Use Steady Diffusion XL with Amazon SageMaker JumpStart in Amazon SageMaker Studio

Right this moment we’re excited to announce that Steady Diffusion XL 1.0 (SDXL 1.0) is obtainable for patrons by means of Amazon SageMaker JumpStart. SDXL 1.0 is the most recent picture era mannequin from Stability AI. SDXL 1.0 enhancements embrace native 1024-pixel picture era at a wide range of facet ratios. It’s designed for skilled use, and calibrated for high-resolution photorealistic photos. SDXL 1.0 affords a wide range of preset artwork kinds prepared to make use of in advertising and marketing, design, and picture era use circumstances throughout industries. You may simply check out these fashions and use them with SageMaker JumpStart, a machine studying (ML) hub that gives entry to algorithms, fashions, and ML options so you may shortly get began with ML.
On this submit, we stroll by means of easy methods to use SDXL 1.0 fashions by way of SageMaker JumpStart.
What’s Steady Diffusion XL 1.0 (SDXL 1.0)
SDXL 1.0 is the evolution of Steady Diffusion and the following frontier for generative AI for photos. SDXL is able to producing gorgeous photos with complicated ideas in numerous artwork kinds, together with photorealism, at high quality ranges that exceed the perfect picture fashions obtainable as we speak. Like the unique Steady Diffusion collection, SDXL is extremely customizable (when it comes to parameters) and might be deployed on Amazon SageMaker cases.
The next picture of a lion was generated utilizing SDXL 1.0 utilizing a easy immediate, which we discover later on this submit.

The SDXL 1.0 mannequin consists of the next highlights:
- Freedom of expression – Finest-in-class photorealism, in addition to a capability to generate high-quality artwork in just about any artwork type. Distinct photos are made with out having any specific really feel that’s imparted by the mannequin, guaranteeing absolute freedom of fashion.
- Creative intelligence – Finest-in-class capability to generate ideas which can be notoriously tough for picture fashions to render, similar to palms and textual content, or spatially organized objects and folks (for instance, a crimson field on prime of a blue field).
- Easier prompting – In contrast to different generative picture fashions, SDXL requires just a few phrases to create complicated, detailed, and aesthetically pleasing photos. No extra want for paragraphs of qualifiers.
- Extra correct – Prompting in SDXL shouldn’t be solely easy, however extra true to the intention of prompts. SDXL’s improved CLIP mannequin understands textual content so successfully that ideas like “The Purple Sq.” are understood to be completely different from “a crimson sq..” This accuracy permits way more to be carried out to get the right picture instantly from textual content, even earlier than utilizing the extra superior options or fine-tuning that Steady Diffusion is legendary for.
What’s SageMaker JumpStart
With SageMaker JumpStart, ML practitioners can select from a broad number of state-of-the-art fashions to be used circumstances similar to content material writing, picture era, code era, query answering, copywriting, summarization, classification, data retrieval, and extra. ML practitioners can deploy basis fashions to devoted SageMaker cases from a community remoted surroundings and customise fashions utilizing SageMaker for mannequin coaching and deployment. The SDXL mannequin is discoverable as we speak in Amazon SageMaker Studio and, as of this writing, is obtainable in us-east-1, us-east-2, us-west-2, eu-west-1, ap-northeast-1, and ap-southeast-2 Areas.
Resolution overview
On this submit, we show easy methods to deploy SDXL 1.0 to SageMaker and use it to generate photos utilizing each text-to-image and image-to-image prompts.
SageMaker Studio is a web-based built-in improvement surroundings (IDE) for ML that allows you to construct, prepare, debug, deploy, and monitor your ML fashions. For extra particulars on easy methods to get began and arrange SageMaker Studio, discuss with Amazon SageMaker Studio.
As soon as you’re within the SageMaker Studio UI, entry SageMaker JumpStart and seek for Steady Diffusion XL. Select the SDXL 1.0 mannequin card, which is able to open up an instance pocket book. This implies you may be solely be liable for compute prices. There is no such thing as a related mannequin price. Closed weight SDXL 1.0 affords SageMaker optimized scripts and container with quicker inference time and might be run on smaller occasion in comparison with the open weight SDXL 1.0. The instance pocket book will stroll you thru steps, however we additionally talk about easy methods to uncover and deploy the mannequin later on this submit.
Within the following sections, we present how you need to use SDXL 1.0 to create photorealistic photos with shorter prompts and generate textual content inside photos. Steady Diffusion XL 1.0 affords enhanced picture composition and face era with gorgeous visuals and real looking aesthetics.
Steady Diffusion XL 1.0 parameters
The next are the parameters utilized by SXDL 1.0:
- cfg_scale – How strictly the diffusion course of adheres to the immediate textual content.
- peak and width – The peak and width of picture in pixel.
- steps – The variety of diffusion steps to run.
- seed – Random noise seed. If a seed is offered, the ensuing generated picture might be deterministic.
- sampler – Which sampler to make use of for the diffusion course of to denoise our era with.
- text_prompts – An array of textual content prompts to make use of for era.
- weight – Gives every immediate a selected weight
For extra data, discuss with the Stability AI’s text to image documentation.
The next code is a pattern of the enter knowledge supplied with the immediate:
All examples on this submit are primarily based on the pattern pocket book for Stability Diffusion XL 1.0, which might be discovered on Stability AI’s GitHub repo.
Generate photos utilizing SDXL 1.0
Within the following examples, we deal with the capabilities of Stability Diffusion XL 1.0 fashions, together with superior photorealism, enhanced picture composition, and the flexibility to generate real looking faces. We additionally discover the considerably improved visible aesthetics, leading to visually interesting outputs. Moreover, we show using shorter prompts, enabling the creation of descriptive imagery with larger ease. Lastly, we illustrate how the textual content in photos is now extra legible, additional enriching the general high quality of the generated content material.
The next instance reveals utilizing a easy immediate to get detailed photos. Utilizing just a few phrases within the immediate, it was capable of create a posh, detailed, and aesthetically pleasing picture that resembles the offered immediate.

Subsequent, we present using the style_preset enter parameter, which is barely obtainable on SDXL 1.0. Passing in a style_preset parameter guides the picture era mannequin in the direction of a specific type.
Among the obtainable style_preset parameters are improve, anime, photographic, digital-art, comic-book, fantasy-art, line-art, analog-film, neon-punk, isometric, low-poly, origami, modeling-compound, cinematic, 3d-mode, pixel-art, and tile-texture. This checklist of fashion presets is topic to alter; discuss with the most recent launch and documentation for updates.
For this instance, we use a immediate to generate a teapot with a style_preset of origami. The mannequin was capable of generate a high-quality picture within the offered artwork type.

Let’s attempt some extra type presets with completely different prompts. The following instance reveals a method preset for portrait era utilizing style_preset="photographic" with the immediate “portrait of an previous and drained lion actual pose.”

Now let’s attempt the identical immediate (“portrait of an previous and drained lion actual pose”) with modeling-compound because the type preset. The output picture is a definite picture made with out having any specific really feel that’s imparted by the mannequin, guaranteeing absolute freedom of fashion.

Multi-prompting with SDXL 1.0
As we’ve seen, one of many core foundations of the mannequin is the flexibility to generate photos by way of prompting. SDXL 1.0 helps multi-prompting. With multi-prompting, you may combine ideas collectively by assigning every immediate a selected weight. As you may see within the following generated picture, it has a jungle background with tall shiny inexperienced grass. This picture was generated utilizing the next prompts. You may evaluate this to a single immediate from our earlier instance.

Spatially conscious generated photos and adverse prompts
Subsequent, we have a look at poster design with an in depth immediate. As we noticed earlier, multi-prompting lets you mix ideas to create new and distinctive outcomes.
On this instance, the immediate may be very detailed when it comes to topic place, look, expectations, and environment. The mannequin can be attempting to keep away from photos which have distortion or are poorly rendered with the assistance of a adverse immediate. The picture generated reveals spatially organized objects and topics.
textual content = “A cute fluffy white cat stands on its hind legs, peering curiously into an ornate golden mirror. However within the reflection, the cat sees not itself, however a mighty lion. The mirror illuminated with a mushy glow in opposition to a pure white background.”

Let’s attempt one other instance, the place we preserve the identical adverse immediate however change the detailed immediate and elegance preset. As you may see, the generated picture not solely spatially arranges objects, but additionally modifications the type presets with consideration to particulars just like the ornate golden mirror and reflection of the topic solely.

Face era with SDXL 1.0
On this instance, we present how SDXL 1.0 creates enhanced picture composition and face era with real looking options similar to palms and fingers. The generated picture is of a human determine created by AI with clearly raised palms. Observe the main points within the fingers and the pose. An AI-generated picture similar to this might in any other case have been amorphous.

Textual content era utilizing SDXL 1.0
SDXL is primed for complicated picture design workflows that embrace era of textual content inside photos. This instance immediate showcases this functionality. Observe how clear the textual content era is utilizing SDXL and spot the type preset of cinematic.

Uncover SDXL 1.0 from SageMaker JumpStart
SageMaker JumpStart onboards and maintains basis fashions so that you can entry, customise, and combine into your ML lifecycles. Some fashions are open weight fashions that will let you entry and modify mannequin weights and scripts, whereas some are closed weight fashions that don’t will let you entry them to guard the IP of mannequin suppliers. Closed weight fashions require you to subscribe to the mannequin from the AWS Market mannequin element web page, and SDXL 1.0 is a mannequin with closed weight right now. On this part, we go over easy methods to uncover, subscribe, and deploy a closed weight mannequin from SageMaker Studio.
You may entry SageMaker JumpStart by selecting JumpStart below Prebuilt and automatic options on the SageMaker Studio House web page.
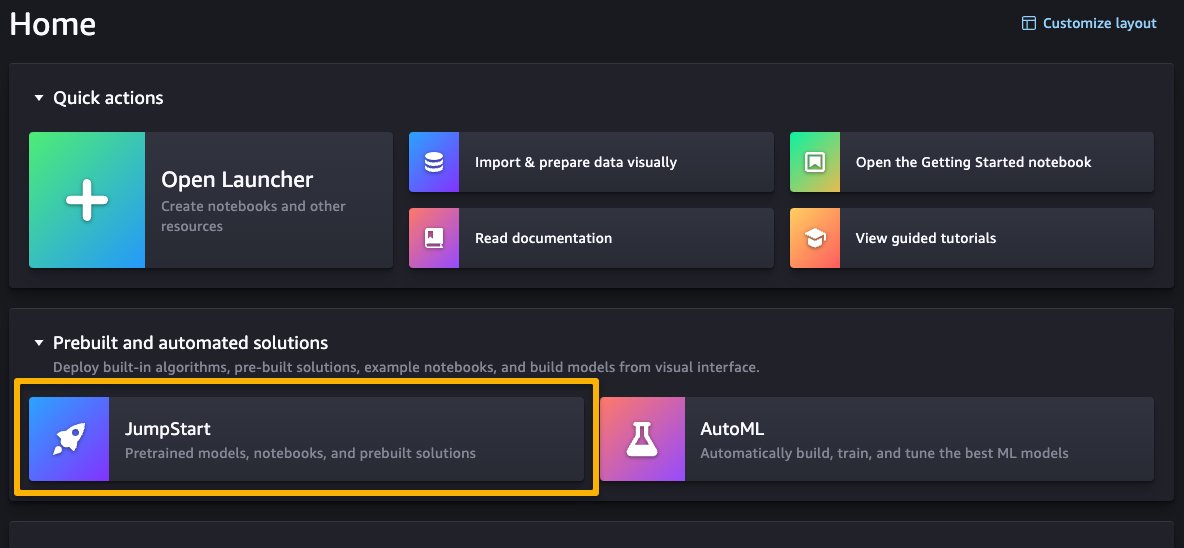
From the SageMaker JumpStart touchdown web page, you may browse for options, fashions, notebooks, and different assets. The next screenshot reveals an instance of the touchdown web page with options and basis fashions listed.
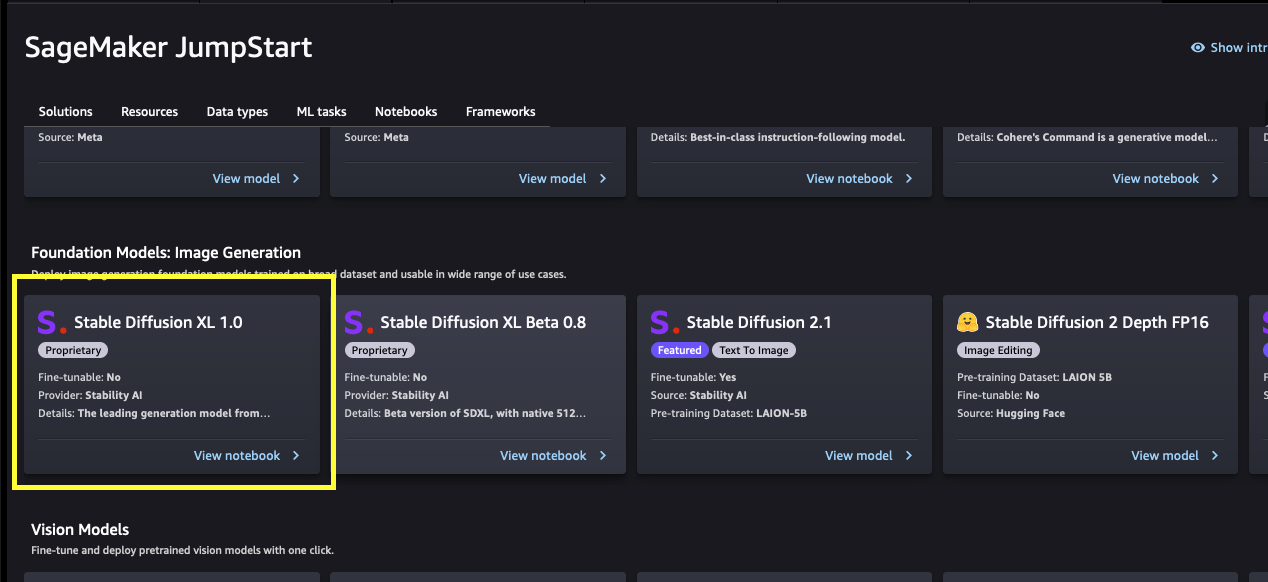
Every mannequin has a mannequin card, as proven within the following screenshot, which comprises the mannequin identify, whether it is fine-tunable or not, the supplier identify, and a brief description in regards to the mannequin. Yow will discover the Steady Diffusion XL 1.0 mannequin within the Basis Mannequin: Picture Era carousel or seek for it within the search field.
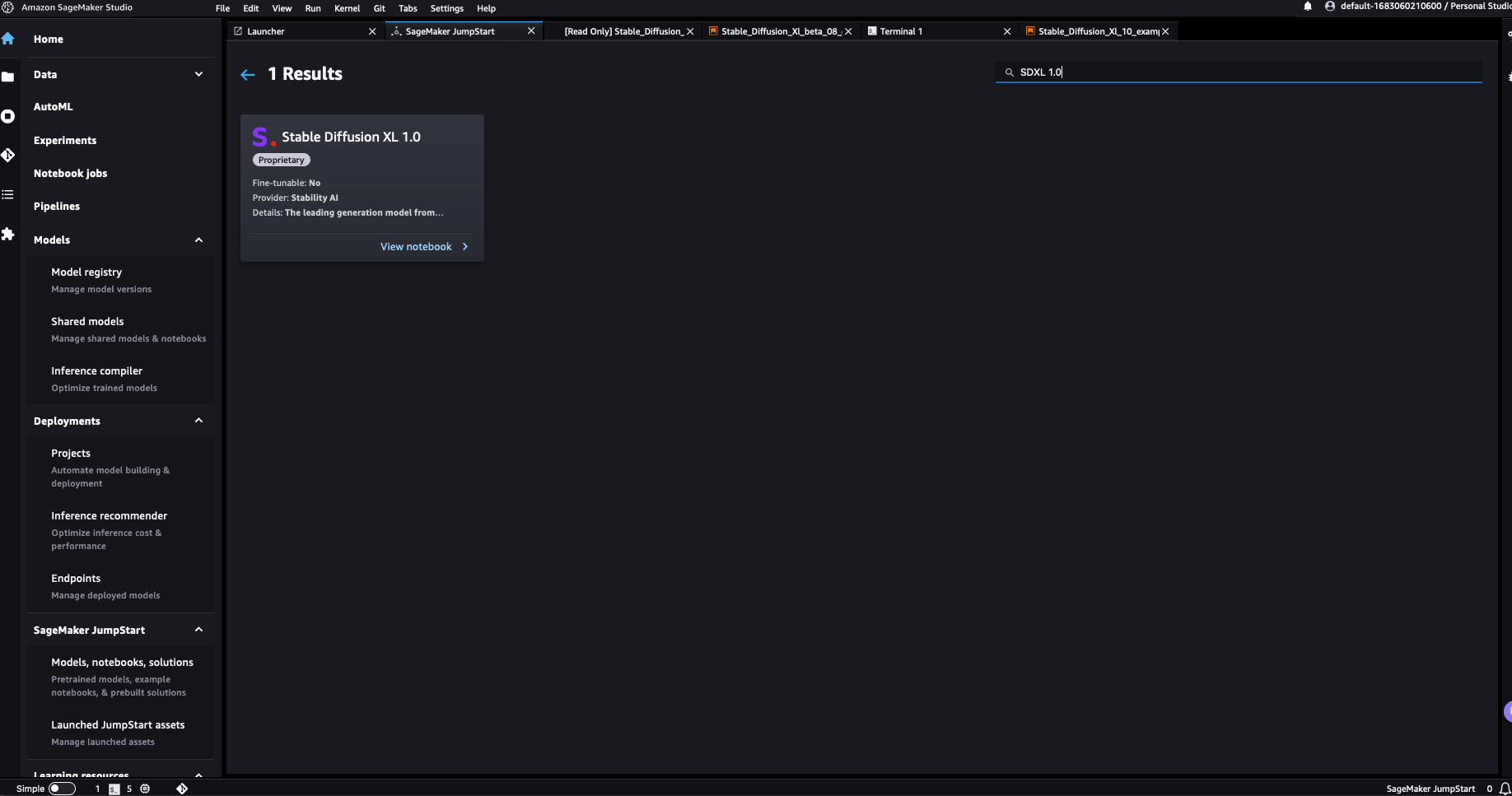
You may select Steady Diffusion XL 1.0 to open an instance pocket book that walks you thru easy methods to use the SDXL 1.0 mannequin. The instance pocket book opens as read-only mode; it’s essential to select Import pocket book to run it.

After importing the pocket book, it’s essential to choose the suitable pocket book surroundings (picture, kernel, occasion kind, and so forth) earlier than operating the code.
Deploy SDXL 1.0 from SageMaker JumpStart
On this part, we stroll by means of easy methods to subscribe and deploy the mannequin.
- Open the mannequin itemizing web page in AWS Marketplace utilizing the hyperlink obtainable from the instance pocket book in SageMaker JumpStart.
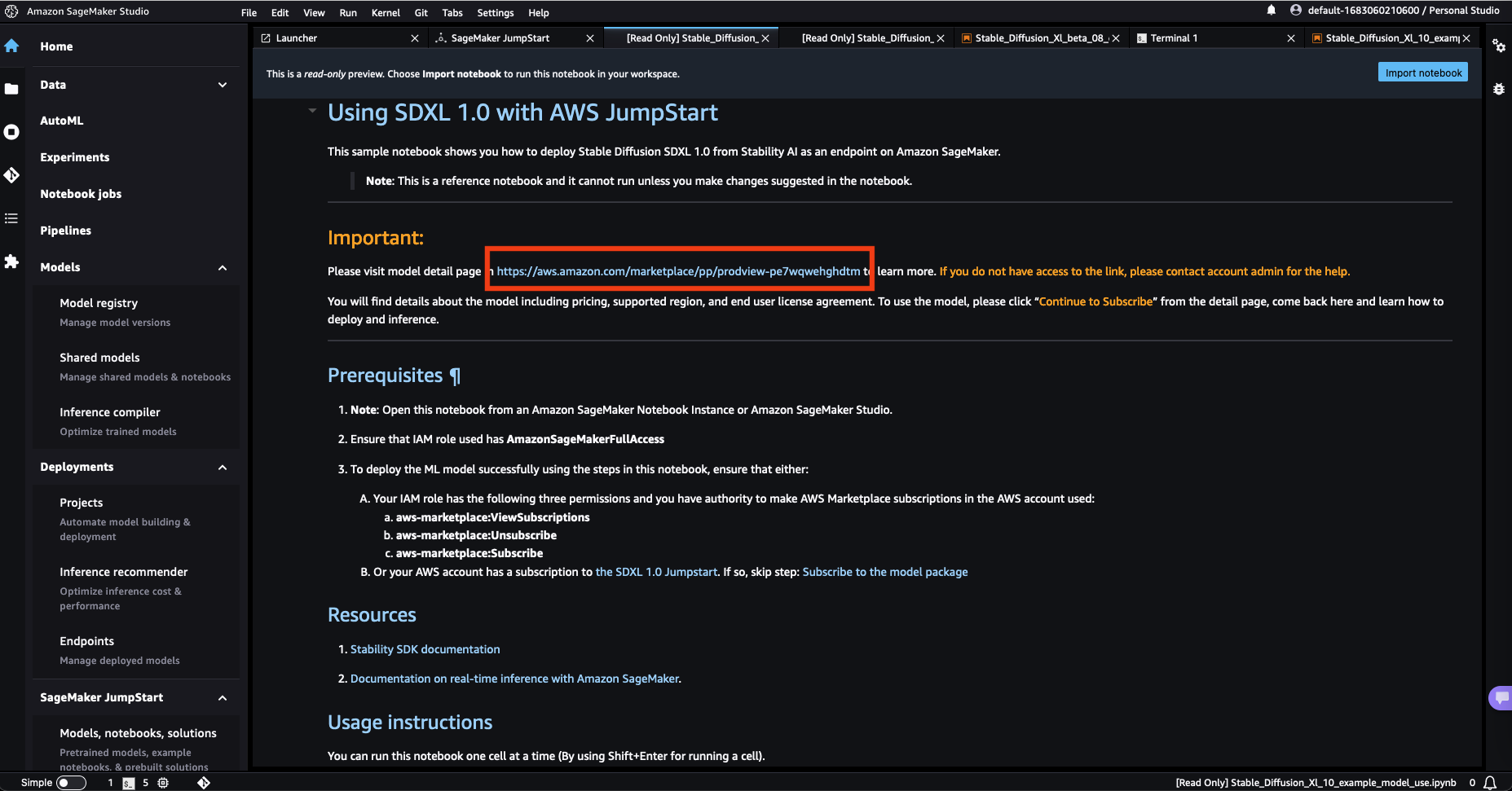
- On the AWS Market itemizing, select Proceed to subscribe.
When you don’t have the required permissions to view or subscribe to the mannequin, attain out to your AWS administrator or procurement level of contact. Many enterprises might restrict AWS Market permissions to manage the actions that somebody can take within the AWS Market Administration Portal.
- Select Proceed to Subscribe.
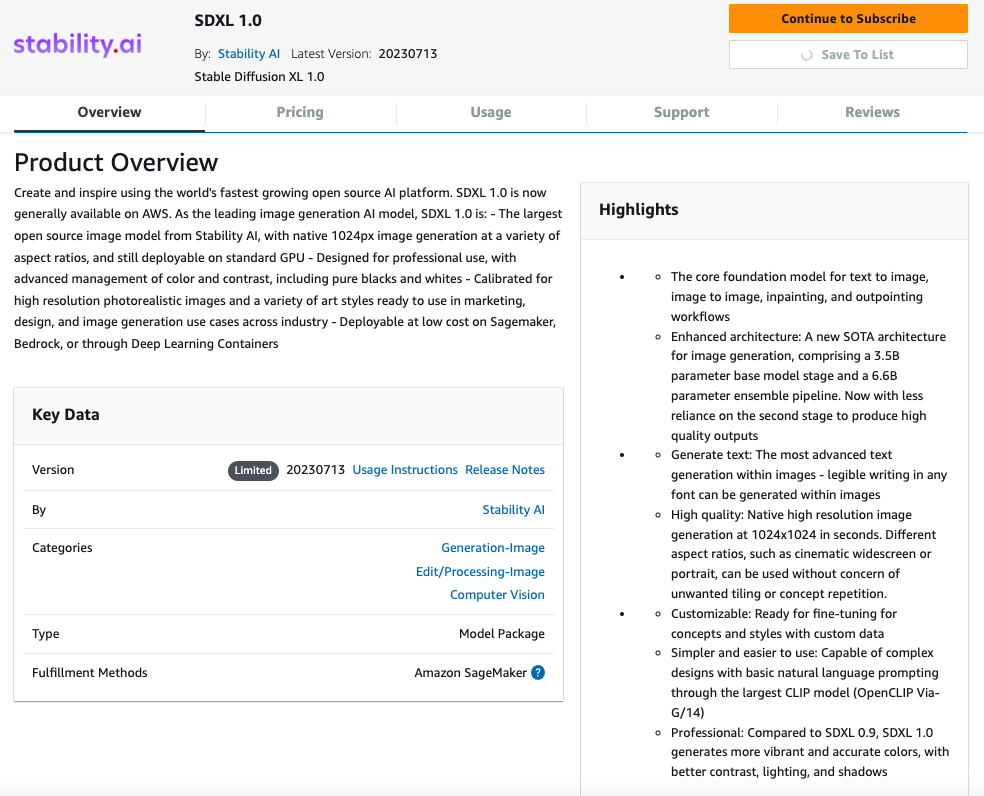
- On the Subscribe to this software program web page, evaluation the pricing particulars and Finish Person Licensing Settlement (EULA). If agreeable, select Settle for provide.
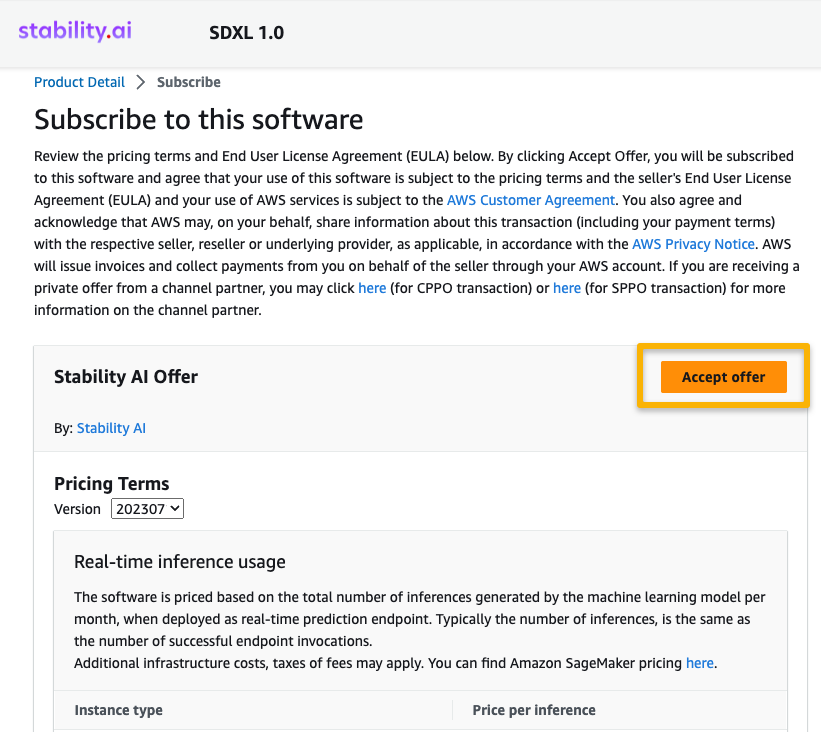
- Select Proceed to configuration to begin configuring your mannequin.
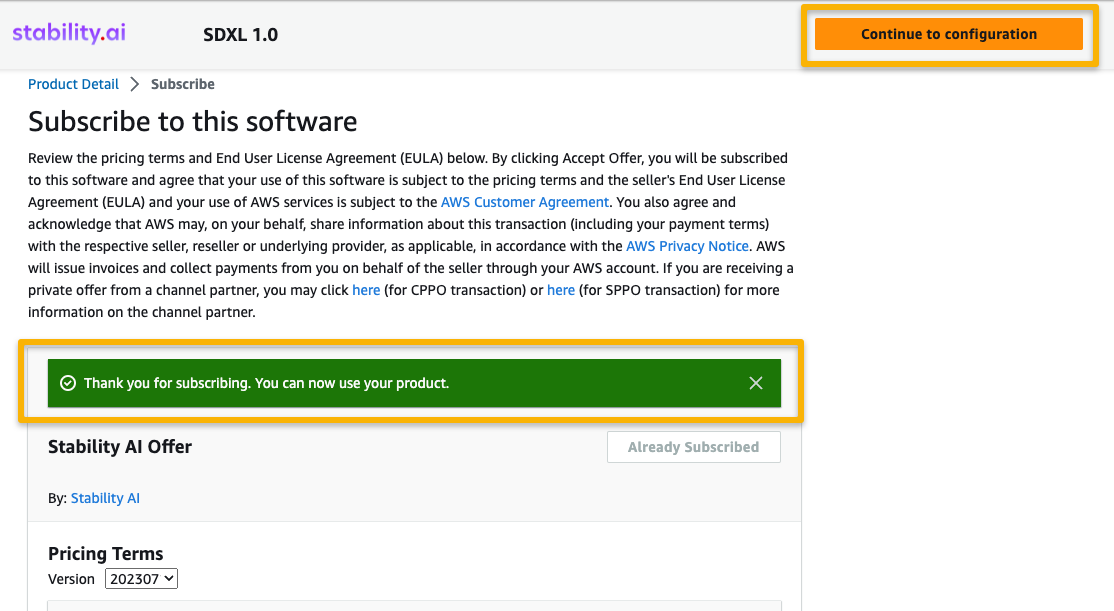
- Select a supported Area.
You will notice a product ARN displayed. That is the mannequin bundle ARN that it’s essential to specify whereas making a deployable mannequin utilizing Boto3.
- Copy the ARN similar to your Area and specify the identical within the pocket book’s cell instruction.
ARN data could also be already obtainable within the instance pocket book.
- Now you’re prepared to begin following the instance pocket book.
You may as well proceed from AWS Market, however we suggest following the instance pocket book in SageMaker Studio to higher perceive how deployment works.
Clear up
If you’ve completed working, you may delete the endpoint to launch the Amazon Elastic Compute Cloud (Amazon EC2) cases related to it and cease billing.
Get your checklist of SageMaker endpoints utilizing the AWS CLI as follows:
Then delete the endpoints:
Conclusion
On this submit, we confirmed you easy methods to get began with the brand new SDXL 1.0 mannequin in SageMaker Studio. With this mannequin, you may benefit from the completely different options supplied by SDXL to create real looking photos. As a result of basis fashions are pre-trained, they’ll additionally assist decrease coaching and infrastructure prices and allow customization to your use case.
Sources
In regards to the authors
 June Gained is a product supervisor with SageMaker JumpStart. He focuses on making basis fashions simply discoverable and usable to assist clients construct generative AI functions.
June Gained is a product supervisor with SageMaker JumpStart. He focuses on making basis fashions simply discoverable and usable to assist clients construct generative AI functions.
 Mani Khanuja is an Synthetic Intelligence and Machine Studying Specialist SA at Amazon Net Providers (AWS). She helps clients utilizing machine studying to unravel their enterprise challenges utilizing the AWS. She spends most of her time diving deep and educating clients on AI/ML initiatives associated to laptop imaginative and prescient, pure language processing, forecasting, ML on the edge, and extra. She is captivated with ML at edge, due to this fact, she has created her personal lab with self-driving equipment and prototype manufacturing manufacturing line, the place she spends lot of her free time.
Mani Khanuja is an Synthetic Intelligence and Machine Studying Specialist SA at Amazon Net Providers (AWS). She helps clients utilizing machine studying to unravel their enterprise challenges utilizing the AWS. She spends most of her time diving deep and educating clients on AI/ML initiatives associated to laptop imaginative and prescient, pure language processing, forecasting, ML on the edge, and extra. She is captivated with ML at edge, due to this fact, she has created her personal lab with self-driving equipment and prototype manufacturing manufacturing line, the place she spends lot of her free time.
 Nitin Eusebius is a Sr. Enterprise Options Architect at AWS with expertise in Software program Engineering , Enterprise Structure and AI/ML. He works with clients on serving to them construct well-architected functions on the AWS platform. He’s captivated with fixing expertise challenges and serving to clients with their cloud journey.
Nitin Eusebius is a Sr. Enterprise Options Architect at AWS with expertise in Software program Engineering , Enterprise Structure and AI/ML. He works with clients on serving to them construct well-architected functions on the AWS platform. He’s captivated with fixing expertise challenges and serving to clients with their cloud journey.
 Suleman Patel is a Senior Options Architect at Amazon Net Providers (AWS), with a particular deal with Machine Studying and Modernization. Leveraging his experience in each enterprise and expertise, Suleman helps clients design and construct options that sort out real-world enterprise issues. When he’s not immersed in his work, Suleman loves exploring the outside, taking highway journeys, and cooking up scrumptious dishes within the kitchen.
Suleman Patel is a Senior Options Architect at Amazon Net Providers (AWS), with a particular deal with Machine Studying and Modernization. Leveraging his experience in each enterprise and expertise, Suleman helps clients design and construct options that sort out real-world enterprise issues. When he’s not immersed in his work, Suleman loves exploring the outside, taking highway journeys, and cooking up scrumptious dishes within the kitchen.
 Dr. Vivek Madan is an Utilized Scientist with the Amazon SageMaker JumpStart staff. He received his PhD from College of Illinois at Urbana-Champaign and was a Submit Doctoral Researcher at Georgia Tech. He’s an lively researcher in machine studying and algorithm design and has printed papers in EMNLP, ICLR, COLT, FOCS, and SODA conferences.
Dr. Vivek Madan is an Utilized Scientist with the Amazon SageMaker JumpStart staff. He received his PhD from College of Illinois at Urbana-Champaign and was a Submit Doctoral Researcher at Georgia Tech. He’s an lively researcher in machine studying and algorithm design and has printed papers in EMNLP, ICLR, COLT, FOCS, and SODA conferences.



