Quick-track graph ML with GraphStorm: A brand new solution to resolve issues on enterprise-scale graphs

We’re excited to announce the open-source launch of GraphStorm 0.1, a low-code enterprise graph machine studying (ML) framework to construct, prepare, and deploy graph ML options on advanced enterprise-scale graphs in days as a substitute of months. With GraphStorm, you’ll be able to construct options that instantly take note of the construction of relationships or interactions between billions of entities, that are inherently embedded in most real-world information, together with fraud detection eventualities, suggestions, group detection, and search/retrieval issues.
Till now, it has been notoriously arduous to construct, prepare, and deploy graph ML options for advanced enterprise graphs that simply have billions of nodes, a whole bunch of billions of edges, and dozens of attributes—simply take into consideration a graph capturing Amazon.com merchandise, product attributes, prospects, and extra. With GraphStorm, we launch the instruments that Amazon makes use of internally to convey large-scale graph ML options to manufacturing. GraphStorm doesn’t require you to be an professional in graph ML and is obtainable below the Apache v2.0 license on GitHub. To be taught extra about GraphStorm, go to the GitHub repository.
On this submit, we offer an introduction to GraphStorm, its structure, and an instance use case of the right way to use it.
Introducing GraphStorm
Graph algorithms and graph ML are rising as state-of-the-art options for a lot of vital enterprise issues like predicting transaction dangers, anticipating buyer preferences, detecting intrusions, optimizing provide chains, social community evaluation, and visitors prediction. For instance, Amazon GuardDuty, the native AWS menace detection service, makes use of a graph with billions of edges to enhance the protection and accuracy of its menace intelligence. This enables GuardDuty to categorize beforehand unseen domains as extremely prone to be malicious or benign primarily based on their affiliation to recognized malicious domains. By utilizing Graph Neural Networks (GNNs), GuardDuty is ready to improve its functionality to alert prospects.
Nonetheless, growing, launching, and working graph ML options takes months and requires graph ML experience. As a primary step, a graph ML scientist has to construct a graph ML mannequin for a given use case utilizing a framework just like the Deep Graph Library (DGL). Coaching such fashions is difficult because of the dimension and complexity of graphs in enterprise purposes, which routinely attain billions of nodes, a whole bunch of billions of edges, totally different node and edge sorts, and a whole bunch of node and edge attributes. Enterprise graphs can require terabytes of reminiscence storage, requiring graph ML scientists to construct advanced coaching pipelines. Lastly, after a mannequin has been educated, they must be deployed for inference, which requires inference pipelines which can be simply as tough to construct because the coaching pipelines.
GraphStorm 0.1 is a low-code enterprise graph ML framework that enables ML practitioners to simply choose predefined graph ML fashions which have been confirmed to be efficient, run distributed coaching on graphs with billions of nodes, and deploy the fashions into manufacturing. GraphStorm presents a set of built-in graph ML fashions, similar to Relational Graph Convolutional Networks (RGCN), Relational Graph Consideration Networks (RGAT), and Heterogeneous Graph Transformer (HGT) for enterprise purposes with heterogeneous graphs, which permit ML engineers with little graph ML experience to check out totally different mannequin options for his or her process and choose the proper one rapidly. Finish-to-end distributed coaching and inference pipelines, which scale to billion-scale enterprise graphs, make it straightforward to coach, deploy, and run inference. If you’re new to GraphStorm or graph ML typically, you’ll profit from the pre-defined fashions and pipelines. If you’re an professional, you have got all choices to tune the coaching pipeline and mannequin structure to get the perfect efficiency. GraphStorm is constructed on prime of the DGL, a broadly well-liked framework for growing GNN fashions, and out there as open-source code below the Apache v2.0 license.
“GraphStorm is designed to assist prospects experiment and operationalize graph ML strategies for trade purposes to speed up the adoption of graph ML,” says George Karypis, Senior Principal Scientist in Amazon AI/ML analysis. “Since its launch inside Amazon, GraphStorm has lowered the trouble to construct graph ML-based options by as much as 5 occasions.”
“GraphStorm allows our workforce to coach GNN embedding in a self-supervised method on a graph with 288 million nodes and a pair of billion edges,” Says Haining Yu, Principal Utilized Scientist at Amazon Measurement, Advert Tech, and Knowledge Science. “The pre-trained GNN embeddings present a 24% enchancment on a consumer exercise prediction process over a state-of-the-art BERT- primarily based baseline; it additionally exceeds benchmark efficiency in different adverts purposes.”
“Earlier than GraphStorm, prospects might solely scale vertically to deal with graphs of 500 million edges,” says Brad Bebee, GM for Amazon Neptune and Amazon Timestream. “GraphStorm allows prospects to scale GNN mannequin coaching on large Amazon Neptune graphs with tens of billions of edges.”
GraphStorm technical structure
The next determine reveals the technical structure of GraphStorm.

GraphStorm is constructed on prime of PyTorch and might run on a single GPU, a number of GPUs, and a number of GPU machines. It consists of three layers (marked within the yellow packing containers within the previous determine):
- Backside layer (Dist GraphEngine) – The underside layer gives the fundamental parts to allow distributed graph ML, together with distributed graphs, distributed tensors, distributed embeddings, and distributed samplers. GraphStorm gives environment friendly implementations of those parts to scale graph ML coaching to billion-node graphs.
- Center layer (GS coaching/inference pipeline) – The center layer gives trainers, evaluators, and predictors to simplify mannequin coaching and inference for each built-in fashions and your customized fashions. Mainly, by utilizing the API of this layer, you’ll be able to concentrate on the mannequin improvement with out worrying about the right way to scale the mannequin coaching.
- High layer (GS normal mannequin zoo) – The highest layer is a mannequin zoo with well-liked GNN and non-GNN fashions for various graph sorts. As of this writing, it gives RGCN, RGAT, and HGT for heterogeneous graphs and BERTGNN for textual graphs. Sooner or later, we’ll add help for temporal graph fashions similar to TGAT for temporal graphs in addition to TransE and DistMult for data graphs.
Find out how to use GraphStorm
After putting in GraphStorm, you solely want three steps to construct and prepare GML fashions on your software.
First, you preprocess your information (doubtlessly together with your customized characteristic engineering) and rework it right into a desk format required by GraphStorm. For every node sort, you outline a desk that lists all nodes of that sort and their options, offering a novel ID for every node. For every edge sort, you equally outline a desk through which every row accommodates the supply and vacation spot node IDs for an fringe of that sort (for extra data, see Use Your Own Data Tutorial). As well as, you present a JSON file that describes the general graph construction.
Second, through the command line interface (CLI), you employ GraphStorm’s built-in construct_graph element for some GraphStorm-specific information processing, which allows environment friendly distributed coaching and inference.
Third, you configure the mannequin and coaching in a YAML file (example) and, once more utilizing the CLI, invoke one of many 5 built-in parts (gs_node_classification, gs_node_regression, gs_edge_classification, gs_edge_regression, gs_link_prediction) as coaching pipelines to coach the mannequin. This step leads to the educated mannequin artifacts. To do inference, that you must repeat the primary two steps to rework the inference information right into a graph utilizing the identical GraphStorm element (construct_graph) as earlier than.
Lastly, you’ll be able to invoke one of many 5 built-in parts, the identical that was used for mannequin coaching, as an inference pipeline to generate embeddings or prediction outcomes.
The general movement can also be depicted within the following determine.
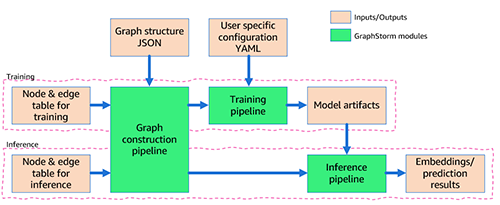
Within the following part, we offer an instance use case.
Make predictions on uncooked OAG information
For this submit, we show how simply GraphStorm can allow graph ML coaching and inference on a big uncooked dataset. The Open Academic Graph (OAG) accommodates 5 entities (papers, authors, venues, affiliations, and area of research). The uncooked dataset is saved in JSON recordsdata with over 500 GB.
Our process is to construct a mannequin to foretell the sector of research of a paper. To foretell the sector of research, you’ll be able to formulate it as a multi-label classification process, but it surely’s tough to make use of one-hot encoding to retailer the labels as a result of there are a whole bunch of hundreds of fields. Due to this fact, you must create area of research nodes and formulate this drawback as a hyperlink prediction process, predicting which area of research nodes a paper node ought to hook up with.
To mannequin this dataset with a graph methodology, step one is to course of the dataset and extract entities and edges. You possibly can extract 5 forms of edges from the JSON recordsdata to outline a graph, proven within the following determine. You need to use the Jupyter pocket book within the GraphStorm example code to course of the dataset and generate 5 entity tables for every entity sort and 5 edge tables for every edge sort. The Jupyter pocket book additionally generates BERT embeddings on the entities with textual content information, similar to papers.

After defining the entities and edges between the entities, you’ll be able to create mag_bert.json, which defines the graph schema, and invoke the built-in graph development pipeline construct_graph in GraphStorm to construct the graph (see the next code). Regardless that the GraphStorm graph development pipeline runs in a single machine, it helps multi-processing to course of nodes and edge options in parallel (--num_processes) and might retailer entity and edge options on exterior reminiscence (--ext-mem-workspace) to scale to massive datasets.
To course of such a big graph, you want a large-memory CPU occasion to assemble the graph. You need to use an Amazon Elastic Compute Cloud (Amazon EC2) r6id.32xlarge occasion (128 vCPU and 1 TB RAM) or r6a.48xlarge situations (192 vCPU and 1.5 TB RAM) to assemble the OAG graph.
After developing a graph, you need to use gs_link_prediction to coach a hyperlink prediction mannequin on 4 g5.48xlarge situations. When utilizing the built-in fashions, you solely invoke one command line to launch the distributed coaching job. See the next code:
After the mannequin coaching, the mannequin artifact is saved within the folder /information/mag_lp_model.
Now you’ll be able to run hyperlink prediction inference to generate GNN embeddings and consider the mannequin efficiency. GraphStorm gives a number of built-in analysis metrics to judge mannequin efficiency. For hyperlink prediction issues, for instance, GraphStorm routinely outputs the metric imply reciprocal rank (MRR). MRR is a beneficial metric for evaluating graph hyperlink prediction fashions as a result of it assesses how excessive the precise hyperlinks are ranked among the many predicted hyperlinks. This captures the standard of predictions, ensuring our mannequin appropriately prioritizes true connections, which is our goal right here.
You possibly can run inference with one command line, as proven within the following code. On this case, the mannequin reaches an MRR of 0.31 on the check set of the constructed graph.
Observe that the inference pipeline generates embeddings from the hyperlink prediction mannequin. To resolve the issue of discovering the sector of research for any given paper, merely carry out a k-nearest neighbor search on the embeddings.
Conclusion
GraphStorm is a brand new graph ML framework that makes it straightforward to construct, prepare, and deploy graph ML fashions on trade graphs. It addresses some key challenges in graph ML, together with scalability and usefulness. It gives built-in parts to course of billion-scale graphs from uncooked enter information to mannequin coaching and mannequin inference and has enabled a number of Amazon groups to coach state-of-the-art graph ML fashions in numerous purposes. Try our GitHub repository for extra data.
Concerning the Authors
 Da Zheng is a senior utilized scientist at AWS AI/ML analysis main a graph machine studying workforce to develop strategies and frameworks to place graph machine studying in manufacturing. Da bought his PhD in pc science from the Johns Hopkins College.
Da Zheng is a senior utilized scientist at AWS AI/ML analysis main a graph machine studying workforce to develop strategies and frameworks to place graph machine studying in manufacturing. Da bought his PhD in pc science from the Johns Hopkins College.
 Florian Saupe is a Principal Technical Product Supervisor at AWS AI/ML analysis supporting superior science groups just like the graph machine studying group and enhancing merchandise like Amazon DataZone with ML capabilities. Earlier than becoming a member of AWS, Florian lead technical product administration for automated driving at Bosch, was a technique advisor at McKinsey & Firm, and labored as a management techniques/robotics scientist – a area through which he holds a phd.
Florian Saupe is a Principal Technical Product Supervisor at AWS AI/ML analysis supporting superior science groups just like the graph machine studying group and enhancing merchandise like Amazon DataZone with ML capabilities. Earlier than becoming a member of AWS, Florian lead technical product administration for automated driving at Bosch, was a technique advisor at McKinsey & Firm, and labored as a management techniques/robotics scientist – a area through which he holds a phd.



