Unlocking AI Potential with MINILLM: A Deep Dive into Information Distillation from Bigger Language Fashions to Smaller Counterparts
Information distillation which includes coaching a small pupil mannequin below the supervision of an enormous trainer mannequin is a typical technique to lower extreme computational useful resource demand as a result of quick growth of enormous language fashions. Black-box KD, by which solely the trainer’s predictions are accessible, and white-box KD, by which the trainer’s parameters are used, are the 2 sorts of KD which can be typically used. Black-box KD has just lately demonstrated encouraging outcomes in optimizing tiny fashions on the prompt-response pairs produced by LLM APIs. White-box KD turns into more and more useful for analysis communities and industrial sectors when extra open-source LLMs are developed since pupil fashions get higher alerts from white-box teacher fashions, probably resulting in improved efficiency.
Whereas white-box KD for generative LLMs has not but been investigated, it’s principally examined for small (1B parameters) language understanding fashions. They give the impression of being into white-box KD of LLMs on this paper. They contend that the widespread KD may very well be higher for LLMs that perform duties generatively. Normal KD targets (together with a number of variants for sequence-level fashions) basically decrease the approximated ahead Kullback-Leibler divergence (KLD) between the trainer and the scholar distribution, often called KL, forcing p to cowl all of the modes of q given the trainer distribution p(y|x) and the scholar distribution q(y|x)parameterized by. KL performs nicely for textual content classification issues as a result of the output area typically accommodates finite-number lessons, making certain that each p(y|x) and q(y|x) have a small variety of modes.
Nonetheless, for open textual content era issues, the place the output areas are way more sophisticated, p(y|x) could signify a considerably wider vary of modes than q(y|x). Throughout free-run era, minimizing ahead KLD can result in q giving the void areas of p excessively excessive likelihood and producing extremely inconceivable samples below p. They counsel minimizing the reverse KLD, KL, which is usually employed in pc imaginative and prescient and reinforcement studying, to unravel this situation. A pilot experiment reveals how underestimating KL drives q to hunt the foremost modes of p and provides its vacant areas a low likelihood.
Which means within the language era of LLMs, the scholar mannequin avoids studying too many long-tail variations of the teacher distribution and concentrates on the produced response’s accuracy, which is essential in real-world conditions the place honesty and dependability are required. They generate the gradient of the target with Coverage Gradient to optimize min KL. Current research have demonstrated the effectiveness of coverage optimization in optimizing PLMs. Nonetheless, in addition they found that coaching the mannequin nonetheless suffers from extreme variation, reward hacking, and era size bias. Consequently, they embody:
- Single-step regularisation to reduce variation.
- Instructor-mixed sampling to reduce reward hacking.
- Size normalization to scale back size bias.
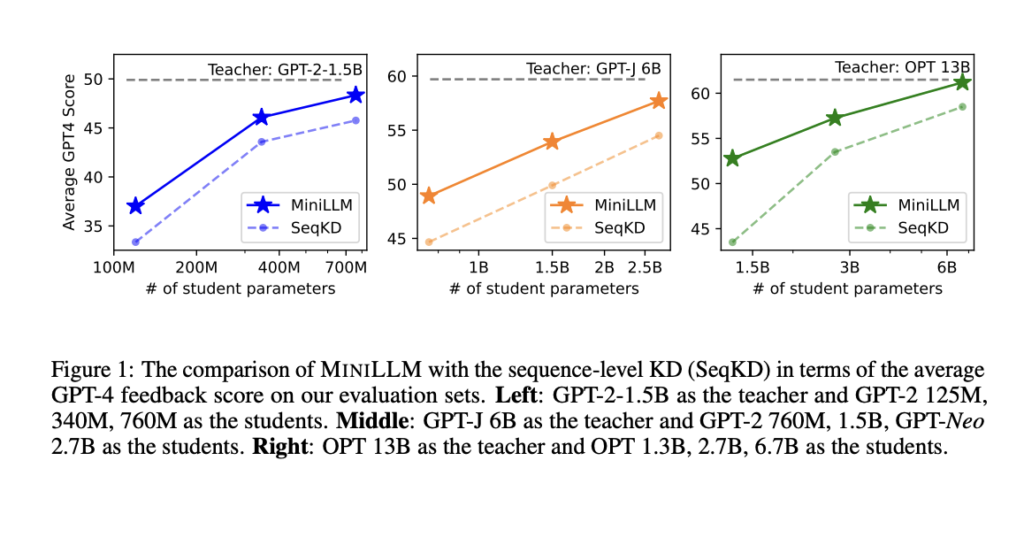
Within the instruction-following setting, which encompasses a variety of NLP duties, researchers from The CoAI Group, Tsinghua College, and Microsoft Analysis supply a novel method known as MINILLM, which they then apply to a number of generative language fashions with parameter sizes starting from 120M to 13B. 5 instruction-following datasets and Rouge-L and GPT-4 suggestions for evaluation are used. Their assessments show that MINILM scales up efficiently from 120M to 13B fashions and persistently beats the baseline commonplace KD fashions on all datasets (see Determine 1). Extra analysis reveals that MINILLM works higher at producing lengthier replies with extra selection and has lowered publicity bias and higher calibration. The fashions can be found on GitHub.

Verify Out The Paper and Github link. Don’t overlook to hitch our 24k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI tasks, and extra. In case you have any questions concerning the above article or if we missed something, be at liberty to e-mail us at Asif@marktechpost.com
Featured Instruments From AI Tools Club
🚀 Check Out 100’s AI Tools in AI Tools Club
Aneesh Tickoo is a consulting intern at MarktechPost. He’s at present pursuing his undergraduate diploma in Information Science and Synthetic Intelligence from the Indian Institute of Know-how(IIT), Bhilai. He spends most of his time engaged on tasks aimed toward harnessing the ability of machine studying. His analysis curiosity is picture processing and is captivated with constructing options round it. He loves to attach with individuals and collaborate on fascinating tasks.



