High-quality-tune GPT-J utilizing an Amazon SageMaker Hugging Face estimator and the mannequin parallel library

GPT-J is an open-source 6-billion-parameter mannequin launched by Eleuther AI. The mannequin is skilled on the Pile and might carry out numerous duties in language processing. It could help all kinds of use instances, together with textual content classification, token classification, textual content era, query and answering, entity extraction, summarization, sentiment evaluation, and lots of extra. GPT-J is a transformer mannequin skilled utilizing Ben Wang’s Mesh Transformer JAX.
On this submit, we current a information and finest practices on coaching giant language fashions (LLMs) utilizing the Amazon SageMaker distributed mannequin parallel library to scale back coaching time and value. You’ll learn to prepare a 6-billion-parameter GPT-J mannequin on SageMaker with ease. Lastly, we share the principle options of SageMaker distributed mannequin parallelism that assist with rushing up coaching time.
Transformer neural networks
A transformer neural community is a well-liked deep studying structure to unravel sequence-to-sequence duties. It makes use of attention as the educational mechanism to realize near human-level efficiency. A number of the different helpful properties of the structure in comparison with earlier generations of pure language processing (NLP) fashions embrace the flexibility distribute, scale, and pre-train. Transformers-based fashions may be utilized throughout completely different use instances when coping with textual content knowledge, corresponding to search, chatbots, and lots of extra. Transformers use the idea of pre-training to realize intelligence from giant datasets. Pre-trained transformers can be utilized as is or fine-tuned in your datasets, which may be a lot smaller and particular to your corporation.
Hugging Face on SageMaker
Hugging Face is an organization growing a number of the hottest open-source libraries offering state-of-the-art NLP expertise primarily based on transformers architectures. The Hugging Face transformers, tokenizers, and datasets libraries present APIs and instruments to obtain and predict utilizing pre-trained fashions in a number of languages. SageMaker allows you to prepare, fine-tune, and run inference utilizing Hugging Face fashions instantly from its Hugging Face Model Hub utilizing the Hugging Face estimator within the SageMaker SDK. The mixing makes it simpler to customise Hugging Face fashions on domain-specific use instances. Behind the scenes, the SageMaker SDK makes use of AWS Deep Studying Containers (DLCs), that are a set of prebuilt Docker photographs for coaching and serving fashions provided by SageMaker. The DLCs are developed by way of a collaboration between AWS and Hugging Face. The mixing additionally gives integration between the Hugging Face transformers SDK and SageMaker distributed training libraries, enabling you to scale your coaching jobs on a cluster of GPUs.
Overview of the SageMaker distributed mannequin parallel library
Mannequin parallelism is a distributed coaching technique that partitions the deep studying mannequin over quite a few units, inside or throughout situations. Deep studying (DL) fashions with extra layers and parameters carry out higher in advanced duties like laptop imaginative and prescient and NLP. Nonetheless, the utmost mannequin measurement that may be saved within the reminiscence of a single GPU is proscribed. GPU reminiscence constraints may be bottlenecks whereas coaching DL fashions within the following methods:
- They restrict the scale of the mannequin that may be skilled as a result of a mannequin’s reminiscence footprint scales proportionately to the variety of parameters
- They scale back GPU utilization and coaching effectivity by limiting the per-GPU batch measurement throughout coaching
SageMaker contains the distributed mannequin parallel library to assist distribute and prepare DL fashions successfully throughout many compute nodes, overcoming the restrictions related to coaching a mannequin on a single GPU. Moreover, the library permits you to get hold of essentially the most optimum distributed coaching using EFA-supported units, which improves inter-node communication efficiency with low latency, excessive throughput, and OS bypass.
As a result of giant fashions corresponding to GPT-J, with billions of parameters, have a GPU reminiscence footprint that exceeds a single chip, it turns into important to partition them throughout a number of GPUs. The SageMaker mannequin parallel (SMP) library allows automated partitioning of fashions throughout a number of GPUs. With SageMaker mannequin parallelism, SageMaker runs an preliminary profiling job in your behalf to research the compute and reminiscence necessities of the mannequin. This info is then used to resolve how the mannequin is partitioned throughout GPUs, with a view to maximize an goal, corresponding to maximizing velocity or minimizing reminiscence footprint.
It additionally helps optionally available pipeline run scheduling with a view to maximize the general utilization of obtainable GPUs. The propagation of activations throughout ahead go and gradients throughout backward go requires sequential computation, which limits the quantity of GPU utilization. SageMaker overcomes the sequential computation constraint using the pipeline run schedule by splitting mini-batches into micro-batches to be processed in parallel on completely different GPUs. SageMaker mannequin parallelism helps two modes of pipeline runs:
- Easy pipeline – This mode finishes the ahead go for every micro-batch earlier than beginning the backward go.
- Interleaved pipeline – On this mode, the backward run of the micro-batches is prioritized every time potential. This permits for faster launch of the reminiscence used for activations, thereby utilizing reminiscence extra effectively.
Tensor parallelism
Particular person layers, ornn.Modules, are divided throughout units utilizing tensor parallelism to allow them to run concurrently. The best instance of how the library divides a mannequin with 4 layers to realize two-way tensor parallelism ("tensor_parallel_degree": 2) is proven within the following determine. Every mannequin duplicate’s layers are bisected (divided in half) and distributed between two GPUs. The diploma of information parallelism is eight on this instance as a result of the mannequin parallel configuration moreover contains "pipeline_parallel_degree": 1 and "ddp": True. The library manages communication among the many replicas of the tensor-distributed mannequin.
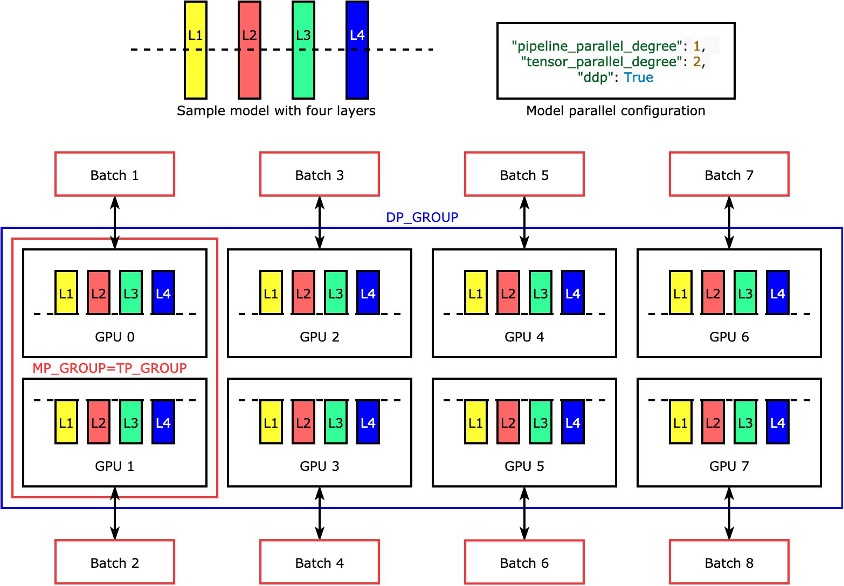
The advantage of this function is that you could be select which layers or which subset of layers you need to apply tensor parallelism to. To dive deep into tensor parallelism and different memory-saving options for PyTorch, and to learn to arrange a mixture of pipeline and tensor parallelism, see Extended Features of the SageMaker Model Parallel Library for PyTorch.
SageMaker sharded knowledge parallelism
Sharded knowledge parallelism is a memory-saving distributed coaching approach that splits the coaching state of a mannequin (mannequin parameters, gradients, and optimizer states) throughout GPUs in a knowledge parallel group.
When scaling up your coaching job to a big GPU cluster, you possibly can scale back the per-GPU reminiscence footprint of the mannequin by sharding the coaching state over a number of GPUs. This returns two advantages: you possibly can match bigger fashions, which might in any other case run out of reminiscence with normal knowledge parallelism, or you possibly can improve the batch measurement utilizing the freed-up GPU reminiscence.
The usual knowledge parallelism approach replicates the coaching states throughout the GPUs within the knowledge parallel group and performs gradient aggregation primarily based on the AllReduce operation. In impact, sharded knowledge parallelism introduces a trade-off between the communication overhead and GPU reminiscence effectivity. Utilizing sharded knowledge parallelism will increase the communication value, however the reminiscence footprint per GPU (excluding the reminiscence utilization as a result of activations) is split by the sharded knowledge parallelism diploma, due to this fact bigger fashions can slot in a GPU cluster.
SageMaker implements sharded knowledge parallelism by way of the MiCS implementation. For extra info, see Near-linear scaling of gigantic-model training on AWS.
Confer with Sharded Data Parallelism for additional particulars on easy methods to apply sharded knowledge parallelism to your coaching jobs.
Use the SageMaker mannequin parallel library
The SageMaker mannequin parallel library comes with the SageMaker Python SDK. You want to set up the SageMaker Python SDK to make use of the library, and it’s already put in on SageMaker pocket book kernels. To make your PyTorch coaching script make the most of the capabilities of the SMP library, it is advisable make the next modifications:
- Strat by importing and initializing the
smplibrary utilizing thesmp.init()name. - As soon as it’s initialized, you possibly can wrap your mannequin with the
smp.DistributedModelwrapper and use the returnedDistributedModelobject as an alternative of the consumer mannequin. - To your optimizer state, use the
smp.DistributedOptimizerwrapper round your mannequin optimizer, enablingsmpto avoid wasting and cargo the optimizer state. The ahead and backward go logic may be abstracted as a separate operate and add asmp.stepdecorator to the operate. Primarily, the ahead go and back-propagation must be run contained in the operate with thesmp.stepdecorator positioned over it. This permitssmpto separate the tensor enter to the operate into numerous microbatches specified whereas launching the coaching job. - Subsequent, we will transfer the enter tensors to the GPU utilized by the present course of utilizing the
torch.cuda.set_deviceAPI adopted by the.to()API name. - Lastly, for back-propagation, we change
torch.Tensor.backwardandtorch.autograd.backward.
See the next code:
The SageMaker mannequin parallel library’s tensor parallelism gives out-of-the-box support for the next Hugging Face Transformer fashions:
- GPT-2, BERT, and RoBERTa (out there within the SMP library v1.7.0 and later)
- GPT-J (out there within the SMP library v1.8.0 and later)
- GPT-Neo (out there within the SMP library v1.10.0 and later)
Finest practices for efficiency tuning with the SMP library
When coaching giant fashions, contemplate the next steps in order that your mannequin matches in GPU reminiscence with an affordable batch measurement:
- It’s beneficial to make use of situations with increased GPU reminiscence and excessive bandwidth interconnect for efficiency, corresponding to p4d and p4de situations.
- Optimizer state sharding may be enabled typically, and might be useful when you might have multiple copy of the mannequin (knowledge parallelism enabled). You may activate optimizer state sharding by setting
"shard_optimizer_state": Truewithin themodelparallelconfiguration. - Use activation checkpointing, a way to scale back reminiscence utilization by clearing activations of sure layers and recomputing them throughout a backward go of chosen modules within the mannequin.
- Use activation offloading, an extra function that may additional scale back reminiscence utilization. To make use of activation offloading, set
"offload_activations": Truewithin themodelparallelconfiguration. Use when activation checkpointing and pipeline parallelism are turned on and the variety of microbatches is larger than one. - Allow tensor parallelism and improve parallelism levels the place the diploma is an influence of two. Usually for efficiency causes, tensor parallelism is restricted to inside a node.
We now have run many experiments to optimize coaching and tuning GPT-J on SageMaker with the SMP library. We now have managed to scale back GPT-J coaching time for an epoch on SageMaker from 58 minutes to lower than 10 minutes—six instances sooner coaching time per epoch. It took initialization, mannequin and dataset obtain from Amazon Simple Storage Service (Amazon S3) lower than a minute, tracing and auto partitioning with GPU because the tracing system lower than 1 minute, and coaching an epoch 8 minutes utilizing tensor parallelism on one ml.p4d.24xlarge occasion, FP16 precision, and a SageMaker Hugging Face estimator.
To cut back coaching time as a finest observe, when coaching GPT-J on SageMaker, we advocate the next:
- Retailer your pretrained mannequin on Amazon S3
- Use FP16 precision
- Use GPU as a tracing system
- Use auto-partitioning, activation checkpointing, and optimizer state sharding:
auto_partition: Trueshard_optimizer_state: True
- Use tensor parallelism
- Use a SageMaker coaching occasion with a number of GPUs corresponding to ml.p3.16xlarge, ml.p3dn.24xlarge, ml.g5.48xlarge, ml.p4d.24xlarge, or ml.p4de.24xlarge.
GPT-J mannequin coaching and tuning on SageMaker with the SMP library
A working step-by-step code pattern is offered on the Amazon SageMaker Examples public repository. Navigate to the training/distributed_training/pytorch/model_parallel/gpt-j folder. Choose the gpt-j folder and open the train_gptj_smp_tensor_parallel_notebook.jpynb Jupyter pocket book for the tensor parallelism instance and train_gptj_smp_notebook.ipynb for the pipeline parallelism instance. You could find a code walkthrough in our Generative AI on Amazon SageMaker workshop.
This pocket book walks you thru easy methods to use the tensor parallelism options offered by the SageMaker mannequin parallelism library. You’ll learn to run FP16 coaching of the GPT-J mannequin with tensor parallelism and pipeline parallelism on the GLUE sst2 dataset.
Abstract
The SageMaker mannequin parallel library gives a number of functionalities. You may scale back value and velocity up coaching LLMs on SageMaker. You may as well be taught and run pattern codes for BERT, GPT-2, and GPT-J on the Amazon SageMaker Examples public repository. To be taught extra about AWS finest practices for coaching LLMS utilizing the SMP library, consult with the next assets:
To learn the way one among our clients achieved low-latency GPT-J inference on SageMaker, consult with How Mantium achieves low-latency GPT-J inference with DeepSpeed on Amazon SageMaker.
In the event you’re trying to speed up time-to-market of your LLMs and scale back your prices, SageMaker might help. Tell us what you construct!
In regards to the Authors
 Zmnako Awrahman, PhD, is a Follow Supervisor, ML SME, and Machine Studying Technical Subject Group (TFC) member at International Competency Heart, Amazon Internet Providers. He helps clients leverage the facility of the cloud to extract worth from their knowledge with knowledge analytics and machine studying.
Zmnako Awrahman, PhD, is a Follow Supervisor, ML SME, and Machine Studying Technical Subject Group (TFC) member at International Competency Heart, Amazon Internet Providers. He helps clients leverage the facility of the cloud to extract worth from their knowledge with knowledge analytics and machine studying.
 Roop Bains is a Senior Machine Studying Options Architect at AWS. He’s captivated with serving to clients innovate and obtain their enterprise aims utilizing synthetic intelligence and machine studying. He helps clients prepare, optimize, and deploy deep studying fashions.
Roop Bains is a Senior Machine Studying Options Architect at AWS. He’s captivated with serving to clients innovate and obtain their enterprise aims utilizing synthetic intelligence and machine studying. He helps clients prepare, optimize, and deploy deep studying fashions.
 Anastasia Pachni Tsitiridou is a Options Architect at AWS. Anastasia lives in Amsterdam and helps software program companies throughout the Benelux area of their cloud journey. Previous to becoming a member of AWS, she studied electrical and laptop engineering with a specialization in laptop imaginative and prescient. What she enjoys most these days is working with very giant language fashions.
Anastasia Pachni Tsitiridou is a Options Architect at AWS. Anastasia lives in Amsterdam and helps software program companies throughout the Benelux area of their cloud journey. Previous to becoming a member of AWS, she studied electrical and laptop engineering with a specialization in laptop imaginative and prescient. What she enjoys most these days is working with very giant language fashions.
 Dhawal Patel is a Principal Machine Studying Architect at AWS. He has labored with organizations starting from giant enterprises to mid-sized startups on issues associated to distributed computing and synthetic intelligence. He focuses on deep studying, together with NLP and laptop imaginative and prescient domains. He helps clients obtain high-performance mannequin inference on SageMaker.
Dhawal Patel is a Principal Machine Studying Architect at AWS. He has labored with organizations starting from giant enterprises to mid-sized startups on issues associated to distributed computing and synthetic intelligence. He focuses on deep studying, together with NLP and laptop imaginative and prescient domains. He helps clients obtain high-performance mannequin inference on SageMaker.
 Wioletta Stobieniecka is a Knowledge Scientist at AWS Skilled Providers. All through her skilled profession, she has delivered a number of analytics-driven initiatives for various industries corresponding to banking, insurance coverage, telco, and the general public sector. Her information of superior statistical strategies and machine studying is properly mixed with a enterprise acumen. She brings current AI developments to create worth for purchasers.
Wioletta Stobieniecka is a Knowledge Scientist at AWS Skilled Providers. All through her skilled profession, she has delivered a number of analytics-driven initiatives for various industries corresponding to banking, insurance coverage, telco, and the general public sector. Her information of superior statistical strategies and machine studying is properly mixed with a enterprise acumen. She brings current AI developments to create worth for purchasers.
 Rahul Huilgol is a Senior Software program Improvement Engineer in Distributed Deep Studying at Amazon Internet Providers.
Rahul Huilgol is a Senior Software program Improvement Engineer in Distributed Deep Studying at Amazon Internet Providers.






