AWS Inferentia2 builds on AWS Inferentia1 by delivering 4x greater throughput and 10x decrease latency

The dimensions of the machine studying (ML) fashions––giant language fashions (LLMs) and basis fashions (FMs)––is growing fast year-over-year, and these fashions want sooner and extra highly effective accelerators, particularly for generative AI. AWS Inferentia2 was designed from the bottom as much as ship greater efficiency whereas decreasing the price of LLMs and generative AI inference.
On this publish, we present how the second era of AWS Inferentia builds on the capabilities launched with AWS Inferentia1 and meets the distinctive calls for of deploying and operating LLMs and FMs.
The primary era of AWS Inferentia, a purpose-built accelerator launched in 2019, is optimized to speed up deep studying inference. AWS Inferentia helped ML customers cut back their inference prices and enhance their prediction throughput and latency. With AWS Inferentia1, clients noticed as much as 2.3x greater throughput and as much as 70% decrease value per inference than comparable inference-optimized Amazon Elastic Compute Cloud (Amazon EC2) cases.
AWS Inferentia2, featured within the new Amazon EC2 Inf2 instances and supported in Amazon SageMaker, is optimized for large-scale generative AI inference and is the primary inference targeted occasion from AWS that’s optimized for distributed inference, with high-speed, low-latency connectivity between accelerators.
Now you can effectively deploy a 175-billion-parameter mannequin for inference throughout a number of accelerators on a single Inf2 occasion with out requiring costly coaching cases. Till now, clients who had giant fashions may solely use cases that had been constructed for coaching, however it is a waste of sources––provided that they’re costlier, devour extra power, and their workload doesn’t make use of all of the accessible sources (comparable to sooner networking and storage). With AWS Inferentia2, you may obtain 4 occasions greater throughput and as much as 10 occasions decrease latency in comparison with AWS Inferentia1. Additionally, the second era of AWS Inferentia provides enhanced help for extra information sorts, customized operators, dynamic tensors, and extra.
AWS Inferentia2 has 4 occasions extra reminiscence capability, 16.4 occasions greater reminiscence bandwidth than AWS Inferentia1, and native help for sharding giant fashions throughout a number of accelerators. The accelerators use NeuronLink and Neuron Collective Communication to maximise the velocity of information switch between them or between an accelerator and the community adapter. AWS Inferentia2 is healthier fitted to bigger fashions, which require sharding throughout a number of accelerators, though AWS Inferentia1 remains to be an incredible possibility for smaller fashions as a result of it offers higher price-performance in comparison with options.
Structure evolution
To match each generations of AWS Inferentia, let’s evaluation the architecture of AWS Inferentia1. It has 4 NeuronCores v1 per chip, proven within the following diagram.

Specs per chip:
- Compute – 4 cores delivering in complete 128 INT8 TOPS and 64FP16/BF16 TFLOPS
- Reminiscence – 8 GB of DRAM (50 GB/sec of bandwidth), shared by all 4 cores
- NeuronLink – Hyperlink between cores for sharding fashions throughout two or extra cores
Let’s have a look at how AWS Inferentia2 is organized. Every AWS Inferentia2 chip has two upgraded cores primarily based on the NeuronCore-v2 architecture. Like AWS Inferentia1, you may run totally different fashions on every NeuronCore or mix a number of cores to shard large fashions.
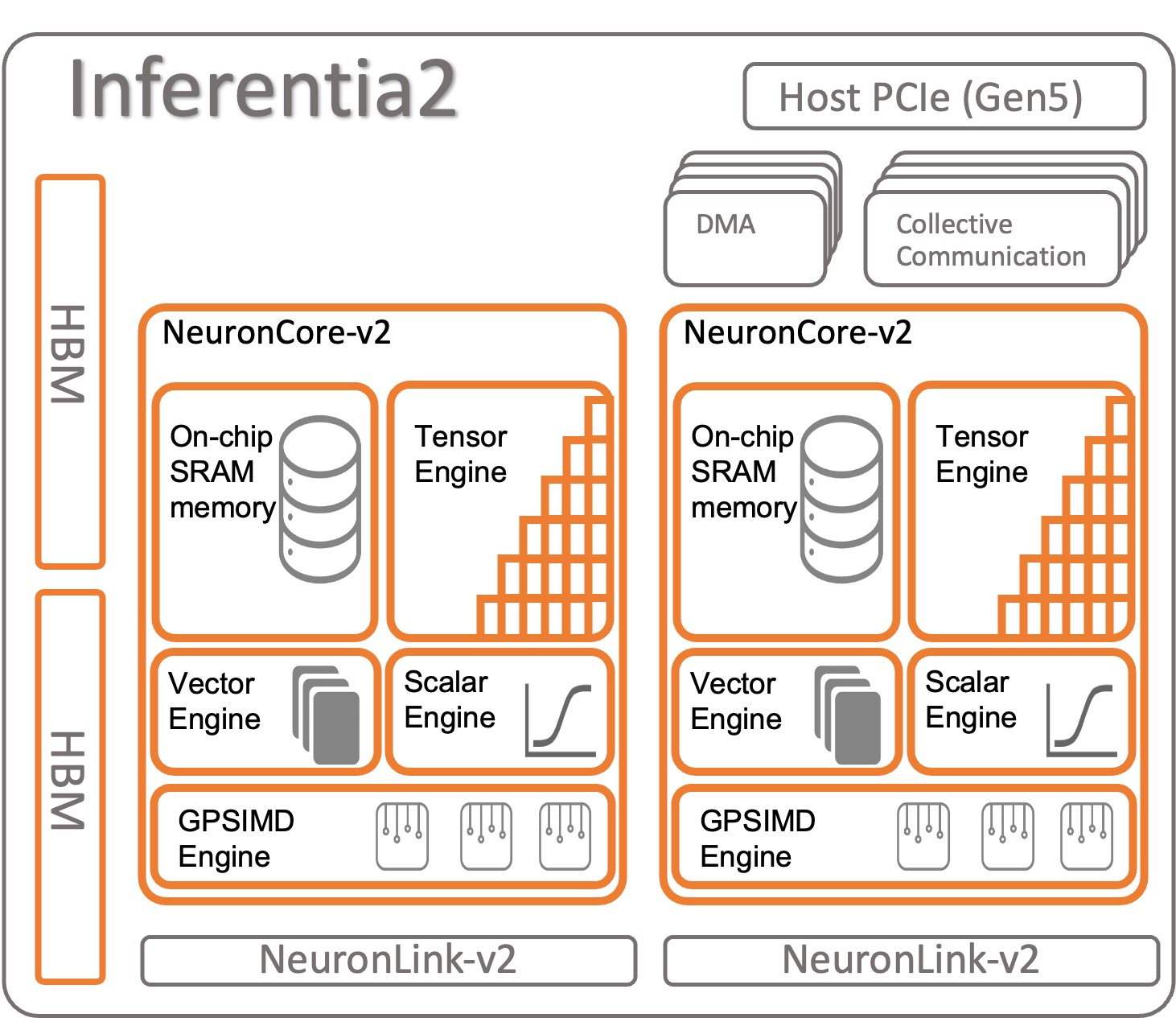
Specs per chip:
- Compute – Two cores delivering in complete 380 INT8 TOPS, 190 FP16/BF16/cFP8/TF32 TFLOPS, and 47.5 FP32 TFLOPS
- Reminiscence – 32 GB of HBM, shared by each cores
- NeuronLink – Hyperlink between chips (384 GB/sec per gadget) for sharding fashions throughout two or extra cores
NeuronCore-v2 has a modular design with four independent engines:
- ScalarEngine (3 occasions sooner than v1) – Operates on floating level numbers––1600 (BF16/FP16) FLOPS
- VectorEngine (10 occasions sooner than v1) – Operates on vectors of numbers with single operation for computations comparable to normalization, pooling, and others.
- TensorEngine (6 occasions sooner than v1) – Performs tensor computations comparable to Conv, Reshape, Transpose, and others.
- GPSIMD-Engine – Has eight totally programmable 512-bit large general-purpose processors so that you can create your custom operators with standard PyTorch custom C++ operators API. It is a new function, launched in NeuronCore-v2.
AWS Inferentia2 NeuronCore-v2 is quicker and extra optimized. Additionally, it’s able to accelerating differing types and sizes of fashions, starting from easy fashions comparable to ResNet 50 to giant language fashions or basis fashions with billions of parameters comparable to GPT-3 (175 billion parameters). AWS Inferentia2 additionally has a bigger and sooner inside reminiscence, when in comparison with AWS Inferentia1, as proven within the following desk.
| Chip | Neuron Cores | Reminiscence Kind | Reminiscence Measurement | Reminiscence Bandwidth |
| AWS Inferentia | x4 (v1) | DDR4 | 8GB | 50GB/S |
| AWS Inferentia 2 | x2 (v2) | HBM | 32GB | 820GB/S |
The reminiscence you discover in AWS Inferentia2 is the sort Excessive-Bandwidth Reminiscence (HBM) kind. Every AWS Inferentia2 chip has 32 GB and that may be mixed with different chips to distribute very giant fashions utilizing NeuronLink (device-to-device interconnect). An inf2.48xlarge, for example, has 12 AWS Inferentia2 accelerators with a complete of 384 GB of accelerated reminiscence. The velocity of AWS Inferentia2 reminiscence is 16.4 occasions sooner than AWS Inferentia1, as proven within the earlier desk.
Different options
AWS Inferentia2 affords the next further options:
- {Hardware} supported – cFP8 (new, configurable FP8), FP16, BF16, TF32, FP32, INT8, INT16 and INT32. For extra data, confer with Data Types.
- Lazy Tensor inference – We talk about Lazy Tensor inference later on this publish.
- Customized operators – Builders can use customary PyTorch customized operators programming interfaces to make use of the Custom C++ Operators function. A customized operator consists of low-level primitives accessible within the Tensor Factory Functions and accelerated by GPSIMD-Engine.
- Management-flow (coming quickly) – That is for native programming language management move contained in the mannequin to finally preprocess and postprocess information from one layer to a different.
- Dynamic-shapes (coming quickly) – That is helpful when your mannequin adjustments the form of the output of any inside layer dynamically. As an example: a filter which reduces the output tensor measurement or form contained in the mannequin, primarily based on the enter information.
Accelerating fashions on AWS Inferentia1 and AWS Inferentia2
The AWS Neuron SDK is used for compiling and operating your mannequin. It’s natively built-in with PyTorch and TensorFlow. That method, you don’t must run a further instrument. Use your unique code, written in one in every of these ML frameworks, and with a number of strains of code adjustments, you’re good to go along with AWS Inferentia.
Let’s have a look at easy methods to compile and run a mannequin on AWS Inferentia1 and AWS Inferentia2 utilizing PyTorch.
Load a pre-trained mannequin (ResNet 50) from torchvision
Load a pre-trained mannequin and run it one time to heat it up:
Hint and deploy the accelerated mannequin on Inferentia1
To hint the mannequin to AWS Inferentia, import torch_neuron and invoke the tracing perform. Remember the fact that the mannequin must be PyTorch Jit traceable to work.
On the finish of the tracing course of, save the mannequin as a traditional PyTorch mannequin. Compile the mannequin one time and cargo it again as many occasions as you want. The Neuron SDK runtime is already built-in to PyTorch and is chargeable for sending the operators to the AWS Inferentia1 chip robotically to speed up your mannequin.
In your inference code, you all the time must import torch_neuron to activate the built-in runtime.
You may move additional parameters to the compiler to customise the way in which it optimizes the mannequin or to allow particular options comparable to neuron-pipeline-cores. Shard your mannequin throughout a number of cores to extend throughput.
Tracing and deploying the accelerated mannequin on Inferentia2
For AWS Inferentia2, the method is comparable. The one distinction is the package deal you import ends with x: torch_neuronx. The Neuron SDK takes care of the compilation and operating of the mannequin for you transparently. You can too move additional parameters to the compiler to fine-tune the operation or activate particular functionalities.
AWS Inferentia2 additionally affords a second strategy for operating a mannequin known as Lazy Tensor inference. On this mode, you don’t hint or compile the mannequin beforehand; as an alternative, the compiler runs on the fly each time you run your code. It isn’t really useful for manufacturing, provided that traced mode has many advantages over Lazy Tensor inference. Nonetheless, for those who’re nonetheless creating your mannequin and wish to check it sooner, Lazy Tensor inference could be a good various. Right here’s easy methods to compile and run a mannequin utilizing Lazy Tensor:
Now that you simply’re conversant in AWS Inferentia2, subsequent step is to get began with PyTorch or Tensorflow and discover ways to arrange a dev surroundings and run tutorials and examples. Additionally, test the AWS Neuron Samples GitHub repo, the place yow will discover a number of examples of easy methods to put together fashions to run on Inf2, Inf1, and Trn1.
Abstract of function comparability between AWS Inferentia1 and AWS Inferentia2
The AWS Inferentia2 compiler is XLA-based, and AWS is a part of OpenXLA initiative. That is the largest distinction over AWS Inferentia1, and that’s related as a result of PyTorch, TensorFlow, and JAX have native XLA integrations. XLA brings many efficiency enhancements, provided that it optimizes the graph to compute the ends in a single kernel launch. It fuses collectively successive tensor operations and outputs optimum machine code for accelerating mannequin runs on AWS Inferentia2. Different components of the Neuron SDK had been additionally improved in AWS Inferentia2, whereas retaining the consumer expertise so simple as attainable whereas tracing and operating fashions. The next desk reveals the options accessible in each variations of the compiler and runtime.
| Function | torch-neuron | torch-neuronx |
| Tensorboard | Sure | Sure |
| Supported Situations | Inf1 | Inf2 & Trn1 |
| Inference Help | Sure | Sure |
| Coaching Help | No | Sure |
| Structure | NeuronCore-v1 | NeuronCore-v2 |
| Hint API | torch_neuron.hint() | torch_neuronx.hint() |
| Distributed inference | NeuronCore Pipeline | Collective Communications |
| IR | GraphDef | HLO |
| Compiler | neuron-cc | neuronx-cc |
| Monitoring | neuron-monitor / monitor-top | neuron-monitor / monitor-top |
For a extra detailed comparability between torch-neuron (Inf1) and torch-neuronx (Inf2), confer with Comparison of torch-neuron (Inf1) versus torch-neuronx (Inf2 & Trn1) for Inference.
Mannequin Serving
After tracing a mannequin to deploy to Inf2, you may have many deployment choices. You may run real-time predictions or batch predictions in numerous methods. Inf2 is accessible as a result of EC2 cases are natively built-in to different AWS providers that make use of Deep Learning Containers (DLCs) comparable to Amazon Elastic Container Service (Amazon ECS), Amazon Elastic Kubernetes Service (Amazon EKS), and SageMaker.
AWS Inferentia2 is appropriate with the most well-liked deployment applied sciences. Listed below are a listing of a number of the choices you may have for deploying fashions utilizing AWS Inferentia2:
- SageMaker – Absolutely managed service to organize information and construct, practice, and deploy ML fashions
- TorchServe – PyTorch built-in deployment mechanism
- TensorFlow Serving – TensorFlow built-in deployment mechanism
- Deep Java Library – Open-source Java mechanism for mannequin deployment and coaching
- Triton – NVIDIA open-source service for mannequin deployment
Benchmark
The next desk highlights the enhancements AWS Inferentia2 brings over AWS Inferentia1. Particularly, we measure latency (how briskly the mannequin could make a prediction utilizing every accelerator), throughput (what number of inferences per second), and price per inference (how a lot every inference prices in US {dollars}). The decrease the latency in milliseconds and prices in US {dollars}, the higher. The upper the throughput the higher.
Two fashions had been used on this course of––each giant language fashions: ELECTRA giant discriminator and BERT giant uncased. PyTorch (1.13.1) and Hugging Face transformers (v4.7.0), the principle libraries used on this experiment, ran on Python 3.8. After compiling the fashions for batch measurement = 1 and 10 (utilizing the code from the earlier part as a reference), every mannequin was warmed up (invoked one time to initialize the context) after which invoked 10 occasions in a row. The next desk reveals common numbers collected on this easy benchmark.
| Mannequin Identify | Batch Measurement | Sentence Size | Latency (ms) | Enhancements Inf2 over Inf1 (x Occasions) | Throughput (Inferences per Second) | Value per Inference (EC2 us-east-1) ** | |||
| Inf1 | Inf2 | Inf1 | Inf2 | Inf1 | Inf2 | ||||
| ElectraLargeDiscriminator | 1 | 256 | 35.7 | 8.31 | 4.30 | 28.01 | 120.34 | $0.0000023 | $0.0000018 |
| ElectraLargeDiscriminator | 10 | 256 | 343.7 | 72.9 | 4.71 | 2.91 | 13.72 | $0.0000022 | $0.0000015 |
| BertLargeUncased | 1 | 128 | 28.2 | 3.1 | 9.10 | 35.46 | 322.58 | $0.0000018 | $0.0000007 |
| BertLargeUncased | 10 | 128 | 121.1 | 23.6 | 5.13 | 8.26 | 42.37 | $0.0000008 | $0.0000005 |
* c6a.8xlarge with 32 AMD Epyc 7313 CPU was used on this benchmark.
**EC2 Public pricing in us-east-1 on April 20: inf2.xlarge: $0.7582/hr; inf1.xlarge: $0.228/hr. Value per inference considers the price per component in a batch. (Value per inference equals the whole value of mannequin invocation/batch measurement.)
For added details about coaching and inference efficiency, confer with Trn1/Trn1n Performance.
Conclusion
AWS Inferentia2 is a robust know-how designed for enhancing efficiency and decreasing prices of deep studying mannequin inference. Extra performant than AWS Inferentia1, it affords as much as 4 occasions greater throughput, as much as 10 occasions decrease latency, and as much as 50% higher efficiency/watt than different comparable inference-optimized EC2 cases. In the long run, you pay much less, have a sooner software, and meet your sustainability targets.
It’s easy and simple emigrate your inference code to AWS Inferentia2, which additionally helps a broader number of fashions, together with giant language fashions and basis fashions for generative AI.
You may get began by following the AWS Neuron SDK documentation to arrange a growth surroundings and begin your accelerated deep studying mission. That can assist you get began, Hugging Face has added Neuron help to their Optimum library, which optimizes fashions for sooner coaching and inference, and so they have many examples duties able to run on Inf2. Additionally, test our Deploy large language models on AWS Inferentia2 using large model inference containers to find out about deploying LLMs to AWS Inferentia2 utilizing mannequin inference containers. For added examples, see the AWS Neuron Samples GitHub repo.
Concerning the authors
 Samir Araújo is an AI/ML Options Architect at AWS. He helps clients creating AI/ML options which clear up their enterprise challenges utilizing AWS. He has been engaged on a number of AI/ML tasks associated to pc imaginative and prescient, pure language processing, forecasting, ML on the edge, and extra. He likes taking part in with {hardware} and automation tasks in his free time, and he has a selected curiosity for robotics.
Samir Araújo is an AI/ML Options Architect at AWS. He helps clients creating AI/ML options which clear up their enterprise challenges utilizing AWS. He has been engaged on a number of AI/ML tasks associated to pc imaginative and prescient, pure language processing, forecasting, ML on the edge, and extra. He likes taking part in with {hardware} and automation tasks in his free time, and he has a selected curiosity for robotics.





