Scaling Generative Retrieval: Google Analysis and College of Waterloo’s Empirical Research on Generative Retrieval Throughout Numerous Corpus Scales, Together with a Deep Dive into the 8.8M-Passage MS MARCO Job
In a revolutionary leap ahead, generative retrieval approaches have emerged as a disruptive paradigm in info retrieval strategies. Harnessing the potential of superior sequence-to-sequence Transformer fashions, these approaches intention to rework how we retrieve info from huge doc corpora. Historically restricted to smaller datasets, a latest groundbreaking examine titled “How Does Generative Retrieval Scale to Millions of Passages?” performed by a crew of researchers from Google Analysis and the College of Waterloo, delves into the uncharted territory of scaling generative retrieval to total doc collections comprising thousands and thousands of passages.
Generative retrieval approaches strategy the data retrieval job as a unified sequence-to-sequence mannequin that instantly maps queries to related doc identifiers utilizing the revolutionary Differentiable Search Index (DSI). By way of indexing and retrieval, DSI learns to generate doc identifiers based mostly on their content material or pertinent queries in the course of the coaching stage. Throughout inference, it processes a question and presents retrieval outcomes as a ranked checklist of identifiers.
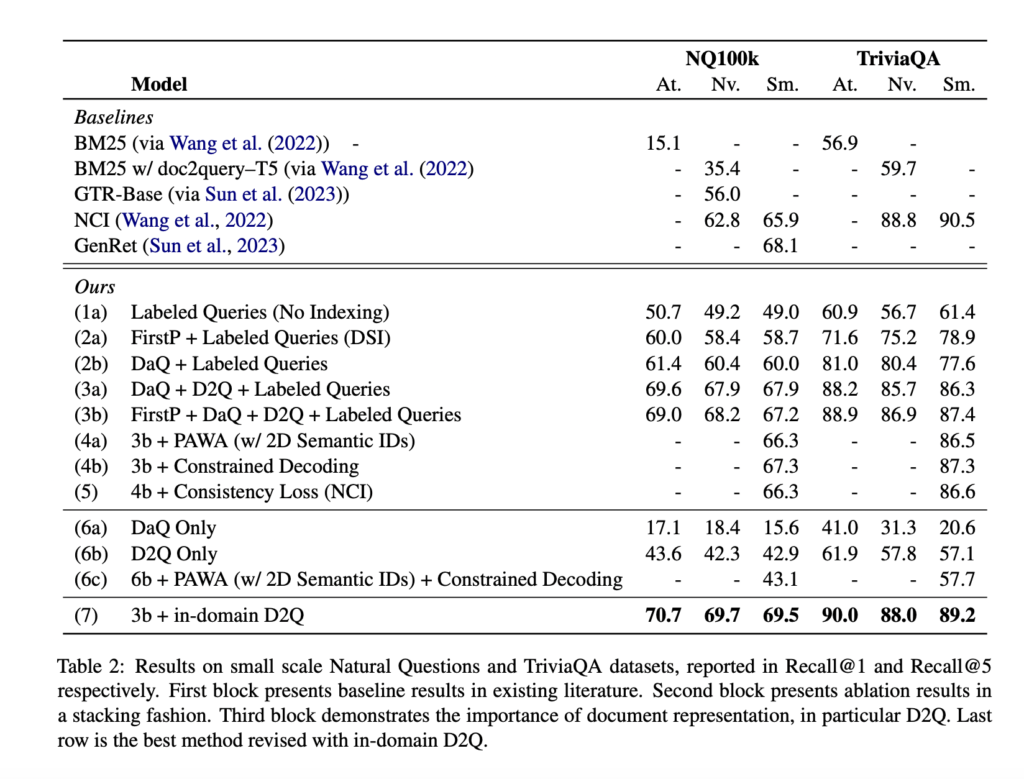
The researchers launched into a journey to discover the scalability of generative retrieval, scrutinizing varied design selections for doc representations and identifiers. They make clear the challenges posed by the hole between the index and retrieval duties and the protection hole. The examine highlights 4 varieties of doc identifiers: unstructured atomic identifiers (Atomic IDs), naive string identifiers (Naive IDs), semantically structured identifiers (Semantic IDs), and the revolutionary 2D Semantic IDs. Moreover, three essential mannequin parts are reviewed: Prefix-Conscious Weight-Adaptive Decoder (PAWA), Constrained decoding, and Consistency loss.
With the final word purpose of evaluating generative retrieval fashions on a colossal corpus, the researchers centered on the MS MARCO passage rating job. This job introduced a monumental problem, because the corpus contained 8.8 million passages. Undeterred, the crew pushed the boundaries by exploring mannequin sizes that reached 11 billion parameters. The outcomes of their arduous endeavor led to a number of important findings.
Initially, the examine revealed that artificial question era emerged as essentially the most crucial part because the corpus dimension expanded. With bigger corpora, producing life like and contextually acceptable queries grew to become paramount to the success of generative retrieval. The researchers emphasised the significance of contemplating the compute value of dealing with such large datasets. The computational calls for positioned on techniques necessitate cautious consideration and optimization to make sure environment friendly and cost-effective scaling.
Furthermore, the examine affirmed that rising mannequin dimension is crucial for enhancing the effectiveness of generative retrieval. Because the mannequin grows extra expansive, its capability to understand and interpret huge quantities of textual info turns into extra refined, leading to improved retrieval efficiency.
This pioneering work supplies invaluable insights into the scalability of generative retrieval, opening up a realm of potentialities for leveraging massive language fashions and their scaling energy to bolster generative retrieval on mammoth corpora. Whereas the examine addressed quite a few crucial points, it additionally unearthed new questions that may form the way forward for this subject.
Wanting forward, the researchers acknowledge the necessity for continued exploration, together with the optimization of huge language fashions for generative retrieval, additional refinement of question era strategies, and revolutionary approaches to maximise effectivity and cut back computational prices.
In conclusion, the outstanding examine performed by Google Analysis and the College of Waterloo crew showcases the potential of generative retrieval at an unprecedented scale. By unraveling the intricacies of scaling generative retrieval to thousands and thousands of passages, they’ve paved the way in which for future developments that promise to revolutionize info retrieval and form the panorama of large-scale doc processing.
Test Out The Paper. Don’t neglect to hitch our 23k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI tasks, and extra. When you’ve got any questions concerning the above article or if we missed something, be at liberty to e mail us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club

Niharika is a Technical consulting intern at Marktechpost. She is a 3rd 12 months undergraduate, at the moment pursuing her B.Tech from Indian Institute of Expertise(IIT), Kharagpur. She is a extremely enthusiastic particular person with a eager curiosity in Machine studying, Knowledge science and AI and an avid reader of the most recent developments in these fields.