Meet Immediate Diffusion: An AI Framework For Enabling In-Context Studying In Diffusion-Primarily based Generative Fashions
State-of-the-art giant language fashions (LLMs), together with BERT, GPT-2, BART, T5, GPT-3, and GPT-4, have been developed because of current advances in machine studying, notably within the space of pure language processing (NLP). These fashions have been successfully used for varied duties, together with textual content manufacturing, machine translation, sentiment evaluation, and question-answering. Their capability to study from context, usually referred to as in-context studying, is certainly one of these LLMs’ emergent behaviors. With out optimizing any mannequin parameters, LLMs with in-context studying capabilities, like GPT-3, can full a job by conditioning on input-output samples and contemporary question inputs.
The pre-training of quite a few language duties could also be mixed with in-context studying and a well-designed immediate construction, permitting LLMs to generalize efficiently to actions they’ve by no means encountered. Though in-context studying has been broadly investigated in NLP, few functions in pc imaginative and prescient exist. There are two important difficulties to demonstrating the practicality and promise of in-context studying as a normal approach for nice imaginative and prescient functions: 1) Creating an efficient imaginative and prescient immediate is tougher than creating prompts for language actions as a result of it requires each domain-specific input-output pairs as examples and movie searches as standards. 2) In pc imaginative and prescient, large fashions are sometimes educated for specialised duties, together with text-to-image era, class-conditional creation, segmentation, detection, and classification.
These large imaginative and prescient fashions have to be extra versatile to adapt to new duties and aren’t constructed for in-context studying. A number of current makes an attempt deal with these points through the use of NLP’s solutions. Particularly, when a basic visible cue is made by fusing pattern images, question pictures, and output pictures into one huge embodiment, a Transformer-based picture inpainting mannequin is educated to anticipate the masked output pictures. Nonetheless, stitching to very large pictures will considerably elevate the computational expense, notably in high-resolution situations. This work addresses the in-context studying potential of text-guided diffusion-based generative fashions by addressing these two points.
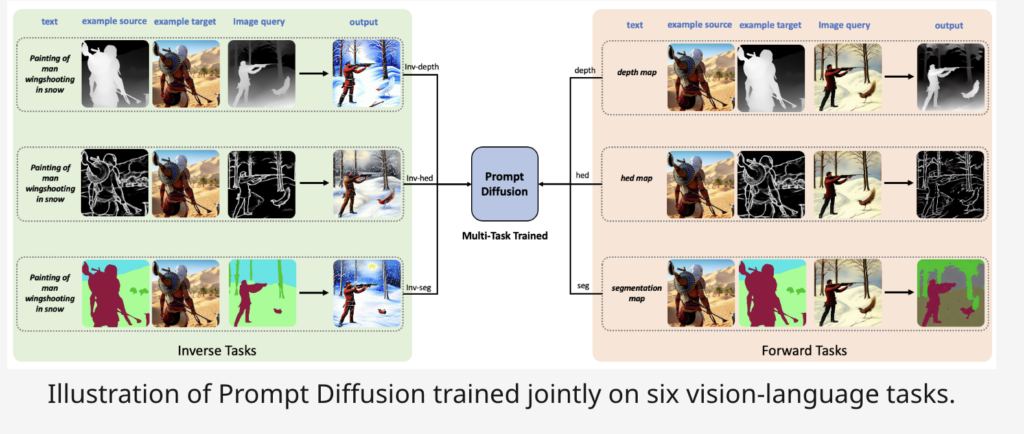
To execute in-context studying beneath a vision-language immediate that may deal with a variety of vision-language actions, researchers from Microsoft and UT Austin current a novel mannequin structure known as Immediate Diffusion. Immediate Diffusion is put by way of six separate vision-language duties in tandem. Particularly, they make the most of their vision-language immediate to explain a generic vision-language job. Then, utilizing the Secure Diffusion and ControlNet designs as inspiration, they assemble Immediate Diffusion, which can use their vision-language immediate as enter. They counsel Immediate Diffusion as a primary step in direction of enabling text-guided diffusion fashions’ capability for in-context studying. It might then use this information to create the output picture by re-mapping the connection onto the question picture and together with the language directions. Extra crucially, studying throughout many duties endows the mannequin with the capability for in-context studying. Immediate Diffusion could generalize efficiently over a number of novel capabilities that haven’t but been noticed. That is along with performing effectively on the six duties it has seen throughout coaching.
Empirically, Immediate Diffusion performs effectively on acquainted and novel, unseen duties concerning in-context studying. Immediate Diffusion’s effectiveness is predicted to encourage and spur extra examine into diffusion-based, in-context visible studying. Following is a abstract of their key contributions:
• A cutting-edge design for vision-language prompts that successfully permits the fusion of a number of vision-language actions.
• Excessive-quality in-context era on the discovered and new, unseen duties utilizing the immediate diffusion mannequin, the primary diffusion-based adaptable vision-language basis mannequin able to in-context studying.
• Pytorch code implementation will be discovered on GitHub.
Try the Paper, Project, and Github Link. Don’t overlook to hitch our 21k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI tasks, and extra. You probably have any questions concerning the above article or if we missed something, be at liberty to e mail us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
Aneesh Tickoo is a consulting intern at MarktechPost. He’s presently pursuing his undergraduate diploma in Knowledge Science and Synthetic Intelligence from the Indian Institute of Expertise(IIT), Bhilai. He spends most of his time engaged on tasks aimed toward harnessing the facility of machine studying. His analysis curiosity is picture processing and is keen about constructing options round it. He loves to attach with individuals and collaborate on attention-grabbing tasks.



