Improve Amazon Lex with conversational FAQ options utilizing LLMs

Amazon Lex is a service that means that you can shortly and simply construct conversational bots (“chatbots”), digital brokers, and interactive voice response (IVR) techniques for purposes similar to Amazon Connect.
Synthetic intelligence (AI) and machine studying (ML) have been a spotlight for Amazon for over 20 years, and most of the capabilities that clients use with Amazon are pushed by ML. Immediately, giant language fashions (LLMs) are reworking the best way builders and enterprises remedy traditionally complicated challenges associated to pure language understanding (NLU). We introduced Amazon Bedrock lately, which democratizes Foundational Mannequin entry for builders to simply construct and scale generative AI-based purposes, utilizing acquainted AWS instruments and capabilities. One of many challenges enterprises face is to include their enterprise information into LLMs to ship correct and related responses. When leveraged successfully, enterprise information bases can be utilized to ship tailor-made self-service and assisted-service experiences, by delivering info that helps clients remedy issues independently and/or augmenting an agent’s information. Immediately, a bot developer can enhance self-service experiences with out using LLMs in a few methods. First, by creating intents, pattern utterances, and responses, thereby masking all anticipated person questions inside an Amazon Lex bot. Second, builders may also combine bots with search options, which might index paperwork saved throughout a variety of repositories and discover probably the most related doc to reply their buyer’s query. These strategies are efficient, however require developer sources making getting began troublesome.
One of many advantages supplied by LLMs is the flexibility to create related and compelling conversational self-service experiences. They achieve this by leveraging enterprise information base(s) and delivering extra correct and contextual responses. This weblog submit introduces a strong resolution for augmenting Amazon Lex with LLM-based FAQ options utilizing the Retrieval Augmented Era (RAG). We’ll evaluation how the RAG strategy augments Amazon Lex FAQ responses utilizing your organization knowledge sources. As well as, we will even exhibit Amazon Lex integration with LlamaIndex, which is an open-source knowledge framework that gives information supply and format flexibility to the bot developer. As a bot developer positive factors confidence with utilizing a LlamaIndex to discover LLM integration, they will scale the Amazon Lex functionality additional. They’ll additionally use enterprise search providers similar to Amazon Kendra, which is natively built-in with Amazon Lex.
On this resolution, we showcase the sensible utility of an Amazon Lex chatbot with LLM-based RAG enhancement. We use the Zappos customer support use case for instance to exhibit the effectiveness of this resolution, which takes the person by way of an enhanced FAQ expertise (with LLM), relatively than directing them to fallback (default, with out LLM).
Resolution overview
RAG combines the strengths of conventional retrieval-based and generative AI based mostly approaches to Q&A techniques. This system harnesses the ability of huge language fashions, similar to Amazon Titan or open-source fashions (for instance, Falcon), to carry out generative duties in retrieval techniques. It additionally takes under consideration the semantic context from saved paperwork extra successfully and effectively.
RAG begins with an preliminary retrieval step to retrieve related paperwork from a group based mostly on the person’s question. It then employs a language mannequin to generate a response by contemplating each the retrieved paperwork and the unique question. By integrating RAG into Amazon Lex, we are able to present correct and complete solutions to person queries, leading to a extra partaking and satisfying person expertise.
The RAG strategy requires doc ingestion in order that embeddings may be created to allow LLM-based search. The next diagram reveals how the ingestion course of creates the embeddings which might be then utilized by the chatbot throughout fallback to reply the client’s query.
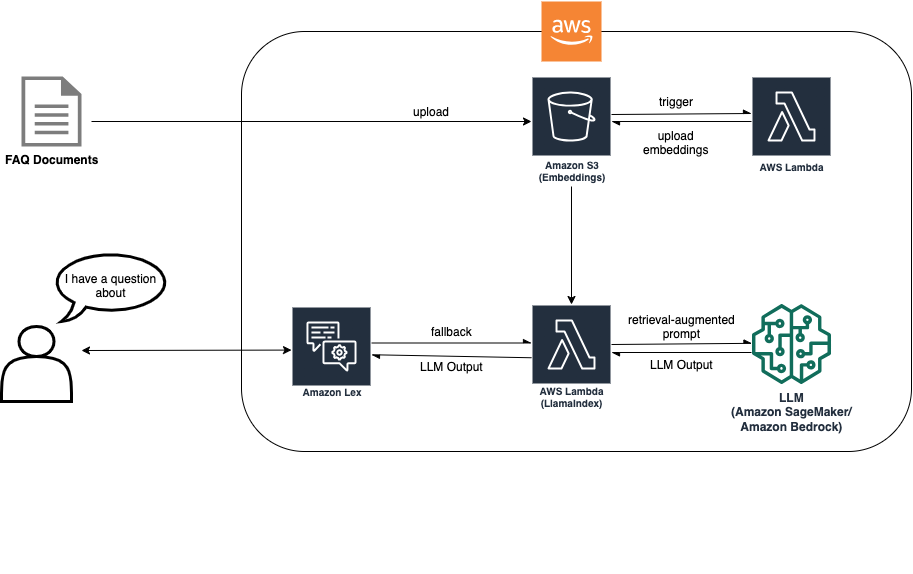
With this resolution structure, it is best to select probably the most appropriate LLM on your use case. It additionally gives an inference endpoint selection between Amazon Bedrock (in restricted preview) and fashions hosted on Amazon SageMaker JumpStart, providing further LLM flexibility.
The doc is uploaded to an Amazon Simple Storage Service (Amazon S3) bucket. The S3 bucket has an occasion listener connected that invokes an AWS Lambda operate on adjustments to the bucket. The occasion listener ingests the brand new doc and locations the embeddings in one other S3 bucket. The embeddings are then utilized by the RAG implementation within the Amazon Lex bot in the course of the fallback intent to reply the client’s query. The subsequent diagram reveals the structure of how an FAQ bot inside Lex may be enhanced with LLMs and RAG.
Let’s discover how we are able to combine RAG based mostly on LlamaIndex into an Amazon Lex bot. We offer code examples and an AWS Cloud Development Kit (AWS CDK) import to help you in organising the combination. You will discover the code examples in our GitHub repository. The next sections present a step-by-step information that will help you arrange the surroundings and deploy the required sources.
How RAG works with Amazon Lex
The circulation of RAG entails an iterative course of the place the retriever part retrieves related passages, the query and passages assist assemble the immediate, and the technology part produces a response. This mixture of retrieval and technology methods permits the RAG mannequin to benefit from the strengths of each approaches, offering correct and contextually acceptable solutions to person questions. The workflow gives the next capabilities:
- Retriever engine – The RAG mannequin begins with a retriever part accountable for retrieving related paperwork from a big corpus. This part usually makes use of an info retrieval approach like TF-IDF or BM25 to rank and choose paperwork which might be prone to comprise the reply to a given query. The retriever scans the doc corpus and retrieves a set of related passages.
- Immediate helper – After the retriever has recognized the related passages, the RAG mannequin strikes to immediate creation. The immediate is a mix of the query and the retrieved passages, serving as further context for the immediate, which is used as enter to the generator part. To create the immediate, the mannequin usually augments the query with the chosen passages in a particular format.
- Response technology – The immediate, consisting of the query and related passages, is fed into the technology part of the RAG mannequin. The technology part is often a language mannequin able to reasoning by way of the immediate to generate a coherent and related response.
- Last response – Lastly, the RAG mannequin selects the highest-ranked reply because the output and presents it because the response to the unique query. The chosen reply may be additional postprocessed or formatted as mandatory earlier than being returned to the person. As well as, the answer allows the filtering of the generated response if the retrieval outcomes yields a low confidence rating, implying that it doubtless falls exterior the distribution (OOD).
LlamaIndex: An open-source knowledge framework for LLM-based purposes
On this submit, we exhibit the RAG resolution based mostly on LlamaIndex. LlamaIndex is an open-source knowledge framework particularly designed to facilitate LLM-based purposes. It presents a strong and scalable resolution for managing doc assortment in several codecs. With LlamaIndex, bot builders are empowered to effortlessly combine LLM-based QA (query answering) capabilities into their purposes, eliminating the complexities related to managing options catered to large-scale doc collections. Moreover, this strategy proves to be cost-effective for smaller-sized doc repositories.
Stipulations
You need to have the next conditions:
Arrange your growth surroundings
The primary third-party bundle necessities are llama_index and sagemaker sdk. Comply with the required instructions in our GitHub repository’s README to arrange your surroundings correctly.
Deploy the required sources
This step entails creating an Amazon Lex bot, S3 buckets, and a SageMaker endpoint. Moreover, it’s essential to Dockerize the code within the Docker picture listing and push the pictures to Amazon Elastic Container Registry (Amazon ECR) in order that it could actually run in Lambda. Comply with the required instructions in our GitHub repository’s README to deploy the providers.
Throughout this step, we exhibit LLM internet hosting through SageMaker Deep Learning Containers. Regulate the settings in keeping with your computation wants:
- Mannequin – To discover a mannequin that meets your necessities, you may discover sources just like the Hugging Face mannequin hub. It presents quite a lot of fashions similar to Falcon 7B or Flan-T5-XXL. Moreover, you’ll find detailed details about numerous formally supported mannequin architectures, serving to you make an knowledgeable resolution. For extra details about totally different mannequin varieties, confer with optimized architectures.
- Mannequin inference endpoint – Outline the trail of the mannequin (for instance, Falcon 7B), select your occasion sort (for instance, g5.4xlarge), and use quantization (for instance, int-8 quantization).Observe: This resolution gives you the flexibleness to decide on one other mannequin inferencing endpoint. You may as well use Amazon Bedrock, which gives entry to different LLMs similar to Amazon Titan.Observe: This resolution gives you the flexibleness to decide on one other mannequin inferencing endpoint. You may as well use Amazon Bedrock, which gives entry to different LLMs similar to Amazon Titan.
Arrange your doc index through LlamaIndex
To arrange your doc index, first add your doc knowledge. We assume that you’ve got the supply of your FAQ content material, similar to a PDF or textual content file.
After the doc knowledge is uploaded, the LlamaIndex system will robotically provoke the method of making the doc index. This job is carried out by a Lambda operate, which generates the index and saves it to an S3 bucket.
To allow environment friendly retrieval of related info, configure the doc retriever utilizing the LlamaIndex Retriever Question Engine. This engine presents a number of customization choices, similar to the next:
- Embedding fashions – You possibly can select your embedding mannequin, similar to Hugging Face embedding.
- Confidence cutoff – Specify a confidence cutoff threshold to find out the standard of retrieval outcomes. If the arrogance rating falls beneath this threshold, you may select to offer out-of-scope responses, indicating that the question is past the scope of the listed paperwork.
Take a look at the combination
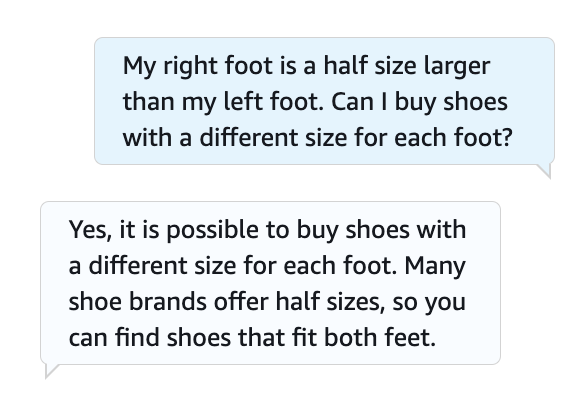
Outline your bot definition with a fallback intent and use the Amazon Lex console to check your FAQ requests. For extra particulars, please confer with GitHub repository. The next screenshot reveals an instance dialog with the bot.

Tricks to enhance your bot effectivity
The next ideas may doubtlessly additional enhance the effectivity of your bot:
- Index storage – Retailer your index in an S3 bucket or a service with vector database capabilities similar to Amazon OpenSearch. By using cloud-based storage options, you may improve the accessibility and scalability of your index, resulting in quicker retrieval instances and improved total efficiency. Additionally, Confer with this blog post for an Amazon Lex bot that makes use of an Amazon Kendra search resolution.
- Retrieval optimization – Experiment with totally different sizes of embedding fashions for the retriever. The selection of embedding mannequin can considerably affect the enter necessities of your LLM. Discovering the optimum steadiness between mannequin measurement and retrieval efficiency can lead to improved effectivity and quicker response instances.
- Immediate engineering – Experiment with totally different immediate codecs, lengths, and types to optimize the efficiency and high quality of your bot’s solutions.
- LLM mannequin choice – Choose probably the most appropriate LLM mannequin on your particular use case. Think about elements similar to mannequin measurement, language capabilities, and compatibility together with your utility necessities. Choosing the proper LLM mannequin ensures optimum efficiency and environment friendly utilization of system sources.
Contact heart conversations can span from self-service to a reside human interplay. To be used circumstances involving human-to-human interactions over Amazon Join, you should use Wisdom to look and discover content material throughout a number of repositories, similar to often requested questions (FAQs), wikis, articles, and step-by-step directions for dealing with totally different buyer points.
Clear up
To keep away from incurring future bills, proceed with deleting all of the sources that have been deployed as a part of this train. We have now offered a script to close down the SageMaker endpoint gracefully. Utilization particulars are within the README. Moreover, to take away all the opposite sources you may run cdk destroy in the identical listing as the opposite cdk instructions to deprovision all of the sources in your stack.
Abstract
This submit mentioned the next steps to boost Amazon Lex with LLM-based QA options utilizing the RAG technique and LlamaIndex:
- Set up the required dependencies, together with LlamaIndex libraries
- Arrange mannequin internet hosting through Amazon SageMaker or Amazon Bedrock (in restricted preview)
- Configure LlamaIndex by creating an index and populating it with related paperwork
- Combine RAG into Amazon Lex by modifying the configuration and configuring RAG to make use of LlamaIndex for doc retrieval
- Take a look at the combination by partaking in conversations with the chatbot and observing its retrieval and technology of correct responses
By following these steps, you may seamlessly incorporate highly effective LLM-based QA capabilities and environment friendly doc indexing into your Amazon Lex chatbot, leading to extra correct, complete, and contextually conscious interactions with customers. As a comply with up, we additionally invite you to evaluation our next blog post, which explores enhancing the Amazon Lex FAQ expertise utilizing URL ingestion and LLMs.
In regards to the authors
 Max Henkel-Wallace is a Software program Improvement Engineer at AWS Lex. He enjoys working leveraging know-how to maximise buyer success. Exterior of labor he’s enthusiastic about cooking, spending time with associates, and backpacking.
Max Henkel-Wallace is a Software program Improvement Engineer at AWS Lex. He enjoys working leveraging know-how to maximise buyer success. Exterior of labor he’s enthusiastic about cooking, spending time with associates, and backpacking.
 Track Feng is a Senior Utilized Scientist at AWS AI Labs, specializing in Pure Language Processing and Synthetic Intelligence. Her analysis explores numerous facets of those fields together with document-grounded dialogue modeling, reasoning for task-oriented dialogues, and interactive textual content technology utilizing multimodal knowledge.
Track Feng is a Senior Utilized Scientist at AWS AI Labs, specializing in Pure Language Processing and Synthetic Intelligence. Her analysis explores numerous facets of those fields together with document-grounded dialogue modeling, reasoning for task-oriented dialogues, and interactive textual content technology utilizing multimodal knowledge.
 Saket Saurabh is an engineer with AWS Lex staff. He works on enhancing Lex developer expertise to assist builders construct extra human-like chat bots. Exterior of labor, he enjoys touring, discovering numerous cuisines, and study totally different cultures.
Saket Saurabh is an engineer with AWS Lex staff. He works on enhancing Lex developer expertise to assist builders construct extra human-like chat bots. Exterior of labor, he enjoys touring, discovering numerous cuisines, and study totally different cultures.



