune a pretrained Masks R-CNN mannequin on the car parts segmentation dataset. This dataset permits us to coach a mannequin that may detect wheels but additionally different automotive elements. This extra data may be additional used within the automotive angle computations relative to the picture.
The dataset accommodates annotated knowledge of automotive elements for use for object detection and semantic segmentation duties: roughly 500 pictures of sedans, pickups, and sports activities utility autos (SUVs), taken in a number of views (entrance, again, and aspect views). Every picture is annotated by 18 occasion masks and bounding bins representing the totally different elements of a automotive like wheels, mirrors, lights, and back and front glass. We modified the bottom annotations of the wheels such that every wheel is taken into account a person object as an alternative of contemplating all of the obtainable wheels within the picture as one object.
We use Amazon Simple Storage Service (Amazon S3) to retailer the dataset used for coaching the Detectron mannequin together with the educated mannequin artifacts. Furthermore, the Docker container that runs within the Lambda perform is saved in Amazon Elastic Container Registry (Amazon ECR). The Docker container within the Lambda perform is required to incorporate the required libraries and dependencies for working the code. We may alternatively use Lambda layers, but it surely’s restricted to an unzipped deployment packaged dimension quota of 250 MB and a most of 5 layers may be added to a Lambda perform.
Our resolution is constructed on SageMaker: we lengthen prebuilt SageMaker Docker containers for PyTorch to run our customized PyTorch training code. Subsequent, we use the SageMaker Python SDK to wrap the coaching picture right into a SageMaker PyTorch estimator, as proven within the following code snippets:
Lastly, we begin the coaching job by calling the match() perform on the created PyTorch estimator. When the coaching is completed, the educated mannequin artifact is saved within the session bucket in Amazon S3 for use for the inference pipeline.
Deploy the mannequin utilizing SageMaker and inference pipelines
We additionally use SageMaker to host the inference endpoint that runs our customized Detectron mannequin. The total infrastructure used to deploy our resolution is provisioned utilizing the AWS CDK. We are able to host our customized mannequin via a SageMaker real-time endpoint by calling deploy on the PyTorch estimator. That is the second time we lengthen a prebuilt SageMaker PyTorch container to incorporate PyTorch Detectron. We use it to run the inference script and host our educated PyTorch mannequin as follows:
Be aware that we used an ml.g4dn.xlarge GPU for deployment as a result of it’s the smallest GPU obtainable and adequate for this demo. Two elements must be configured in our inference script: mannequin loading and mannequin serving. The perform model_fn() is used to load the educated mannequin that’s a part of the hosted Docker container and may also be present in Amazon S3 and return a mannequin object that can be utilized for mannequin serving as follows:
The perform predict_fn() performs the prediction and returns the end result. In addition to utilizing our educated mannequin, we use a pretrained model of the Masks R-CNN mannequin educated on the COCO dataset to extract the principle automotive within the picture. That is an additional postprocessing step to cope with pictures the place a couple of automotive exists. See the next code:
Much like the Amazon Rekognition resolution, the bounding bins predicted for the wheel class are filtered from the detection outputs and provided to the postprocessing module to evaluate the automotive place relative to the output.
Lastly, we additionally improved the postprocessing for the Detectron resolution. It additionally makes use of the segments of various automotive elements to deduce the answer. For instance, at any time when a entrance bumper is detected, however no again bumper, it’s assumed that we’ve a entrance view of the automotive and the corresponding angle is calculated.
Join your resolution to the net software
The steps to attach the mannequin endpoints to Amplify are as follows:
- Clone the applying repository that the AWS CDK stack created, named
car-angle-detection-website-repo. Ensure you are in search of it within the Area you used for deployment. - Copy the API Gateway endpoints for every of the deployed Lambda features into the
index.htmlfile within the previous repository (there are placeholders the place the endpoint must be positioned). The next code is an instance of what this part of the .html file appears like:
- Save the HTML file and push the code change to the distant primary department.
This can replace the HTML file within the deployment. The applying is now prepared to make use of.
- Navigate to the Amplify console and find the mission you created.
The applying URL can be seen after the deployment is full.
- Navigate to the URL and have enjoyable with the UI.

Conclusion
Congratulations! We have now deployed an entire serverless structure through which we used Amazon Rekognition, but additionally gave an choice to your personal customized mannequin, with this instance obtainable on GitHub. In the event you don’t have ML experience in your staff or sufficient customized knowledge to coach a mannequin, you may choose the choice that makes use of Amazon Rekognition. In order for you extra management over your mannequin, want to customise it additional, and have sufficient knowledge, you’ll be able to select the SageMaker resolution. If in case you have a staff of information scientists, they could additionally wish to improve the fashions additional and decide a extra customized and versatile choice. You may put the Lambda perform and the API Gateway behind your net software utilizing both of the 2 choices. You can too use this strategy for a special use case for which you may wish to adapt the code.
The benefit of this serverless structure is that the constructing blocks are fully exchangeable. The alternatives are nearly limitless. So, get began at this time!
As all the time, AWS welcomes suggestions. Please submit any feedback or questions.
In regards to the Authors
 Michael Wallner is a Senior Marketing consultant Information & AI with AWS Skilled Companies and is enthusiastic about enabling clients on their journey to grow to be data-driven and AWSome within the AWS cloud. On high, he likes considering large with clients to innovate and invent new concepts for them.
Michael Wallner is a Senior Marketing consultant Information & AI with AWS Skilled Companies and is enthusiastic about enabling clients on their journey to grow to be data-driven and AWSome within the AWS cloud. On high, he likes considering large with clients to innovate and invent new concepts for them.
 Aamna Najmi is a Information Scientist with AWS Skilled Companies. She is enthusiastic about serving to clients innovate with Large Information and Synthetic Intelligence applied sciences to faucet enterprise worth and insights from knowledge. She has expertise in engaged on knowledge platform and AI/ML tasks within the healthcare and life sciences vertical. In her spare time, she enjoys gardening and touring to new locations.
Aamna Najmi is a Information Scientist with AWS Skilled Companies. She is enthusiastic about serving to clients innovate with Large Information and Synthetic Intelligence applied sciences to faucet enterprise worth and insights from knowledge. She has expertise in engaged on knowledge platform and AI/ML tasks within the healthcare and life sciences vertical. In her spare time, she enjoys gardening and touring to new locations.
 David Sauerwein is a Senior Information Scientist at AWS Skilled Companies, the place he permits clients on their AI/ML journey on the AWS cloud. David focuses on digital twins, forecasting and quantum computation. He has a PhD in theoretical physics from the College of Innsbruck, Austria. He was additionally a doctoral and post-doctoral researcher on the Max-Planck-Institute for Quantum Optics in Germany. In his free time he likes to learn, ski and spend time together with his household.
David Sauerwein is a Senior Information Scientist at AWS Skilled Companies, the place he permits clients on their AI/ML journey on the AWS cloud. David focuses on digital twins, forecasting and quantum computation. He has a PhD in theoretical physics from the College of Innsbruck, Austria. He was additionally a doctoral and post-doctoral researcher on the Max-Planck-Institute for Quantum Optics in Germany. In his free time he likes to learn, ski and spend time together with his household.
 Srikrishna Chaitanya Konduru is a Senior Information Scientist with AWS Skilled companies. He helps clients in prototyping and operationalising their ML functions on AWS. Srikrishna focuses on laptop imaginative and prescient and NLP. He additionally leads ML platform design and use case identification initiatives for patrons throughout various business verticals. Srikrishna has an M.Sc in Biomedical Engineering from RWTH Aachen college, Germany, with a give attention to Medical Imaging.
Srikrishna Chaitanya Konduru is a Senior Information Scientist with AWS Skilled companies. He helps clients in prototyping and operationalising their ML functions on AWS. Srikrishna focuses on laptop imaginative and prescient and NLP. He additionally leads ML platform design and use case identification initiatives for patrons throughout various business verticals. Srikrishna has an M.Sc in Biomedical Engineering from RWTH Aachen college, Germany, with a give attention to Medical Imaging.
 Ahmed Mansour is a Information Scientist at AWS Skilled Companies. He present technical assist for patrons via their AI/ML journey on the AWS cloud. Ahmed focuses on functions of NLP to the protein area together with RL. He has a PhD in Engineering from the Technical College of Munich, Germany. In his free time he likes to go to the fitness center and play together with his children.
Ahmed Mansour is a Information Scientist at AWS Skilled Companies. He present technical assist for patrons via their AI/ML journey on the AWS cloud. Ahmed focuses on functions of NLP to the protein area together with RL. He has a PhD in Engineering from the Technical College of Munich, Germany. In his free time he likes to go to the fitness center and play together with his children.



