Meet TALL: An AI Method that Transforms a Video Clip right into a Pre-Outlined Format to Notice the Preservation of Spatial and Temporal Dependencies
The paper’s essential subject is creating a way for detecting deep pretend movies. DeepFakes are manipulated movies that use synthetic intelligence to make it seem as if somebody is saying or doing one thing they didn’t. These manipulated movies can be utilized maliciously and pose a menace to particular person privateness and safety. The issue the researchers try to unravel is the detection of those deepfake movies.
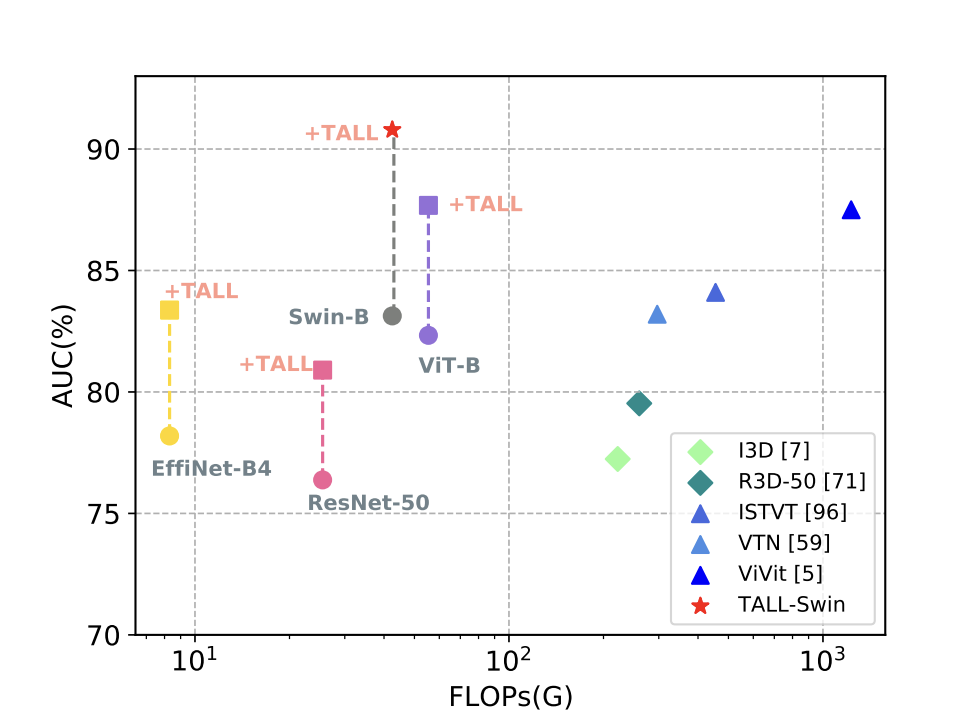
Present video detection strategies are computationally intensive, and their generalizability must be improved. A crew of researchers suggest a easy but efficient technique named Thumbnail Format (TALL), which transforms a video clip right into a predefined structure to protect spatial and temporal dependencies.
Spatial Dependency: This refers back to the idea that close by or neighboring information factors usually tend to be comparable than these which are additional aside. Within the context of picture or video processing, spatial dependency usually refers back to the relationship between pixels in a picture or a body.
Temporal Dependency: This refers back to the idea that present information factors or occasions are influenced by previous information factors or occasions. Within the context of video processing, temporal dependency usually refers back to the relationship between frames in a video.
This technique proposed by the researchers is model-agnostic and easy, requiring just a few modifications to the code. The authors integrated TALL into the Swin Transformer, forming an environment friendly and efficient technique, TALL-Swin. The paper consists of in depth intra-dataset and cross-dataset experiments to validate TALL and TALL-Swin’s validity and superiority.
A quick overview about Swin Transformer:
Microsoft’s Swin Transformer is a kind of Imaginative and prescient Transformer, a category of fashions which have been profitable in picture recognition duties. The Swin Transformer is particularly designed to deal with hierarchical options in a picture, which could be useful for duties like object detection and semantic segmentation. To resolve the issues the unique ViT had, the Swin Transformer included two essential concepts: hierarchical function maps and shifted window consideration. Making use of the Swin Transformer in conditions the place fine-grained prediction is required is made doable by hierarchical function maps. In the present day, all kinds of imaginative and prescient jobs generally use the Swin Transformer as their spine structure.
Thumbnail Format (TALL) technique proposed within the paper:
Masking: Step one entails masking consecutive frames in a hard and fast place in every body. Within the paper context, every body is being “masked” or ignored, forcing the mannequin to give attention to the unmasked components and doubtlessly be taught extra strong options.
Resizing: After masking, the frames are resized into sub-images. This step seemingly reduces the computational complexity of the mannequin, as smaller photos require much less computational assets to course of.
Rearranging: The resized sub-images are then rearranged right into a predefined structure, which varieties the “thumbnail”. This step is essential for preserving the spatial and temporal dependencies of the video. By arranging the sub-images in a selected means, the mannequin can analyze each the relationships between pixels inside every sub-image (spatial dependencies) and the relationships between sub-images over time (temporal dependencies).
Experiments to judge the effectiveness of their TALL-Swin technique for detecting deepfake movies:
Intra-dataset evaluations:
The authors in contrast TALL-Swin with a number of superior strategies utilizing the FF++ dataset below each Low High quality (LQ) and Excessive High quality (HQ) movies. They discovered that TALL-Swin had comparable efficiency and decrease consumption than the earlier video transformer technique with HQ settings.
Generalization to unseen datasets:
The authors additionally examined the generalization capacity of TALL-Swin by coaching a mannequin on the FF++ (HQ) dataset after which testing it on the Celeb-DF (CDF), DFDC, FaceShifter (FSh), and DeeperForensics (DFo) datasets. They discovered that TALL-Swin achieved state-of-the-art outcomes.
Saliency map visualization:
The authors used Grad-CAM to visualise the place TALL-Swin was being attentive to the deepfake faces. They discovered that TALL-Swin was capable of seize method-specific artifacts and give attention to essential areas, such because the face and mouth areas.
Conclusion:
Lastly, I want to conclude that the authors discovered that their TALL-Swin technique was efficient for detecting deepfake movies, demonstrating comparable or superior efficiency to present strategies, good generalization capacity to unseen datasets, and robustness to frequent perturbations.
Try the Paper. All Credit score For This Analysis Goes To the Researchers on This Mission. Additionally, don’t neglect to hitch our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra.
I’m Mahitha Sannala, a Laptop Science Grasp’s scholar on the College of California, Riverside. I maintain a Bachelor’s diploma in Laptop Science and Engineering from the Indian Institute of Know-how, Palakkad. My essential areas of curiosity lie in Synthetic Intelligence and Machine studying. I’m notably keen about working with medical information and to derive beneficial insights from them . As a devoted learner, I’m keen to remain up to date with the newest developments within the fields of AI and ML.



