Unlock the Secrets and techniques to Selecting the Excellent Machine Studying Algorithm!
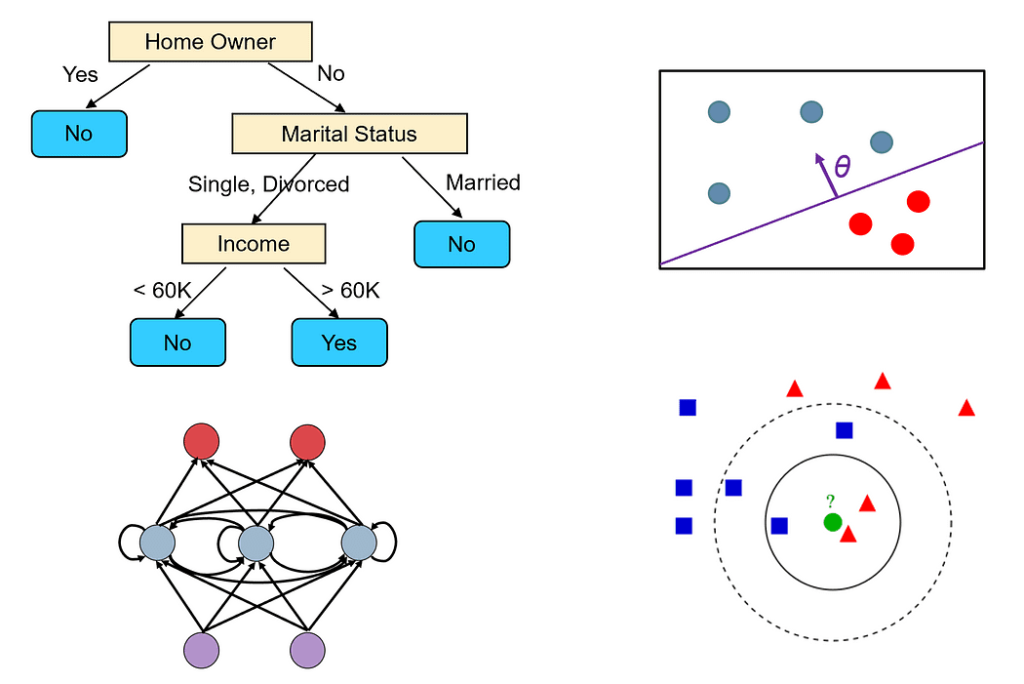
One of many key choices you’ll want to make when fixing a knowledge science drawback is which machine learning algorithm to make use of.
There are a whole lot of machine studying algorithms to select from, every with its personal benefits and downsides. Some algorithms may fit higher than others on particular forms of issues or on particular information units.
The “No Free Lunch” (NFL) theorem states that there isn’t a one algorithm that works greatest for each drawback, or in different phrases, all algorithms have the identical efficiency when their efficiency is averaged over all of the attainable issues.
Completely different machine studying fashions
On this article, we’ll talk about the details it is best to think about when selecting a mannequin on your drawback and the best way to examine completely different machine studying algorithms.
The next checklist comprises 10 questions you might ask your self when contemplating a selected machine-learning algorithm:
- Which sort of issues can the algorithm remedy? Can the algorithm remedy solely regression or classification issues, or can it remedy each? Can it deal with multi-class/multi-label issues or solely binary classification issues?
- Does the algorithm have any assumptions in regards to the information set? For instance, some algorithms assume that the info is linearly separable (e.g., perceptron or linear SVM), whereas others assume that the info is generally distributed (e.g., Gaussian Combination Fashions).
- Are there any ensures in regards to the efficiency of the algorithm? For instance, if the algorithm tries to resolve an optimization drawback (as in logistic regression or neural networks), is it assured to search out the worldwide optimum or solely a neighborhood optimum resolution?
- How a lot information is required to coach the mannequin successfully? Some algorithms, like deep neural networks, are extra data-savvy than others.
- Does the algorithm are likely to overfit? If that’s the case, does the algorithm present methods to cope with overfitting?
- What are the runtime and reminiscence necessities of the algorithm, each throughout coaching and prediction time?
- Which information preprocessing steps are required to organize the info for the algorithm?
- What number of hyperparameters does the algorithm have? Algorithms which have numerous hyperparameters take extra time to coach and tune.
- Can the outcomes of the algorithm be simply interpreted? In lots of drawback domains (corresponding to medical analysis), we want to have the ability to clarify the mannequin’s predictions in human phrases. Some fashions may be simply visualized (corresponding to determination bushes), whereas others behave extra like a black field (e.g., neural networks).
- Does the algorithm assist on-line (incremental) studying, i.e., can we practice it on further samples with out rebuilding the mannequin from scratch?
For instance, let’s take two of the most well-liked algorithms: decision trees and neural networks, and examine them in response to the above standards.
Resolution Timber
- Resolution bushes can deal with each classification and regression issues. They’ll additionally simply deal with multi-class and multi-label issues.
- Resolution tree algorithms do not need any particular assumptions in regards to the information set.
- A choice tree is constructed utilizing a grasping algorithm, which isn’t assured to search out the optimum tree (i.e., the tree that minimizes the variety of assessments required to categorise all of the coaching samples accurately). Nonetheless, a choice tree can obtain 100% accuracy on the coaching set if we maintain extending its nodes till all of the samples within the leaf nodes belong to the identical class. Such bushes are normally not good predictors, as they overfit the noise within the coaching set.
- Resolution bushes can work nicely even on small or medium-sized information units.
- Resolution bushes can simply overfit. Nonetheless, we will scale back overfitting through the use of tree pruning. We are able to additionally use ensemble methods corresponding to random forests that mix the output of a number of determination bushes. These strategies undergo much less from overfitting.
- The time to construct a choice tree is O(n²p), the place n is the variety of coaching samples, and p is the variety of options. The prediction time in determination bushes relies on the peak of the tree, which is normally logarithmic in n, since most determination bushes are pretty balanced.
- Resolution bushes don’t require any information preprocessing. They’ll seamlessly deal with several types of options, together with numerical and categorical options. Additionally they don’t require normalization of the info.
- Resolution bushes have a number of key hyperparameters that have to be tuned, particularly if you’re utilizing pruning, corresponding to the utmost depth of the tree and which impurity measure to make use of to resolve the best way to break up the nodes.
- Resolution bushes are easy to know and interpret, and we will simply visualize them (until the tree may be very giant).
- Resolution bushes can’t be simply modified to take note of new coaching samples since small modifications within the information set may cause giant modifications within the topology of the tree.
Neural Networks
- Neural networks are some of the common and versatile machine studying fashions that exist. They’ll remedy nearly any kind of drawback, together with classification, regression, time collection evaluation, computerized content material technology, and so on.
- Neural networks do not need assumptions in regards to the information set, however the information must be normalized.
- Neural networks are skilled utilizing gradient descent. Thus, they’ll solely discover a native optimum resolution. Nonetheless, there are numerous strategies that can be utilized to keep away from getting caught in native minima, corresponding to momentum and adaptive studying charges.
- Deep neural nets require numerous information to coach within the order of thousands and thousands of pattern factors. Typically, the bigger the community is (the extra layers and neurons it has), extra we want information to coach it.
- Networks which can be too giant would possibly memorize all of the coaching samples and never generalize nicely. For a lot of issues, you can begin from a small community (e.g., with just one or two hidden layers) and step by step improve its dimension till you begin overfitting the coaching set. You can too add regularization with a purpose to cope with overfitting.
- The coaching time of a neural community relies on many components (the scale of the community, the variety of gradient descent iterations wanted to coach it, and so on.). Nonetheless, prediction time may be very quick since we solely have to do one ahead go over the community to get the label.
- Neural networks require all of the options to be numerical and normalized.
- Neural networks have numerous hyperparameters that have to be tuned, such because the variety of layers, the variety of neurons in every layer, which activation operate to make use of, the training fee, and so on.
- The predictions of neural networks are arduous to interpret as they’re primarily based on the computation of a lot of neurons, every of which has solely a small contribution to the ultimate prediction.
- Neural networks can simply adapt to incorporate further coaching samples, as they use an incremental studying algorithm (stochastic gradient descent).
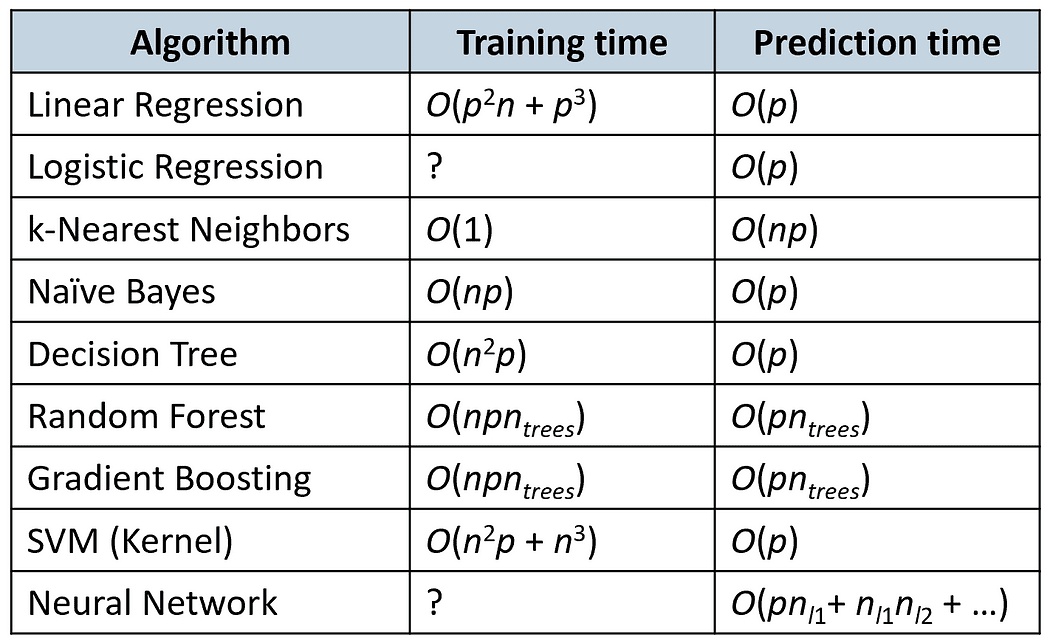
The next desk compares the coaching and prediction occasions of some widespread algorithms (n is the variety of coaching samples and p is the variety of options).
Based on a survey that was completed in 2016, probably the most incessantly used algorithms by Kaggle competitors winners had been gradient boosting algorithms (XGBoost) and neural networks (see this article).
Amongst the 29 Kaggle competitors winners in 2015, 8 of them used XGBoost, 9 used deep neural nets, and 11 used an ensemble of each.
XGBoost was primarily utilized in issues that handled structured information (e.g., relational tables), whereas neural networks had been extra profitable in dealing with unstructured issues (e.g., issues that cope with picture, voice, or textual content).
It could be attention-grabbing to verify if that is nonetheless the state of affairs at the moment or whether or not the tendencies have modified (is anybody up for the problem?)
Thanks for studying!
Dr. Roi Yehoshua is a educating professor at Northeastern College in Boston, educating courses that make up the Grasp’s program in Knowledge Science. His analysis in multi-robot methods and reinforcement studying has been revealed within the prime main journals and conferences in AI. He’s additionally a prime author on the Medium social platform, the place he incessantly publishes articles on Knowledge Science and Machine Studying.
Original. Reposted with permission.





